介绍
个人在学习Rust过程中的一些笔记记录:
- Rust语法基础
- Rust算法刷题
- …..
参考的资料有:
Rust学习
学习笔记中可能由于编译器的更新,一些地方可能与现在不一致。
2024年12月31日
基础语法
变量
在 Rust 中,变量的处理方式与其他编程语言(如 Python 或 Java)有很大不同。其核心设计理念是安全性和内存管理。
以下是关于 Rust 变量的核心知识点:
变量绑定
在很多编程语言中,我们会说“给变量赋值”。但在 Rust 中,官方术语通常是 “变量绑定” (Variable Binding) 。
- 语法 :
let x = 5; - 核心逻辑 :这个语句意味着我们将名字
x与值5绑定在一起。 - 为什么叫“绑定”?
- 模式匹配 :
let关键字后面跟着的实际上是一个 模式 (Pattern) 。例如,你可以这样写:let (a, b) = (1, 2);。这里 Rust 会把元组中的值分别绑定到a和b上。 - 所有权控制 :绑定不仅仅是内存地址的赋值,它还涉及到 Rust 核心的所有权 (Ownership) 系统。当一个值绑定到一个变量名时,这个变量名就“拥有”了这个值。
- 模式匹配 :
使用下划线忽略未使用的变量
Rust 编译器非常注重代码的整洁。如果声明了一个变量但从未使用过它,编译器会报出警告(Warning),认为这可能是代码逻辑上的疏忽。
A. 使用 _ (纯下划线)
如果你完全不关心某个值,可以使用 _。它会立即丢弃该值,不会进行任何绑定。
fn main() {
let _ = 5; // 值被直接丢弃, 不绑定到任何名字, 你之后无法通过任何名字访问这个 5
let _ = some_function_returns_result(); // 我调用了函数,但我不在乎返回值
}
fn some_function_returns_result() -> i32 {
42
}B. 使用下划线开头 (如 _x)
如果你想保留这个变量(可能为了调试或者为了以后扩展),但现在暂时不用,又不希望看到编译器的警告,可以在变量名前加一个下划线。
fn main() {
let x = 5; // ⚠️ 编译器会警告:unused variable: `x`
let _y = 10; // ✅ 编译器会保持沉默,因为它看到了下划线前缀
}cargo run:
#![allow(unused)]
fn main() {
warning: unused variable: `y`
--> src/main.rs:3:9
|
3 | let y = 10;
| ^ help: 如果 y 故意不被使用,请添加一个下划线前缀: `_y`
|
= note: `#[warn(unused_variables)]` on by default
}不可变性
在 Rust 中,变量默认是不可变的。一旦你为一个变量绑定了值,就不能再修改它。
fn main() {
let x = 5;
x = 6; // ❌ 编译错误!不能对不可变变量二次赋值
}为什么要这样做?
通过默认不可变,Rust 保证了数据的安全性。在多线程环境下,你可以确信一个变量的值不会在你不注意的时候被其他代码修改。
可变变量
如果你需要修改某个变量,必须显式地加上 mut 关键字。
fn main() {
let mut x = 5;
println!("x 的值是: {}", x);
x = 6; // ✅ 允许修改
println!("现在 x 的值是: {}", x);
}变量遮蔽
Rust 允许你声明一个与现有变量同名的新变量。这被称为“遮蔽”。
fn main() {
let x = 5;
let x = x + 1; // 遮蔽了之前的 x
{
let x = x * 2; // 在当前作用域内再次遮蔽
println!("内部作用域中 x 的值: {}", x); // 12
}
println!("外部作用域中 x 的值: {}", x); // 6
}
遮蔽与 mut 的区别:
- 类型转换:使用
let遮蔽时,你可以改变变量的类型(例如从字符串变为数字),而mut变量的类型是固定的。 - 重新锁定:遮蔽后,新变量如果没有
mut,它依然是不可变的。
常量
常量类似于不可变变量,但有严格的区别:
- 使用
const关键字。 - 必须显式注明类型(例如
i32)。 - 可以在任何作用域声明(包括全局)。
- 只能赋值为“常量表达式”,不能是函数调用的结果或运行时计算的值。
const THREE_HOURS_IN_SECONDS: u32 = 60 * 60 * 3;
fn main() {
println!("三小时的秒数: {}", THREE_HOURS_IN_SECONDS);
}作用域
变量在 Rust 中是“块级作用域”的。变量在声明的大括号 {} 内有效,超出范围后,变量会被释放 (Drop)。
fn main() {
let s = "hello"; // s 进入作用域
{
let x = 10; // x 进入作用域
} // x 在这里失效并释放
println!("s 的值是: {}", s); // ✅ 可以访问 s
} // s 在这里失效并释放
数据类型
1. 标量类型(Scalar Types)
标量类型代表一个单一的值。
A. 整数类型 (Integers)
Rust 提供了非常精细的整数控制,分为有符号(i)和无符号(u)。
| 长度 | 有符号 (Signed) | 无符号 (Unsigned) | 范围 (n 为位数) |
|---|---|---|---|
| 8-bit | i8 | u8 | i8: -(2^(8-1)) ~ 2^(8-1)-1,u8: 0 ~ 2^8-1 |
| 16-bit | i16 | u16 | i16: -(2^(16-1)) ~2^(16-1)-1,u16: 0 ~2^16-1 |
| 32-bit | i32 (默认) | u32 | i32: -(2^(32-1)) ~2^(32-1)-1,u32: 0 ~ 2^32-1 |
| 64-bit | i64 | u64 | i64: -(2^(64-1)) ~2^(64-1)-1,u64: 0 ~ 2^64-1 |
| 128-bit | i128 | u128 | i128:-(2^(128-1)) ~2^(128-1)-1,u128: 0 ~ 2^128-1 |
| arch (平台相关) | isize | usize | 取决于计算机架构 (64位或32位) |
-
usize/isize的用途:常用于集合索引、切片范围、长度(如len())、以及与内存地址大小相关的场景。 -
整数字面值:可以使用
_分隔增强可读性,如1_000_000。支持0x(十六进制)、0o(八进制)、0b(二进制)。 -
类型后缀:可在字面量后加后缀明确类型,如
10u8、20i64。 -
溢出行为:
- debug 构建:整数溢出会触发
panic! - release 构建:默认按补码进行回绕(wrapping)
- 常见策略方法:
wrapping_add、checked_add、overflowing_add、saturating_add
- debug 构建:整数溢出会触发
fn main() {
let a: u8 = 250;
assert_eq!(a.wrapping_add(10), 4);
assert_eq!(a.checked_add(10), None);
}B. 浮点类型 (Floating-Point)
Rust 遵循 IEEE-754 标准:
f32:单精度。f64:双精度(默认,因为在现代 CPU 上速度几乎与f32一样快,但精度更高)。
浮点数相关注意点:
- 精度误差:尽量避免直接用
==比较业务浮点值,常用误差范围比较。 - NaN:
NaN != NaN,这会影响比较与排序逻辑。
fn main() {
let x = 0.1f64 + 0.2;
assert!((x - 0.3).abs() < 1e-10);
}C. 布尔与字符
bool:true和false。通常占用 1 个字节。char:占用 4 个字节,代表一个 Unicode 标量值,可以表示中文、日文、表情符号 (Emoji) 等。char不是 UTF-8 的“一个字节”,也不等同于字符串的长度单位。
2. 复合类型 (Compound Types)
将多个值组合成一个类型。
A. 元组 (Tuple)
- 特点:长度固定,各元素类型可以不同。
- 定义:
let tup: (i32, f64, u8) = (500, 6.4, 1); - 访问:使用点号,如
tup.0。 - 解构:可用模式匹配直接拆开。
fn main() {
let tup: (i32, f64, u8) = (500, 6.4, 1);
let (x, y, z) = tup;
}- 单元类型
():不包含任何值的元组,常作为表达式的默认返回值或占位类型。
B. 数组 (Array)
- 特点:长度固定,各元素类型必须相同。
- 定义:
let a = [1, 2, 3, 4, 5]; - 类型与长度声明:
let a: [i32; 5] = [1, 2, 3, 4, 5]; - 重复初始化:
let a = [0u8; 1024]; - 存储:数组是固定大小的值类型,作为局部变量时通常位于栈上;若被
Box等包裹,则数据会位于堆上。
数组访问与边界:
a[i]:越界会panic!a.get(i):返回Option<&T>,更安全
fn main() {
let a = [1, 2, 3];
assert_eq!(a.get(10), None);
}3. 序列与字符串 (Sequences & Strings)
这一部分常见困惑点集中在 UTF-8 与内存分配方式。
A. 字符串 (Strings)
Rust 核心语言层面有 str(动态大小类型,通常以引用切片 &str 出现),标准库提供可增长的 String。
String:拥有所有权,数据在堆上,可增长。内部包含指针、长度、容量等信息。&str:字符串切片,是对一段 UTF-8 字节序列的借用视图。引用本身在栈上,实际数据可能来自只读区(字符串字面量)、栈或堆。
常见转换:
fn main() {
let s1: String = "hello".to_string();
let s2: &str = &s1; // &String 自动解引用成 &str
let s3: String = s2.to_owned(); // 或 s2.to_string()
}字符串索引与切片规则:
- Rust 不支持
s[0]直接索引字符,因为 UTF-8 下“字符边界”与字节下标不总一致。 &s[a..b]必须落在 UTF-8 字符边界,否则运行时会panic!。
fn main() {
let s = "中文";
let ok = &s[0..3]; // "中" 占 3 个字节
}B. 切片 (Slices)
切片引用连续的一段序列,而不是整个集合。
- 数组/向量切片:
&[T] - 字符串切片:
&str(本质上也是切片)
示例:
fn main() {
let a = [10, 20, 30, 40, 50];
let slice = &a[1..3]; // &[20, 30]
}切片是一种“胖指针”,通常包含地址与长度信息,因此可以安全地携带边界。
4. 标准库集合 (Standard Collections)
虽然属于标准库,但它们在实际开发中几乎被当作基础类型使用。
A. Vec<T> (Vector)
- 动态数组,在堆上分配,可扩容。
- 常见 API:
push、pop、len、capacity、get、切片&v[a..b]等。 - 预分配容量:
Vec::with_capacity(n)可减少扩容次数。
fn main() {
let mut v = Vec::new();
v.push(1);
v.extend([2, 3, 4]);
println!("{:?}", v);
let first = v.get(0); // Option<&i32>
let part = &v[1..3]; // &[i32]
println!("{:?}", part);
}B. HashMap<K, V>
- 键值对映射结构。
- 常用
entry模式在“插入或更新”时更方便。
fn main() {
use std::collections::HashMap;
let mut m = HashMap::new();
m.insert("a", 1);
println!("{:?}", m);
*m.entry("a").or_insert(0) += 1;
println!("{:?}", m);
}5. 特殊/底层类型
A. 枚举 (Enums)
枚举用于表示“一组有限的可能取值”。Rust 的枚举非常强大:每个变体(variant)不仅能表示不同分支,还能携带不同类型的数据,因此很适合用来建模状态机、协议消息、错误类型等。
- 基本定义与使用
enum Direction {
Up,
Down,
Left,
Right,
}
fn move_step(d: Direction) {
match d {
Direction::Up => println!("up"),
Direction::Down => println!("down"),
Direction::Left => println!("left"),
Direction::Right => println!("right"),
}
}
fn main() {
let d = Direction::Up;
move_step(d);
}2)变体携带数据
枚举变体可以携带数据,且不同变体携带的数据类型可以不同:
enum Message {
Quit,
Move { x: i32, y: i32 }, // 结构体风格
Write(String), // 元组风格
}
fn main() {
let m1 = Message::Quit;
let m2 = Message::Move { x: 3, y: 4 };
let m3 = Message::Write("hi".to_string());
}
B. 结构体 (Structs)
结构体用于把多个字段组合成一个自定义类型,是“组织数据”的核心方式之一。
- 具名字段结构体(最常用)
struct User {
name: String,
age: u8,
active: bool,
}
fn main() {
let u = User {
name: "Alice".to_string(),
age: 18,
active: true,
};
//访问字段用点号:
println!("{:?}", u.name);
}2)结构体与所有权的直观规则
字段类型如果是 String、Vec <T> 等“拥有型”,把结构体赋值给新变量时默认会发生移动(move)。
想继续使用旧值通常需要借用(&User)或让字段可复制(如 u32)或显式 clone()。
struct User {
name: String,
age: u8,
active: bool,
}
fn main() {
let u1 = User { name: "A".to_string(), age: 1, active: true };
let u2 = u1; // u1 被 move
// println!("{}", u1.age); // 不能用
println!("{}", u2.age);
}C. 指针类型(Pointer Types)
根据底层的表现形式和抽象程度,可以将 Rust 的指针分为以下四大类:
1. 引用 (References) —— 最常用的指针
引用是 Rust 中最常见的指针形式,它们在底层表现为指向某个内存地址的指针。
&T(不可变引用) :指向类型为T的值,允许读取数据但不能修改。&mut T(可变引用) :允许读取并修改指向的数据。- 内存表现 :
- 普通引用 :对于已知大小的类型(如
i32),它是单字长的指针。 - 切片引用(胖指针) :对于动态大小类型(如
&str或&[T]),它由指针和长度组成,占用两个字长。
- 普通引用 :对于已知大小的类型(如
2. 原生指针 (Raw Pointers) —— 绕过安全的底层指针
原生指针与 C 语言的指针非常相似。它们在语法上定义为 *const T 和 *mut T。
- 特点 :
- 允许忽略借用规则,可以同时拥有多个指向同一位置的可变和不可变指针。
- 不保证指向有效的内存,且允许为
null。 - 安全性 :解引用原生指针是不安全的,必须放在
unsafe块中执行。
- 用途 :主要用于与 C 语言交互(FFI)或编写底层高性能驱动。
fn main() {
let mut num = 5;
// 1. 从引用创建原生指针
// 虽然创建原生指针是安全的,但后续使用是不安全的
let r1 = &num as *const i32; // 不可变原生指针
let r2 = &mut num as *mut i32; // 可变原生指针
// 2. 解引用原生指针
// 必须放在 unsafe 块中,否则编译器会报错
unsafe {
println!("r1 指向的值: {}", *r1);
// 修改原生指针指向的数据
*r2 = 10;
println!("修改后 r2 指向的值: {}", *r2);
}
// 3. 创建一个指向任意内存地址的指针(慎用!)
let address = 0x012345usize;
let _r3 = address as *const i32;
}3. 函数指针 (fn Pointer) —— 代码地址的载体
函数指针指向的是代码段中的函数入口地址,而不是堆栈上的数据。
- 语法 :类型写作
fn(参数类型) -> 返回类型。 - 区别于闭包 :
- 函数指针不捕获环境变量。
- 它的长度始终是一个字长(存储地址)。
- 它可以作为参数传递给其他函数,或者存储在数据结构中。
fn add_one(x: i32) -> i32 {
x + 1
}
fn do_twice(f: fn(i32) -> i32, arg: i32) -> i32 {
// 像正常函数一样通过指针调用
f(arg) + f(arg)
}
fn main() {
// 将函数名 add_one 隐式转换为函数指针类型
let f: fn(i32) -> i32 = add_one;
let answer = do_twice(f, 5);
println!("计算结果为: {}", answer); // 输出: 12
// 函数指针的大小验证
println!("函数指针的大小: {} 字节", std::mem::size_of_val(&f));
}4. 智能指针 (Smart Pointers) —— 携带元数据的指针
智能指针是拥有数据所有权的结构体,它们实现了 Deref 和 Drop 特性。
A. Box<T> (堆空间分配)
- 功能 :在堆上分配空间存储类型为
T的值,并在栈上保留指针。 - 场景 :当数据大小在编译时未知(如递归类型),或数据量巨大不适合在栈上拷贝时使用。
B. Rc<T> (引用计数指针)
- 功能 :全称 Reference Counting,允许多个变量通过增加计数来共享同一个堆数据的所有权。
- 场景 :用于单线程环境下,需要一个数据有多个所有者的复杂逻辑(如树或图的节点共享)。
C. Arc<T> (原子引用计数指针)
- 功能 :Atomic Reference Counting,是
Rc<T>的线程安全版本。 - 场景 :多线程并发环境下,安全地共享同一份数据的所有权。
总结对比表
| 指针类型 | 语法表示 | 内存位置 | 长度(64位) | 核心特性 |
|---|---|---|---|---|
| 引用 | &T/&mut T | 栈/堆 | 8 或 16 字节 | 安全借用,编译器检查生命周期 |
| 原生指针 | *const T/*mut T | 栈/堆 | 8 字节 | 不安全,类似 C 指针 |
| 函数指针 | fn(...) -> ... | 代码段 | 8 字节 | 指向函数地址 |
| 智能指针 | Box<T>/Rc<T> | 堆 | 8 字节 | 管理堆内存,提供自动清理逻辑 |
D. Option<T> 与 Result<T, E>
Rust 不提供 null,用 Option<T> 表示“可能不存在”。
fn main() {
let x: Option<i32> = Some(1);
let y: Option<i32> = None;
}错误处理通常用 Result<T, E>:
fn parse(s: &str) -> Result<i32, std::num::ParseIntError> {
s.parse()
}
fn main() {
let result = parse("123");
println!("{:?}", result);
}E. Never 类型 (!)
! 表示永远不会返回的类型,常见于 panic!、无限循环等。
#![allow(unused)]
fn main() {
fn forever() -> ! {
loop {}
}
}6. 类型转换注意
Rust 不会进行隐式类型转换。不同整数类型之间的转换必须显式完成。
fn main() {
let a: u8 = 10;
let b: u32 = a as u32;
}as 转换在整数之间可能发生截断或符号变化。需要“转换失败就返回错误/None”时可用 TryFrom/TryInto。
fn main() {
use std::convert::TryFrom;
let x: i32 = 300;
let y = u8::try_from(x); // Err(...)
}注释和打印
在 Rust 中,注释是写给程序员看的“备忘录”,而打印则是程序与外界沟通的最基本方式。理解这两者能极大地提升开发和调试效率。
一、 注释 (Comments)
Rust 支持多种注释风格,除了代码解释外,Rust 的注释还深度集成了文档生成工具 cargo doc。
1. 常规注释
- 单行注释 :使用
//,这是最常用的注释方式。 - 块注释 (多行) :使用
/* ... */。虽然 Rust 支持,但社区更倾向于在多行也使用单行注释。
fn main() {
// 这是一个单行注释
let x = 5; // 也可以在代码行末尾
/* 这是一个块注释
它可以跨越多行 */
let y = 10;
}2. 文档注释 (Doc Comments)
这是 Rust 的特色,用于生成 HTML 格式的 API 文档。
- 三斜杠
///:为紧随其后的 项目 (如函数、结构体)生成文档。支持 Markdown 语法。 - 双斜杠感叹号
//!:为包含该注释的 条目 (如整个 crate 或模块)生成文档。
//! # 核心逻辑模块
//! 这个模块包含了一些数学运算函数。
/// 将两个数字相加。
///
/// # Examples
/// ```
/// let res = add(1, 2);
/// ```
fn add(a: i32, b: i32) -> i32 {
a + b
}在文档章节会详细介绍文档注释的使用方法和注意事项。
二、 打印 (Printing)
Rust 的打印是通过一组宏 (Macros) 来实现的。宏的显著特征是名称末尾带有感叹号 !。
1. 核心宏
| 宏名称 | 功能描述 |
|---|---|
print! | 打印到标准输出,不换行。 |
println! | 打印到标准输出,自动换行 。 |
format! | 不打印,而是返回一个格式化后的 String。 |
eprintln! | 打印到标准错误输出 (stderr) ,常用于打印错误信息。 |
2. 占位符
参数位置与命名
除了按顺序匹配,你还可以通过索引或名称来复用变量。
fn main() {
let name = "Alice";
let age = 30;
// 按顺序匹配
println!("{} is {} years old.", name, age); // Alice is 30 years old.
// 索引匹配
println!("{0} is {1} years old.", name, age); // Alice is 30 years old.
// 具名匹配
println!("{name} is {age} years old."); // Alice is 30 years old.
}格式化占位符核心语法
下表总结了占位符 {} 内部可以使用的所有核心语法:
| 类别 | 语法示例 | 效果描述 | 42或“Hi“为例 |
|---|---|---|---|
| 基础展示 | {} | 调用 Display 特征,普通人类可读输出。 | 42 |
{:?} | 调用 Debug 特征,程序员调试用输出。 | 42 | |
{:#?} | 漂亮打印 (Pretty Print),多行缩进展示复杂结构。 | (分行显示的结构) | |
| 参数索引 | {0} | 使用第 1 个位置参数(索引从 0 开始)。 | 42 |
{name} | 使用具名参数。 | Hi | |
| 对齐与填充 | {:10} | 设置宽度为 10,默认左对齐(字符串)或右对齐(数字)。 | "Hi " |
{:<10} | 强制左对齐。 | "Hi " | |
{:>10} | 强制右对齐。 | " Hi" | |
{:^10} | 强制居中对齐。 | " Hi " | |
{:*^10} | 使用 * 进行填充(填充字符必须在对齐符号前)。 | "****Hi****" | |
| 数字进制 | {:b} | 转换为二进制 (Binary)。 | 101010 |
{:o} | 转换为八进制 (Octal)。 | 52 | |
{:x} / {:X} | 转换为十六进制 (Hex),大小写决定字母大小写。 | 2a / 2A | |
{:#x} | 带有进制前缀的十六进制。 | 0x2a | |
| 精度与正负 | {:.2} | 浮点数保留 2 位小数。 | 3.14 |
{:+.2} | 强制显示正负号。 | +42.00 | |
{:05} | 宽度为 5,不足部分用 0 填充。 | 00042 | |
| 特殊指针 | {:p} | 打印内存地址(适用于引用或原生指针)。 | 0x7ffee1234567 |
| 转义 | {{ / }} | 在格式化字符串中显示原始的大括号。 | { / } |
为了更直观地理解如何组合这些选项,请看下面的综合实例:
use std::mem::size_of;
#[derive(Debug)]
struct Point { x: i32, y: i32 }
fn main() {
let p = Point { x: 10, y: 20 };
let pi = 3.14159;
// 1. 组合:宽度、对齐、填充、精度
// 效果:居中对齐,宽度10,用'-'填充,保留2位小数
println!("数值展示: {:*^10.2}", pi);
// 2. 指针地址展示
// 使用 :p 查看变量在栈上的地址
let r = &p;
println!("结构体 p 的地址: {:p}", r);
// 3. 进制与前缀
let val = 255;
println!("十六进制: {:#X}, 二进制: {:b}", val, val);
// 4. 调试复杂结构
// 使用 {:#?} 实现易读的缩进输出
println!("漂亮打印结构体: {:#?}", p);
}💡 核心知识点补充
- **
DebugvsDisplay**:几乎所有的 Rust 标准库类型都实现了Debug(用于调试),但并非都实现了Display(因为某些类型没有唯一的人类可读展示方式)。 - 指针长度:在 64 位系统上,使用
{:p}打印出的地址通常对应一个 8 字节(单字长)的内存位置。 - 内存效率:所有的
print!系列宏在编译时都会被检查。如果占位符数量与参数不匹配,编译器会直接报错,这保证了运行时的类型安全。
结构化调试打印
- 派生 Debug: 使用
#[derive(Debug)]注解结构体或枚举,自动生成 Debug 实现。{:?}:以调试模式打印(需要类型实现std::fmt::Debug)。{:#?}: 美化打印 ,会自动分行并添加缩进,适合查看大型结构体。
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect = Rectangle { width: 30, height: 50 };
println!("rect 是 {:?}", rect); // 输出: rect 是 Rectangle { width: 30, height: 50 }
println!("rect 是 {:#?}", rect); // 美化输出,多行缩进
}- 手动实现 Debug: 如果需要自定义格式,实现 std::fmt::Debug trait
use std::fmt;
struct Point {
x: i32,
y: i32,
}
impl fmt::Debug for Point {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
f.debug_struct("Point")
.field("x", &self.x)
.field("y", &self.y)
.finish()
}
}
fn main() {
let p = Point { x: 1, y: 2 };
println!("{:?}", p); // 输出: Point { x: 1, y: 2 }
}- Debug vs Display:
- Debug:用于开发者,格式如 { x: 1, y: 2 },通过 {:?}。
- Display:用于用户友好输出,通过 {}。需手动实现 std::fmt::Display。
impl fmt::Display for Point {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
write!(f, "({}, {})", self.x, self.y)
}
}
println!("{}", p); // 输出: (1, 2)3. dbg宏
dbg! 宏用于调试,它打印表达式的值和源代码位置,然后返回该值。适合插入代码中快速检查,而不中断流程。
- 语法:
- dbg!(表达式);:打印表达式的文件名、行号、列号和值,返回表达式本身。
- 支持借用(&),避免所有权转移。
#[derive(Debug)] // 使用 dbg! 要求类型必须实现 Debug 特征
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect = Rectangle { width: 30, height: 50 };
// 1. println! 的方式:必须单独写一行,且需要手动写描述
println!("矩形的数据是: {:?}", rect);
// 2. dbg! 的方式:直接包裹表达式
// 它会打印:[src\main.rs:12:5] rect = Rectangle { width: 30, height: 50 }
dbg!(&rect);
// 3. 嵌套使用(逻辑不中断)
let area = dbg!(rect.width * rect.height); // 打印计算过程并把结果赋给 area
println!("面积是: {}", area);
}-
与结构体结合: dbg! 使用 Debug trait,如果结构体未实现 Debug,会编译错误。
-
注意:dbg! 只在调试构建中有效,在发布模式下可能被优化掉。输出到 stderr,便于区分正常输出。
dbg! 与 println! 的详细对比
| 特性 | println! | dbg! |
|---|---|---|
| 输出目标 | 标准输出 (stdout) | 标准错误 (stderr) |
| 占位符要求 | 必须手动写 {} 或 {:?} | 自动调用 {:?} |
| 信息量 | 仅打印你指定的内容 | 自动包含文件名、行号、表达式 |
| 返回值 | 返回单元类型 () | 返回表达式的值(所有权转移) |
| 典型用途 | 最终程序输出给用户看 | 开发过程中快速排查问题 |
所有权和借用
所有权(Ownership)是 Rust 最为独特且核心的特性。它让 Rust 能够脱离垃圾回收(GC)机制,在编译期即确保内存安全。
一、 内存管理的三大流派
在计算机科学中,管理内存通常有三种方式:
- 垃圾回收 (GC) :如 Java、Go、Python。程序运行时自动寻找不再使用的内存。优点是开发快,缺点是运行时开销大,可能出现“停顿”。
- 手动管理 :如 C/C++。程序员手动调用
malloc/free。优点是极致性能,缺点是极其容易出现 悬空指针 、双重释放或 内存泄漏 。 - 所有权系统 :Rust 的路径。通过编译器在编译时根据一套规则检查内存管理。 零运行时开销 。
预备知识:栈 (Stack) 与 堆 (Heap)
栈
栈按照顺序存储值并以相反顺序取出值,这也被称作 后进先出 。想象一下一叠盘子:当增加更多盘子时,把它们放在盘子堆的顶部,当需要盘子时,再从顶部拿走。不能从中间也不能从底部增加或拿走盘子!
增加数据叫做 进栈 ,移出数据则叫做 出栈 。
因为上述的实现方式,栈中的所有数据都必须占用已知且固定大小的内存空间,假设数据大小是未知的,那么在取出数据时,你将无法取到你想要的数据。
堆
与栈不同,对于大小未知或者可能变化的数据,我们需要将它存储在堆上。
当向堆上放入数据时,需要请求一定大小的内存空间。操作系统在堆的某处找到一块足够大的空位,把它标记为已使用,并返回一个表示该位置地址的 指针 ,该过程被称为 在堆上分配内存 ,有时简称为 “分配”(allocating)。
接着,该指针会被推入栈中,因为指针的大小是已知且固定的,在后续使用过程中,你将通过栈中的 指针 ,来获取数据在堆上的实际内存位置,进而访问该数据。
由上可知,堆是一种缺乏组织的数据结构。想象一下去餐馆就座吃饭:进入餐馆,告知服务员有几个人,然后服务员找到一个够大的空桌子(堆上分配的内存空间)并领你们过去。如果有人来迟了,他们也可以通过桌号(栈上的指针)来找到你们坐在哪。
性能区别
在栈上分配内存比在堆上分配内存要快,因为入栈时操作系统无需进行函数调用(或更慢的系统调用)来分配新的空间,只需要将新数据放入栈顶即可。相比之下,在堆上分配内存则需要更多的工作,这是因为操作系统必须首先找到一块足够存放数据的内存空间,接着做一些记录为下一次分配做准备,如果当前进程分配的内存页不足时,还需要进行系统调用来申请更多内存。 因此,处理器在栈上分配数据会比在堆上分配数据更加高效。
所有权与堆栈
当你的代码调用一个函数时,传递给函数的参数(包括可能指向堆上数据的指针和函数的局部变量)依次被压入栈中,当函数调用结束时,这些值将被从栈中按照相反的顺序依次移除。
因为堆上的数据缺乏组织,因此跟踪这些数据何时分配和释放是非常重要的,否则堆上的数据将产生内存泄漏 —— 这些数据将永远无法被回收。这就是 Rust 所有权系统为我们提供的强大保障。
对于其他很多编程语言,你确实无需理解堆栈的原理,但是 在 Rust 中,明白堆栈的原理,对于我们理解所有权的工作原理会有很大的帮助 。
二、 所有权
- 什么是所有权? :每个值都有一个“所有者”(owner),负责在值超出作用域时释放它。Rust 使用所有权来管理堆内存,而不依赖垃圾回收器。
- 为什么重要? :防止双重释放(double free)、使用后释放(use after free)和数据竞争。
- 三条铁律构建 :
每一个值都有一个变量,称为它的“所有者”
在 Rust 中,内存中的数据(值)不能孤立存在,必须绑定到一个变量上。
fn main() {
// 这个 String 字符串值在堆上创建
// 变量 s 成了这个字符串的“所有者”
let s = String::from("hello");
println!("s 拥有这个值: {}", s);
} // 函数结束,s 超出作用域,值被丢弃同一时间内,一个值只能有一个所有者
这是 Rust 安全性的核心。如果一个堆上的值有两个所有者,就会发生“二次释放”内存错误。因此,Rust 强制执行所有权移动(Move)。
fn main() {
let s1 = String::from("hello");
// 所有权从 s1 转移到了 s2
// 此时内存中仍然只有一个 "hello",但所有者变成了 s2
let s2 = s1;
// println!("{}", s1);
// ❌ 编译报错!s1 不再拥有该值,它已经“失效”了。
println!("现在所有权在 s2 手里: {}", s2);
}当所有者超出作用域时,该值将被丢弃(drop)
Rust 自动管理内存的秘诀就在这里:通过大括号 {} 定义作用域,一旦走出大括号,变量就会被销毁,内存立即回收。
fn main() {
{
// s 从这里开始有效
let s = String::from("hello");
println!("作用域内: {}", s);
}
// 💡 执行到这里,作用域结束。
// Rust 自动调用 `drop` 函数,释放 s 占用的堆内存。
// println!("{}", s);
// ❌ 编译报错!s 已经不在这里了,内存已经还给系统了。
}三、 变量交互:移动、克隆与复制
1. 移动 (Move)
对于存储在堆上的复杂类型(如 String),赋值操作默认是“移动”。为了防止 双重释放 ,Rust 会使原变量失效。
fn main() {
let s1 = String::from("hello");
let s2 = s1; // 所有权移动到了 s2,s1 此时已失效
// println!("{s1}"); // ❌ 编译错误:使用了已移动的值
println!("{s2}"); // ✅ 有效
}2. 克隆 (Clone) —— 深拷贝
如果你确实需要复制堆上的数据,必须显式调用 clone。
fn main() {
let s1 = String::from("hello");
let s2 = s1.clone(); // 在堆上产生了一份完整副本
println!("s1 = {s1}, s2 = {s2}"); // ✅ 两者均有效
}3. 复制 (Copy) —— 栈数据拷贝
对于简单、固定大小且完全存储在栈上的类型,Rust 会执行自动拷贝,而不会使原变量失效。常见的 Copy 类型包括:所有的整数、浮点数、布尔值、字符,以及只包含这些类型的元组。
fn main() {
let x = 5;
let y = x; // 栈数据直接拷贝,不涉及所有权转移
println!("x = {x}, y = {y}"); // ✅ 两者均有效
}四、 引用与借用 (References & Borrowing)
如果你不想转移所有权,但又想使用数据,就需要“借用”。引用(&)就像是现实中的借书:你可以看书,但书不属于你,看完得还。
1. 不可变借用 (&T)
你可以同时拥有多个不可变引用,因为“只读”不会引起数据竞争。
fn calculate_length(s: &String) -> usize {
s.len()
} // s 离开作用域,但因为它只是引用,所以不会发生 drop
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1); // 传入引用
println!("'{s1}' 的长度是 {len}"); // ✅ s1 依然有效
}2. 可变借用 (&mut T)
如果你需要修改借用的数据,必须使用可变引用。但它有极强的限制:在同一作用域内,特定数据只能有一个可变引用。
fn change(some_string: &mut String) {
some_string.push_str(", world");
}
fn main() {
let mut s = String::from("hello");
change(&mut s);
println!("{s}");
}3. 借用规则总结
为了彻底消除 数据竞争 ,Rust 强制执行以下规则:
- 在任何给定时间,你要么只能有一个可变引用,要么可以有任意数量的不可变引用。
- 引用必须始终有效(防止悬垂引用)。
五、 NLL:更智能的借用检查
在旧版 Rust 中,引用的作用域持续到大括号结束。现代 Rust 使用了 NLL (Non-Lexical Lifetimes) ,引用的作用域在最后一次使用处结束。这解决了许多“本该通过但没通过”的编译问题。
fn main() {
let mut s = String::from("hello");
let r1 = &s;
let r2 = &s;
println!("{r1} and {r2}");
// r1 和 r2 在此处之后不再使用,其作用域结束
let r3 = &mut s; // ✅ 允许,因为之前的不可变借用已失效
println!("{r3}");
}六、 悬垂引用 (Dangling References)
Rust 会在编译期阻止你返回局部变量的引用,因为局部变量在函数结束时会被释放。
// ❌ 无法通过编译
// fn dangle() -> &String {
// let s = String::from("hello");
// &s // 返回了对局部变量 s 的引用
// }
// ✅ 正确做法:直接返回 String (移动所有权)
fn no_dangle() -> String {
let s = String::from("hello");
s
}
fn main() {
let s = no_dangle();
}七、 自动释放:Drop 与 RAII
Rust 通过 Drop trait 实现 RAII (资源获取即初始化) 。当变量超出作用域时,Rust 自动调用 drop 方法释放堆内存。
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("正在清理数据: `{}`", self.data);
}
}
fn main() {
let c = CustomSmartPointer { data: String::from("my stuff") };
let d = CustomSmartPointer { data: String::from("other stuff") };
println!("CustomSmartPointers 已创建。");
} // 此处 d 先被 drop,然后 c 被 drop如何写出符合所有权的代码?
- 优先借用 :除非你确实需要获取数据的所有权(例如要把数据存入结构体中),否则优先使用引用
&T。 - 减少 Clone :如果发现代码里到处是
.clone(),通常说明所有权设计有误。 - 利用作用域 :可以通过手动添加
{ }来缩短变量或引用的生命周期,从而解决借用冲突。
语句与表达式
在 Rust 的设计哲学中,一切皆表达式是一个核心概念。理解语句Statements 与 表达式Expressions的区别,是掌握 Rust 函数返回值、控制流赋值以及函数式编程风格的关键。
一、基本定义
1. 语句 (Statements)
语句是执行某种操作但不返回值的指令。
- 在 Rust 中,最常见的语句是变量声明
let x = 5;。 - 语句通常以分号
;结尾。 - 注意 :因为语句不返回值,所以你不能把
let语句赋值给另一个变量(例如let x = (let y = 5);会报错)。
2. 表达式 (Expressions)
表达式会计算并产生一个 值 。
- 数学运算(如
5 + 6)、函数调用、宏调用都是表达式。 - 甚至大括号包裹的代码块
{}也是表达式。 - 核心规则 :表达式的结尾 没有分号 。如果你在表达式末尾加上分号,它就会变成一条语句,返回值会变成单元类型
()。
二、块表达式 (Block Expressions)
在 Rust 中,我们可以使用 {} 创建一个作用域,这个作用域本身就是一个表达式,它的值是其中最后一行表达式的值。
fn main() {
let y = {
let x = 3;
x + 1 // 注意:这里没有分号!
};
println!("y 的值是: {y}"); // 输出 4
}深度解析:
如果你在 x + 1 后面加了分号,变成 x + 1;,那么这个块就不再返回 4,而是返回 ()(unit 类型),编译器会因此报错(如果 y 预期是整数类型的话)。
三、函数中的应用:隐式返回
Rust 函数不需要显式写 return 关键字来返回值。只要函数体的最后一行是一个 表达式 (没有分号),该表达式的值就会自动作为函数的返回值。
fn add_one(x: i32) -> i32 {
x + 1 // 这是一个表达式,隐式返回其结果
}
fn main() {
let result = add_one(10);
println!("结果是: {result}");
}显式 return 与隐式返回的区别:
- 隐式返回 (不带
return和分号):Rust 推荐的标准写法,代码更简洁。 - 显式 return :通常用于函数中途提前退出(提前返回)。
fn check_number(n: i32) -> String {
if n < 0 {
return String::from("错误:负数"); // 提前退出
}
String::from("正常") // 隐式返回
}
fn main() {
let result = check_number(-10);
println!("检查结果: {result}");
}四、常见陷阱:分号的影响
分号在 Rust 中不仅仅是结束符,它是 类型的转换器 。它将一个“有值”的表达式转换成一个“无值”的语句。
| 示例 | 类别 | 结果/值 |
|---|---|---|
5 + 6 | 表达式 | 11 |
5 + 6; | 语句 | ()(Unit) |
let x = 5; | 语句 | 无值(报错不能被赋值) |
if true { 1 } else { 0 } | 表达式 | 1 |
五、综合示例:在一个函数中观察
下面的代码展示了如何在实际逻辑中混合使用语句和表达式:
fn main() {
let x = 5;
// 一个复杂的赋值表达式
let result = if x > 0 {
let temp = x * 2; // 语句
temp + 10 // 表达式:整个 if 块的值变为 20
} else {
0 // 表达式
};
println!("最终计算结果: {result}");
// 调用一个只有语句的函数
print_unit();
}
// 该函数没有返回值,或者说隐式返回 ()
fn print_unit() {
println!("我执行了一些操作,但我返回的是单元类型 ()");
// 这里其实隐藏了一个没有分号的 ()
}六、操作符优先级
在Rust中,一切皆表达式,那么了解表达式的优先级就非常重要了,将Rust的操作符和表达式按优先级由高到低的顺序列了出来,具有相同优先级的操作符按相关性给定的顺序进行优先级计算。
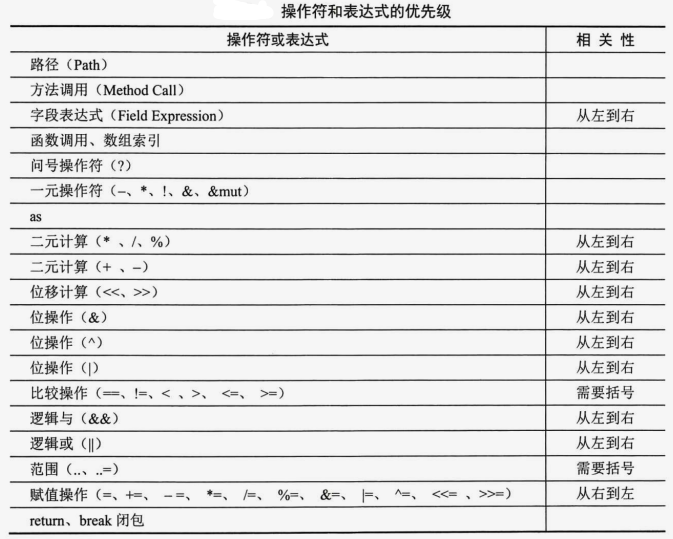
总结对比
| 特性 | 语句 (Statements) | 表达式 (Expressions) |
|---|---|---|
| 是否有分号 | 是 (通常以 ;结尾) | 否 (末尾无 ;) |
| 是否有返回值 | 否 (返回 ()) | 是 |
| 典型例子 | let x = 5; | x + 5/my_func() |
| 函数末尾 | 不会作为返回值 | 会自动作为返回值 |
条件语句
在 Rust 中,控制流和模式匹配不仅仅是逻辑的分叉口,它们更是安全性的守护者。Rust 编译器通过严格的类型检查和“穷尽性检查”,确保你在处理各种逻辑情况时不会留下漏洞。
以下是整理的 Rust 控制流、循环流与 match 表达式的详细指南。
一、控制流(Conditional Control Flow)
控制流是程序根据特定条件执行不同代码的能力。Rust 的 if 分支结构非常严谨。
1. if / else if / else
Rust 要求条件表达式必须是严格的 bool 类型。这意味着你不能像在 C 或 JavaScript 中那样使用数字(如 if (1))来代表逻辑真。这种设计避免了因隐式类型转换导致的逻辑错误。
fn main() {
let x = 10;
if x > 0 {
println!("positive");
} else if x == 0 {
println!("zero");
} else {
println!("negative");
}
}2. if 是表达式:可以返回值
在 Rust 中,if 是一个表达式而不是语句。这意味着它可以产生一个值,并将其直接赋值给变量。
注意:所有分支返回的数据类型必须完全一致,且分支末尾不要写分号,否则该分支会返回单元类型 ()。
fn main() {
let x = 7;
// if 表达式赋值
let y = if x % 2 == 0 { 100 } else { 200 };
// let y = if x % 2 == 0 { 100 } else { 200; };
println!("y 的值是: {y}"); // 输出 200
}3. if let:只关心某一种模式
当你只想处理某一种特定的模式(例如 Option 中的 Some),而对其他情况(如 None)不感兴趣时,if let 是比 match 更简洁的选择。它减少了样板代码的编写。
fn main() {
let v: Option<i32> = Some(10);
// 只解构 Some,忽略 None
if let Some(n) = v {
println!("解构成功,n = {n}");
} else {
println!("这里是 None 的情况");
}
}4. let else:模式不匹配就提前退出
这是 Rust 1.65 引入的新语法,非常适合编写“守护语句(Guard Statement)”。如果在解构时失败,必须在 else 块中通过 return、break 或 panic! 强制退出当前作用域。这使得后续代码可以放心地使用解构出来的变量。
fn parse_first(v: Vec<i32>) -> Option<i32> {
// 如果无法获取第一个元素,直接返回 None
let Some(first) = v.get(0) else {
return None;
};
// 此时 first 已经成功绑定,且作用域在外面
Some(*first)
}
fn main() {
let numbers = vec![1, 2, 3];
if let Some(val) = parse_first(numbers) {
println!("第一个值是: {val}");
}
}二、循环流(Looping Control Flow)
Rust 提供了三种循环原语,它们在底层性能上是一致的,但在语义表达上各有侧重。
1. loop:无限循环 + break 返回值
loop 常用于需要反复执行直到满足某个条件(如轮询任务或重试逻辑)的场景。由于 loop 保证一定会运行(直到被 break),它也可以作为表达式返回一个值。
fn main() {
let mut n = 0;
let result = loop {
n += 1;
if n == 5 {
break n * 2; // 带值跳出循环
}
};
println!("结果是: {result}"); // 10
}2. while:条件循环
这是最传统的循环方式,每次迭代开始前都会检查条件。适合处理那些依赖外部状态变化的逻辑。
fn main() {
let mut n = 3;
while n > 0 {
println!("{n}...");
n -= 1;
}
println!("发射!");
}3. for:遍历迭代器(最常用)
for 循环通过迭代器工作,是 Rust 中最安全的选择,因为它不会出现索引越界(Out of Bounds)的问题。
| 使用方法 | 等价使用方式 | 所有权 |
|---|---|---|
for item in collection | for item in IntoIterator::into_iter(collection) | 转移所有权 |
for item in &collection | for item in collection.iter() | 不可变借用 |
for item in &mut collection | for item in collection.iter_mut() | 可变借用 |
fn main() {
// 1. 范围遍历
for i in 0..3 { println!("范围 A: {i}"); } // 0, 1, 2
for i in 0..=3 { println!("范围 B: {i}"); } // 0, 1, 2, 3
// 2. 遍历集合(借用与移动)
let v = vec![10, 20, 30];
for x in &v { println!("借用元素: {x}"); } // v 依然可用
// 3. 可变借用遍历
let mut nums = vec![1, 2, 3];
for x in &mut nums {
*x *= 10; // 修改原始数据
}
// 4. 带索引遍历
for (i, val) in nums.iter().enumerate() {
println!("索引 {i} 的值是 {val}");
}
}4. 循环控制与标签
continue:结束当前迭代,立即开始下一次。break:立即退出当前循环。- 循环标签 :在处理多层嵌套循环时,你可以给循环起名字(以单引号开头),以便在内层直接退出外层, 影响可读性。
fn main() {
'outer: for i in 0..10 {
'inner: for j in 0..10 {
if i + j == 5 {
println!("找到目标:i={}, j={}", i, j);
break 'outer; // 跳出最外层循环
}
}
}
}三、match 表达式(Pattern Matching)
match 是 Rust 的“核心杀手锏”,它非常类似于多分支的 switch,但功能要强大得多。它强制要求 穷尽性检查 ,即你必须处理所有可能的情况。
1. 基本用法与模式
match 的每个分支被称为一个“臂(Arm)”。_ 是通配符,用于捕获所有未明确列出的情况。
fn main() {
let n = 3;
match n {
1 => println!("一"),
2 => println!("二"),
3 => println!("三"),
_ => println!("其他数字"), // 必须有这一行,除非 n 的所有可能已被覆盖
}
}2. 范围与多重匹配
你可以使用 | 匹配多个值,或使用 ..= 匹配一个闭区间。
fn main() {
let score = 85;
match score {
0..=59 => println!("不及格"),
60..=80 => println!("合格"),
81..=100 => println!("优秀"),
_ => println!("无效分数"),
}
let day = 6;
match day {
1 | 2 | 3 | 4 | 5 => println!("工作日"),
6 | 7 => println!("周末"),
_ => println!("火星日?"),
}
}3. 解构复合类型(元组/结构体/枚举)
match 最强大的地方在于它可以“拆解”数据结构。
struct Point { x: i32, y: i32 }
enum Message { Quit, Write(String) }
fn main() {
// 1. 解构元组
let pair = (0, -2);
match pair {
(0, y) => println!("在 Y 轴上: {y}"),
(x, 0) => println!("在 X 轴上: {x}"),
_ => println!("在象限内"),
}
// 2. 解构结构体
let p = Point { x: 10, y: 0 };
match p {
Point { x, y: 0 } => println!("X 轴上的点,x = {x}"),
Point { x, y } => println!("普通点 ({x}, {y})"),
}
// 3. 解构枚举
let msg = Message::Write(String::from("Hello"));
match msg {
Message::Quit => println!("退出"),
Message::Write(s) => println!("消息内容: {s}"),
}
}4. 进阶:匹配守卫与 @ 绑定
- 匹配守卫 (Match Guard) :在模式匹配的基础上增加
if条件,用于更细粒度的过滤。 @绑定 :允许你在匹配一个值的同时,将其绑定到一个变量上,方便后续使用。
fn main() {
// 匹配守卫
let num = Some(10);
match num {
Some(x) if x > 5 => println!("大于 5 的数字: {x}"),
Some(x) => println!("普通数字: {x}"),
None => (),
}
// @ 绑定
let age = 7;
match age {
v @ 1..=12 => println!("小孩,年龄是: {v}"),
v @ 13..=19 => println!("青少年,年龄是: {v}"),
_ => println!("成年人"),
}
}5. 核心应用:Option 和 Result
这是 match 在 Rust 中最高频的出现场景,用于安全地处理可能为空或可能出错的值。
fn main() {
let res: Result<i32, &str> = Ok(200);
match res {
Ok(code) => println!("请求成功,状态码: {code}"),
Err(msg) => println!("请求失败: {msg}"),
}
}函数与闭包
一、 函数 (Functions)
函数是 Rust 代码的静态骨架。它们必须在编译时拥有明确的签名。
1. 基础语法与显式返回
Rust 的函数参数必须标注类型,返回类型使用 -> 标注。
// 逻辑概括:参数必须显式注明类型,最后一行表达式作为返回值
fn calculate_score(points: i32, multiplier: i32) -> i32 {
if points < 0 {
return 0; // 使用 return 提前退出
}
points * multiplier // 隐式返回(无分号)
}
fn main() {
let score = calculate_score(10, 3);
println!("最终得分: {score}");
}2. 函数指针 (fn 类型)
函数本身可以作为参数传递,也可以存储在变量中。它的类型是小写的 fn。
fn add_one(x: i32) -> i32 { x + 1 }
fn do_math(f: fn(i32) -> i32, value: i32) -> i32 {
f(value)
}
fn main() {
let result = do_math(add_one, 5);
println!("函数指针调用结果: {result}"); // 6
}二、 闭包 (Closures)
Rust 中的闭包(closures)是一种匿名函数,可以捕获其环境中的变量。闭包类似于其他语言中的 lambda 表达式,但 Rust 的闭包系统与所有权和借用紧密集成,确保内存安全。闭包可以作为函数参数、返回值,或存储在变量中,常用于迭代器、线程和回调。Rust 闭包实现了Fn trait 家族(Fn、FnMut、FnOnce),根据捕获方式决定其行为。最核心的特性是 捕获环境 。它们通常比函数更简洁,且支持类型推导。
1. 语法与自动推导
闭包不强制写类型,编译器会根据第一次调用的上下文锁定类型。语法:|params| expression 或 { body }。
fn main() {
// 闭包标准语法
let closure_annotated = |x: i32| -> i32 { x + 1 };
// 自动推导简写
let closure_inferred = |x| x + 1;
println!("{}", closure_annotated(1));
println!("{}", closure_inferred(1));
}2. 捕获方式:不可变、可变、移动
闭包通过三种方式从作用域捕获变量:
- 不可变借用 (
&T) :默认方式。 - 可变借用 (
&mut T) :当闭包内部修改变量时。 - 移动所有权 (
T) :使用move关键字,常用于异步或多线程。
fn main() {
let x = 4;
let equal_to_x = |z| z == x; // 借用 x (&x)
println!("相等?{}", equal_to_x(4)); // 输出: 相等?true
println!("x 仍有效: {}", x); // x 未移动
//可变借用
let mut count = 0;
let mut inc = || {
count += 1; // 自动推导为 可变借用
println!("当前计数: {count}");
};
inc();
inc();
// 强制移动所有权
let text = String::from("hello");
let print_text = move || println!("移动后的文本: {text}");
print_text();
// println!("{text}"); // ❌ 报错:text 已移动到闭包中
}三、 闭包特征 (Fn, FnMut, FnOnce)
当闭包作为参数传递时,我们需要使用这三个 Trait 来约束它:
FnOnce:调用一次,消耗闭包(可能移动捕获)。FnMut:可多次调用,可修改捕获。Fn:可多次调用,只读捕获。
fn run_once<F>(f: F) where F: FnOnce() {
f();
}
fn main() {
let s = String::from("once");
let consume_s = || drop(s); // 该闭包消费了 s 的所有权
run_once(consume_s);
// run_once(consume_s); // ❌ 报错:闭包已被消费
}四、 高级进阶:函数与闭包作为返回值
这是 Rust 中最具灵活性的部分。由于闭包没有具体的名字,返回它们需要特殊的处理。
1. 返回普通函数指针 (fn)
适用于逻辑固定、不捕获外部变量的情况。
fn apply<F>(f: F, x: i32) -> i32
where
F: FnOnce(i32) -> i32, // bound FnOnce
{
f(x)
}
fn main() {
let double = |n| n * 2;
println!("结果: {}", apply(double, 5)); // 输出: 结果: 10
}2. 返回闭包:静态分发 (impl Trait)
这是返回闭包最常用的方式。它效率高(无堆分配),但要求所有分支返回同一种闭包。
fn create_multiplier(factor: i32) -> impl Fn(i32) -> i32 {
// 关键:必须使用 move,将 factor 移入闭包
// 否则 factor 会在函数结束时释放,导致引用失效
move |x| x * factor
}
fn main() {
let double = create_multiplier(2);
println!("3 的两倍是: {}", double(3));
}3. 返回闭包:动态分发 (Box<dyn Trait>)
如果你需要根据逻辑返回不同的闭包(比如在 if/else 分支中返回不同的闭包代码块),必须使用 Box。
fn get_closure(mode: bool) -> Box<dyn Fn(i32) -> i32> {
if mode {
Box::new(|x| x + 1)
} else {
Box::new(|x| x * 2)
}
}
fn main() {
let f = get_closure(false);
println!("执行结果: {}", f(5)); // 10
}总结对比
| 特性 | 普通函数 (fn) | impl Trait 闭包 | Box<dyn Trait> 闭包 |
|---|---|---|---|
| 捕获变量 | 不支持 | 支持(需用 move) | 支持(需用 move) |
| 返回类型 | fn(A) -> B | impl Fn(A) -> B | Box<dyn Fn(A) -> B> |
| 内存位置 | 代码段 | 栈 | 堆 |
| 性能 | 极高(静态) | 高(静态) | 略低(动态寻址) |
| 适用场景 | 简单、纯粹的逻辑 | 性能敏感、单一返回路径 | 需要根据条件返回不同闭包 |
💡 核心避坑指南
在返回闭包时,忘记写 move 是新手最常见的错误。
记住 :闭包默认会尝试通过“引用”来捕获环境中的变量。但当函数结束时,这些变量会被销毁,所以闭包必须通过
move把它们“打包带走”,否则你会得到一个“悬垂引用”的报错。
错误处理
Rust 的错误处理体系以其严谨性著称。它不使用传统的 try-catch 异常机制,而是通过类型系统将错误显式化,强制开发者在编译期就面对可能的失败。
一、 不可恢复错误:panic!
当程序遇到无法恢复的错误时(如数组越界或断言失败),Rust 使用 panic! 宏来终止执行。这会 unwind 栈(清理资源)或直接 abort(不清理,适合嵌入式系统)。
1. 发生什么?
- 程序打印错误信息。
- 展开(Unwinding) :Rust 沿着栈往回走,清理每个函数的数据(释放所有权)。
- 程序退出。
fn main() {
// 主动触发 panic
// panic!("这里发生了不可预见的灾难!");
let v = vec![1, 2, 3];
v[99]; // ❌ 被动触发 panic:索引越界
}当你取到了一个不属于你的值,这在很多时候会导致程序上的逻辑 BUG! 有编程经验的人都知道这种逻辑上的 BUG 是多么难被发现和修复!因此程序直接崩溃,然后告诉我们问题发生的位置,最后我们对此进行修复,这才是最合理的软件开发流程,而不是把问题藏着掖着:
#![allow(unused)]
fn main() {
thread 'main' (12) panicked at src/main.rs:6:6:
index out of bounds: the len is 3 but the index is 99
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
}好的,现在成功知道问题发生的位置,但是如果我们想知道该问题之前经过了哪些调用环节,该怎么办?那就按照提示使用 RUST_BACKTRACE=1 cargo run 或 $env:RUST_BACKTRACE=1 ; cargo run 来再一次运行程序
#![allow(unused)]
fn main() {
thread 'main' panicked at 'index out of bounds: the len is 3 but the index is 99', src/main.rs:6:6
stack backtrace:
0: rust_begin_unwind
at /rustc/59eed8a2aac0230a8b53e89d4e99d55912ba6b35/library/std/src/panicking.rs:517:5
1: core::panicking::panic_fmt
at /rustc/59eed8a2aac0230a8b53e89d4e99d55912ba6b35/library/core/src/panicking.rs:101:14
2: core::panicking::panic_bounds_check
at /rustc/59eed8a2aac0230a8b53e89d4e99d55912ba6b35/library/core/src/panicking.rs:77:5
3: <usize as core::slice::index::SliceIndex<[T]>>::index
at /rustc/59eed8a2aac0230a8b53e89d4e99d55912ba6b35/library/core/src/slice/index.rs:184:10
4: core::slice::index::<impl core::ops::index::Index<I> for [T]>::index
at /rustc/59eed8a2aac0230a8b53e89d4e99d55912ba6b35/library/core/src/slice/index.rs:15:9
5: <alloc::vec::Vec<T,A> as core::ops::index::Index<I>>::index
at /rustc/59eed8a2aac0230a8b53e89d4e99d55912ba6b35/library/alloc/src/vec/mod.rs:2465:9
6: world_hello::main
at ./src/main.rs:4:5
7: core::ops::function::FnOnce::call_once
at /rustc/59eed8a2aac0230a8b53e89d4e99d55912ba6b35/library/core/src/ops/function.rs:227:5
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
}上面的代码就是一次栈展开(也称栈回溯),它包含了函数调用的顺序,当然按照逆序排列:最近调用的函数排在列表的最上方。因为咱们的 main 函数基本是最先调用的函数了,所以排在了倒数第二位,还有一个关注点,排在最顶部最后一个调用的函数是 rust_begin_unwind,该函数的目的就是进行栈展开,呈现这些列表信息给我们。
要获取到栈回溯信息,你还需要开启 debug 标志,该标志在使用 cargo run 或者 cargo build 时自动开启(这两个操作默认是 Debug 运行方式)。同时,栈展开信息在不同操作系统或者 Rust 版本上也有所不同。
2. 何时使用?
- 示例代码或原型 :快速展示逻辑。
- 测试代码 :断言失败。
- 逻辑不可达 :你确信这段代码永远不会运行到,除非有严重的 Bug。
二、 可恢复错误:Option 与 Result
这是 Rust 错误处理的核心,通过两个枚举来包裹“可能不存在的值”或“可能失败的操作”。Rust 不使用异常,而是返回枚举类型:
- Option:表示可能为空的值。Some(T) 或 None。
- Result<T, E>:表示成功或失败。Ok(T) 或 Err(E)。
1. Option<T>:值可能不存在
用于表示一个值要么有(Some(T)),要么没有(None)。
fn find_index(target: i32, list: Vec<i32>) -> Option<usize> {
for (i, &item) in list.iter().enumerate() {
if item == target { return Some(i); }
}
None
}
fn main() {
let list = vec![10, 20, 30];
match find_index(20, list) {
Some(index) => println!("找到索引: {index}"),
None => println!("未找到"),
}
}2. Result<T, E>:操作可能失败
用于表示一个操作要么成功(Ok(T)),要么失败(Err(E))。
use std::fs::File;
fn main() {
let greeting_file_result = File::open("hello.txt");
let _file = match greeting_file_result {
Ok(file) => file,
Err(error) => panic!("打开文件失败: {:?}", error),
};
}模式匹配和 unwrap
- match:最安全的方式。
- unwrap():如果 Ok 返回值,否则 panic!(不推荐生产环境)。
- expect(“消息”):类似 unwrap,但自定义 panic 消息。
- unwrap_or(default):为 Option/Result 提供默认值。
- unwrap_or_else(closure):懒惰计算默认值。
三、 常用组合器 (Combinators)
组合器允许你以函数式的风格链式处理 Option 和 Result,避免层层嵌套的 match。
| 组合器 | 作用描述 |
|---|---|
.map() | 仅对成功(Some/Ok)的值进行转换 |
.and_then() | 类似 map,但闭包也返回 Result/Option(自动平铺嵌套) |
.unwrap_or() | 如果失败/缺失,则返回一个默认值 |
.unwrap_or_else() | 类似 unwrap_or,但默认值通过闭包计算(延迟求值) |
.map_err() | 仅对 Err 进行转换(通常用于转换错误类型) |
fn main() {
// --- 1. .map(): 只转换成功的值,忽略失败 ---
let s = Some("5");
let n = s.map(|val| val.parse::<i32>().unwrap_or(0));
// n 现在是 Some(5)
// --- 2. .and_then(): 展平嵌套(类似 flat_map) ---
// 如果转换函数也返回 Option/Result,用 and_then 防止出现 Option<Option<T>>
let get_val = |i: i32| if i > 0 { Some(i * 2) } else { None };
let result = Some(10).and_then(get_val);
// result 是 Some(20),而不是 Some(Some(20))
// --- 3. .unwrap_or() 与 .unwrap_or_else(): 兜底默认值 ---
let x: Option<i32> = None;
let val = x.unwrap_or(0); // 如果是 None,则返回 0
// or_else 接受闭包,适合计算默认值开销较大的场景(延迟求值)
let val_lazy = x.unwrap_or_else(|| {
// 执行复杂的计算过程...
100
});
// --- 4. .map_err(): 只处理错误,不改动成功值 ---
let res: Result<i32, i32> = Err(404);
let updated_res = res.map_err(|e| format!("Error code: {}", e));
// updated_res 是 Err("Error code: 404")
println!("组合器处理结果: {:?}, {}, {:?}", n, val, updated_res);
}四、 ? 操作符:错误传播的捷径
? 操作符是 Rust 错误传播的语法糖。它可以极大地简化代码,让逻辑保持清晰。程序几乎不太可能只有 A->B 形式的函数调用,一个设计良好的程序,一个功能涉及十几层的函数调用都有可能。而错误处理也往往不是哪里调用出错,就在哪里处理,实际应用中,大概率会把错误层层上传然后交给调用链的上游函数进行处理,错误传播将极为常见
1. 工作原理
当你在一个返回 Result 的表达式后面加 ? 时:
- 如果结果是
Ok,它会自动解包出里面的值,程序继续执行。 - 如果结果是
Err,它会立即 提前返回 (Return)整个函数,并将错误传递给调用者。
use std::fs::File;
use std::io::{self, Read};
fn read_username() -> Result<String, io::Error> {
// 如果 open 失败,直接返回 Err;如果成功,f 绑定为 File 对象
let mut f = File::open("name.txt")?;
let mut s = String::new();
f.read_to_string(&mut s)?; // 如果读取失败,直接返回 Err
Ok(s)
}
fn main() -> Result<(), Box<dyn std::error::Error>> {
let username = read_username()?;
println!("用户名: {}", username);
Ok(())
}- 解释:? 等价于
let mut file = match File::open(filename) {
Ok(f) => f,
Err(e) => return Err(e),
};
- 要求:函数必须返回
Result/Option。 - 链式使用:支持多个 ?,错误会向上传播。
From trait:如果错误类型不同,? 会自动转换(如果实现了 From)。
2. 使用限制
?只能在返回类型与?处理的类型相兼容的函数中使用(例如在返回Result的函数中处理Result)。- 在
main函数中使用?需要将main的返回类型改为Result<(), Box<dyn Error>>。
五、自定义错误类型
对于复杂应用,定义自己的错误枚举,结合 thiserror 或 anyhow crate 更加方便。
总结概括
panic!:用于 程序 Bug 。当你无法预见错误或错误会导致程序状态不可靠时使用。Option:用于 可能缺失 。不代表失败,只是“没有”。Result:用于 可能失败 。明确区分成功数据和错误信息。?:用于 传播错误 。让错误处理像写直线代码一样简单。- 组合器 :用于 优雅转换 。让数据在各种状态间流动而不需要嵌套判断。
结构体
在 Rust 中,结构体Structs是构建复杂程序的基石。它允许你将相关联的数据组合在一起,创建出更有意义的自定义类型。相比于元组,结构体为每个数据片段命名,因此更加灵活且意图清晰。
一、 结构体的三种类型
Rust 支持三种不同风格的结构体,分别适用于不同的场景。
1. 具名结构体 (Classic Structs)
最常用的类型,类似于其他语言中的类或对象,每个字段都有明确的名字。
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
// 实例化结构体
let user1 = User {
email: String::from("someone@example.com"),
username: String::from("someuser123"),
active: true,
sign_in_count: 1,
};
println!("用户 {} 的邮箱是 {}", user1.username, user1.email);
}关键点:
- 结构体通常拥有其数据,使用如 String 的拥有类型,以确保数据在结构体存在期间有效。
- 如果使用引用(如 &str),需要指定生命周期(lifetime),以避免悬垂引用(dangling references)。
- 字段不能单独标记为可变,整个结构体实例必须是可变的才能修改字段。
2. 元组结构体 (Tuple Structs)
当你想给整个元组起个名字,但不需要为内部每个字段命名时使用。
struct Color(i32, i32, i32);
struct Point(i32, i32, i32);
fn main() {
let black = Color(0, 0, 0);
let origin = Point(0, 0, 0);
// 注意:虽然内部类型一样,但 Color 和 Point 是不同的类型!
println!("第一个颜色分量: {}", black.0);
}3. 单元结构体 (Unit-like Structs)
没有任何字段。常用于需要在某个类型上实现 Trait但不需要存储数据的情况。
struct AlwaysEqual;
fn main() {
let _subject = AlwaysEqual;
}二、 实例化
1. 字段初始化简写 (Field Init Shorthand)
当变量名与字段名完全相同时,可以简写。
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn build_user(email: String, username: String) -> User {
User {
active: true,
username, // 等同于 username: username
email, // 等同于 email: email
sign_in_count: 1,
}
}
fn main() {
let user1 = build_user(String::from("a@b.com"), String::from("user1"));
println!("用户 {} 的邮箱是 {}", user1.username, user1.email);
}2. 结构体更新语法 (Struct Update Syntax)
当你想要创建一个新实例,但大部分数据与旧实例相同时,使用 .. 语法。
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
let user1 = User {
email: String::from("a@b.com"),
username: String::from("user1"),
active: true,
sign_in_count: 1,
};
// 使用 user1 的部分数据创建 user2
let user2 = User {
email: String::from("c@d.com"),
..user1 // 剩余字段直接拷贝/移动自 user1
};
println!("用户 {} 的邮箱是 {}", user2.username, user2.email);
// println!("用户 {} 的邮箱是 {}", user1.username, user1.email);
// 注意:由于 String 发生了所有权转移,user1.username 此时已失效!除非那些字段实现了 Copy trait
}3. 访问和更新字段
使用点号 . 访问字段。要更新,需要可变实例(mut)。
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
let mut user1 = User {
email: String::from("a@b.com"),
username: String::from("user1"),
active: true,
sign_in_count: 1,
};
user1.email = String::from("newemail@example.com");
println!("用户 {} 的邮箱是 {}", user1.username, user1.email);
}三、 结构体方法:impl 块
在 Rust 中,数据定义(struct)和行为定义(impl)是分开的。
- 方法 (Methods) :第一个参数是
self,通过实例调用。 - 关联函数 (Associated Functions) :没有
self参数,通过类型名::调用(类似静态方法)。
#[derive(Debug)] // 允许通过 {:?} 打印结构体
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
// 关联函数:通常用于构造函数
fn square(size: u32) -> Self {
Self { width: size, height: size }
}
// 方法:计算面积
// 使用 &self 借用实例,而不是获取所有权
fn area(&self) -> u32 {
self.width * self.height
}
// 方法:判断当前矩形是否能容纳另一个矩形
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
fn main() {
let rect1 = Rectangle { width: 30, height: 50 };
let rect2 = Rectangle::square(10); // 调用关联函数
println!("矩形面积: {}", rect1.area());
println!("rect1 能容纳 rect2 吗? {}", rect1.can_hold(&rect2));
println!("打印结构体详情: {:?}", rect1);
}关键差异与 OOP
- Rust 无自动 getter/setter,需要手动定义。
- 方法名可与字段名相同(基于语法区分)。
- 强调借用规则,与 OOP 的封装不同。
- Rust 自动处理引用/解引用,无需 -> 操作符。
四、 结构体与所有权
这是新手最容易困惑的地方:
- 字段的所有权 :如果结构体拥有其字段的所有权(如
String),那么当结构体被销毁时,字段也会被销毁。结构体字段若为拥有类型(如 String),实例移动时会转移所有权。 - 在结构体中存储引用 :如果你希望结构体存储一个指向外部数据的引用(如
&str),你需要使用 生命周期(Lifetimes) 标注。
目前建议先使用拥有所有权的类型(如
String而不是&str),直到学习到生命周期章节。 优先使用借用(&)以避免不必要的移动
总结
| 特性 | 具名结构体 | 元组结构体 | 单元结构体 |
|---|---|---|---|
| 访问方式 | s.field_name | s.0, s.1 | 不可访问 |
| 语义 | 明确的数据对象 | 强类型化的元组 | 标签或特征实现 |
| 典型案例 | 用户信息、配置项 | 坐标 (x, y)、颜色 (r, g, b) | 状态标记、Trait 对象 |
枚举
如果说结构体(Struct)是将多个相关数据“打包”在一起,那么枚举Enums则是让一个变量在“多种可能”中选择其一。
在 Rust 中,枚举不仅是其他语言中常见的整数常量列表,它还是功能极其强大的 代数数据类型(Algebraic Data Types) 。
一、 基础枚举:简单的分类
这是枚举最基础的用法,用于定义一组离散的选项。
enum IpAddrKind {
V4,
V6,
}
fn main() {
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
// 枚举可以作为函数参数
route(four);
route(six);
}
fn route(ip_kind: IpAddrKind) {}关键点:
- 枚举变体(如 V4、V6)是枚举类型的成员。
- 枚举可以作为参数传递给函数,也可以在函数中返回。
- 你可以在
match表达式中匹配枚举的每个变体,处理不同的情况。
二、 枚举的真威力:携带数据
在 Rust 中,每个枚举变体(Variant)都可以关联不同类型、不同数量的数据。这让你可以用一个类型表达多种结构完全不同的信息。
enum Message {
Quit, // 无数据
Move { x: i32, y: i32 }, // 匿名结构体
Write(String), // 单个 String
ChangeColor(i32, i32, i32), // 元组
}
impl Message {
fn call(&self) {
// 你也可以为枚举定义方法!
}
}
fn main() {
let m = Message::Write(String::from("hello"));
m.call();
}为什么这比结构体好用?
如果你用结构体来实现上面的功能,你可能需要定义 4 个不同的结构体(Rust 是一种强静态类型语言,函数在编译时必须明确知道它接收的参数是什么类型,以及该类型占用的空间大小)。而使用枚举,它们都属于 Message 类型,方便在函数间统一传递。
三、 核心中的核心:Option 枚举
Rust 没有空值(Null) 。为了表达“一个值可能不存在”,Rust 使用了标准库中定义的 Option<T> 枚举:
enum Option<T> {
None,
Some(T),
}Some(T):代表有值,值为T类型。None:代表没有值。
意义何在?
在有 Null 的语言中,你随时可能忘记检查空指针而导致崩溃。在 Rust 中,如果你有一个 Option <i32>,你必须处理 None 的情况,否则代码编译不通过。这从根本上杜绝了空指针异常。
四、 模式匹配:枚举的完美搭档
要获取枚举内部的数据,最常用的工具就是 match 表达式。
1. match:穷尽式检查
match 强制你处理枚举的每一个变体。
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => 1,
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter(state) => {
println!("来自 {:?} 州的 25 美分", state);
25
},
}
}
fn main() {
let coin = Coin::Quarter(UsState::Alaska);
let cents = value_in_cents(coin);
println!("{} 美分", cents);
}2. if let:更简洁的匹配
如果你只关心其中的一种情况,if let 是比 match 更优雅的选择。
fn main() {
let some_u8_value = Some(3u8);
// 仅在值为 Some 时处理
if let Some(value) = some_u8_value {
println!("找到了{}!", value);
}else{
println!("没有找到值!");
}
}五、 枚举的内存布局(进阶)
枚举在内存中是如何存储的?
Rust 会为枚举分配足够的空间来容纳最大的那个变体,此外还需要一个小的标签Tag来记录当前存的是哪一个变体。
对于一个枚举 $E$,其占用内存大小大致为:
$$ Size(E) = Size(Tag) + \max(Size(Variant_1), Size(Variant_2), \dots) $$
小技巧:
对于 Option<&T>,因为引用(指针)永远不会为 0,Rust 会非常聪明地用 0 来表示 None。这意味着 Option<&T> 和 &T 占用的空间是一样大的!
总结:结构体 vs 枚举
| 特性 | 结构体 (Struct) | 枚举 (Enum) |
|---|---|---|
| 逻辑关系 | “和”(And):包含 A 且包含 B | “或”(Or):要么是 A 要么是 B |
| 数据访问 | 通过 . 直接访问字段 | 必须通过 match 或 if let 解构 |
| 主要用途 | 定义具体的数据实体 | 定义状态机、分类、错误处理 |
切片
Rust 中的 slice(切片)是一种引用集合中连续元素的视图,而不拥有这些元素。它类似于数组或向量的子视图,使用 &[T] 表示不可变切片,&mut [T] 表示可变切片。Slice 是借用的一部分,遵守借用规则,确保内存安全。Slice 常用于字符串、数组和向量,帮助避免不必要的拷贝,提高效率。
1. Slice 简介
- 什么是 slice? :Slice 是对数据序列的引用视图,指向连续内存块。不拥有数据,只借用。长度在运行时确定。
- 语法 :
&[T](不可变)、&mut [T](可变)。T 是元素类型。 - 优势 :零拷贝访问子集;函数参数通用(如接受
&[i32]而非 Vec 或[i32; N])。 - 与数组/向量的关系 :数组是固定大小,向量是动态。Slice 可以从两者创建。
- 字符串 slice :
&str是&[u8]的特殊形式,处理 UTF-8。
fn main() {
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];
println!("{}", hello); // 输出: hello
println!("{}", world); // 输出: world
}- 解释 :
[start..end]是半开区间(包括 start,不包括 end)。&arr[..]是全切片。Slice 借用 arr,借用规则适用。
对于字符串而言,切片就是对 String 类型中某一部分的引用,它看起来像这样:
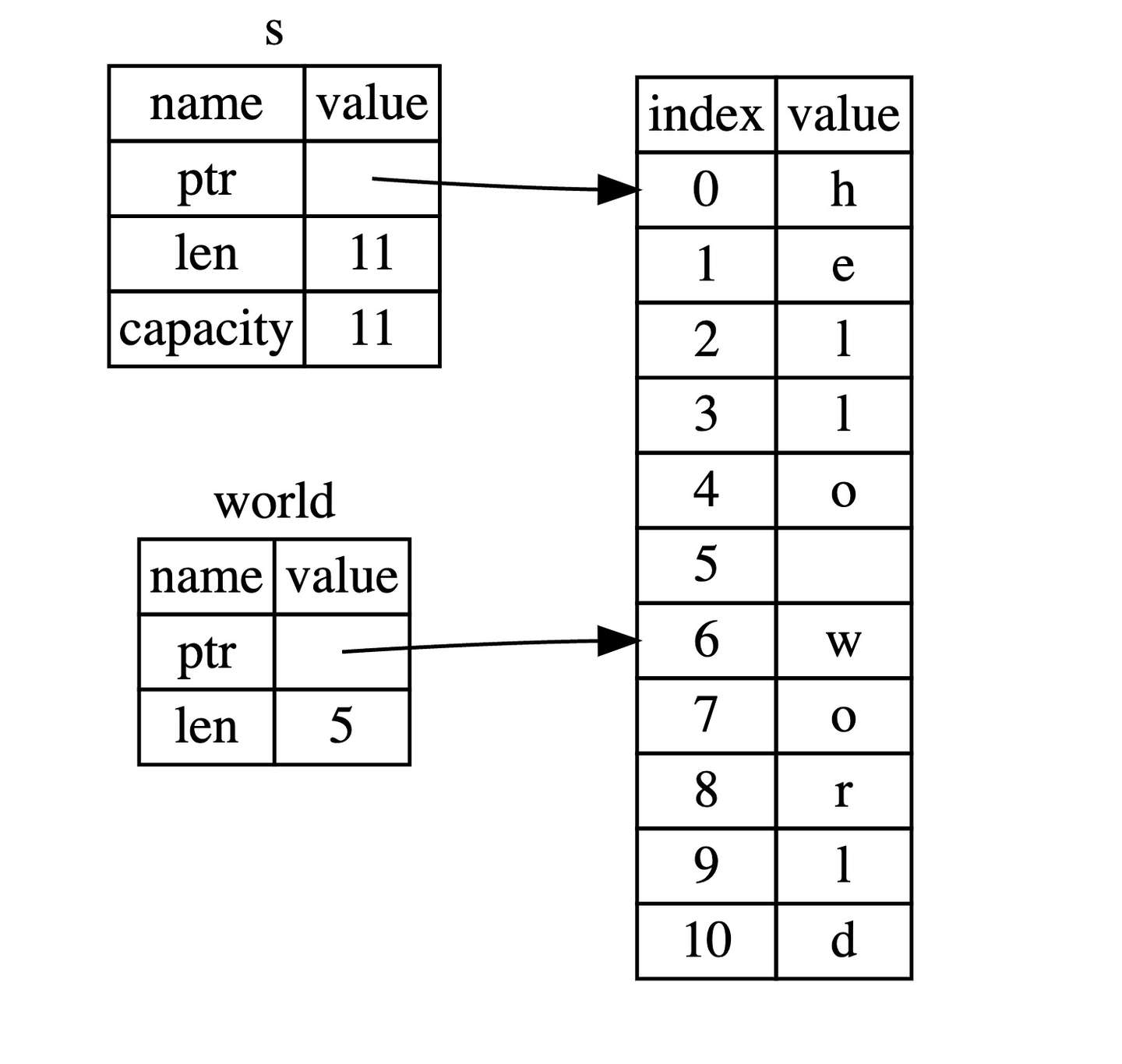
胖指针(Fat Pointer)
- 数据结构:对比普通引用(1个字长指针)与切片引用(2个字长)。
- 组成部分:
- Pointer:指向数据的起始位置。
- Length:切片包含的元素个数。
- 内存视图:在栈上存储元数据,在堆/静态区查看数据。
2. 创建 Slice
Slice 通过借用和范围运算符创建。
- 范围语法 :
[start..end]:从 start 到 end-1。[..end]:从 0 到 end-1。[start..]:从 start 到结束。[..]:整个集合。
- 从向量/数组 :直接 &vec[start..end]。
- 边界检查 :运行时检查,如果越界 panic!(安全)。
示例:各种创建方式
fn main() {
let vec = vec![10, 20, 30, 40, 50];
let full = &vec[..]; // 全切片: [10, 20, 30, 40, 50]
let first_three = &vec[0..3]; // [10, 20, 30]
let last_two = &vec[3..]; // [40, 50]
println!("{:?}", first_three);
}- 解释 :Vec 和数组都支持。Slice 的 len() 返回元素数,get(i) 返回 Option<&T>(安全访问)。
可变 slice
fn main() {
let mut vec = vec![1, 2, 3];
let slice = &mut vec[1..3]; // 可变借用
slice[0] = 20; // 修改 vec[1]
println!("{:?}", vec); // 输出: [1, 20, 3]
}- 解释 :可变 slice 允许修改元素,但遵守独占借用规则。
3. 字符串 Slice (&str)
字符串 slice 是常见的,处理 String 或 str。
示例:字符串 slice
fn first_word(s: &str) -> &str { // 既能接受 String 的切片,也能接受字符串字面量
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let s = String::from("hello world");
let word = first_word(&s); // &String 隐式转为 &str
println!("{}", word); // 输出: hello
// s.clear(); // 错误!word 借用期间不能修改 s
}- 解释 :
&str是 UTF-8 安全的。as_bytes() 转为&[u8]。切片索引必须在字符边界(否则 panic!)。用 chars() 或 bytes() 迭代以避免。
4. 多维 Slice
Slice 可以是多维的,如 &[[T]]。
示例:矩阵 slice
fn main() {
let matrix = vec![vec![1, 2], vec![3, 4]];
let row = &matrix[0][..]; // &[i32]: [1, 2]
println!("{:?}", row);
}- 解释:嵌套借用。复杂时考虑扁平化或专用 crate。
注意事项: 索引越界:如果你请求的范围超出了集合边界(如
&s[0..100]),Rust 会在运行时 panic。 UTF-8 字符:对于字符串切片,索引必须落在字符边界上。如果在多字节字符(如中文)中间切片,程序会崩溃。
常用集合
在 Rust 标准库 std::collections 模块下,集合被分为四大通用类型 线性序列 、Key-Value 映射表 、集合类型和 优先队列 。这些集合存储在堆内存中,并通过指针(如引用、智能指针)进行管理。
一、 线性序列 (Linear Sequences)
这类集合按顺序存储数据,适合处理列表、队列等逻辑。
- 向量 (Vec) :最常用的动态数组。支持快速随机访问,在末尾插入/删除效率最高。
- 双端队列 (VecDeque) :基于循环缓冲区实现。在序列的头部和尾部插入或删除数据都非常高效。
- 链表 (LinkedList) :双向链表。虽然支持快速合并和拆分,但由于内存不连续,现代硬件上性能通常不如
Vec。
代码示例:Vec 与 VecDeque
use std::collections::VecDeque;
fn main() {
// 1. Vec: 动态数组
let mut v = vec![1, 2, 3];
v.push(4);
println!("Vec 第三个元素: {}", v[2]); // 随机访问
// 2. VecDeque: 双端操作
let mut dq = VecDeque::new();
dq.push_back(10); // 尾部插入
dq.push_front(20); // 头部插入
println!("Deque 头部: {:?}", dq.front()); // 输出 Some(20)
}二、 Key-Value 映射表 (Key-Value Maps)
映射表用于存储“键-值”对,通过键来快速查找对应的值。
- 无序哈希表 (HashMap) :通过哈希函数存储。查找速度极快(平均 $O(1)$),但由于哈希冲突和重新分配,内部顺序是无序的。
- 有序哈希表 (BTreeMap) :基于 B 树实现。键(Key)必须实现
Ord特征,数据会按键的大小自动排序存储。
代码示例:HashMap 与 BTreeMap
use std::collections::{HashMap, BTreeMap};
fn main() {
// 1. HashMap: 无序
let mut scores = HashMap::new();
scores.insert("Alice", 90);
scores.insert("Bob", 85);
// 2. BTreeMap: 自动排序
let mut sorted_map = BTreeMap::new();
sorted_map.insert(3, "c");
sorted_map.insert(1, "a");
sorted_map.insert(2, "b");
// 遍历 BTreeMap 时,顺序始终是 1, 2, 3
for (key, value) in &sorted_map {
println!("{}: {}", key, value);
}
}三、 集合类型 (Set Types)
集合类型实际上是不带“值”的映射表,主要用于保证元素的 唯一性 。
- 无序集合 (HashSet) :基于
HashMap实现。用于快速去重或检查某个元素是否存在。 - 有序集合 (BTreeSet) :基于
BTreeMap实现。元素会根据自身顺序进行 排序 。
代码示例:HashSet 的去重功能
use std::collections::HashSet;
fn main() {
let mut books = HashSet::new();
books.insert("Rust Programming");
books.insert("Rust Programming"); // 重复插入会被忽略
if !books.contains("C++") {
println!("我们没有找到关于 C++ 的书。");
}
}四、 优先队列 (Priority Queues)
当需要始终优先处理“最大”或“最小”的元素时,使用此类集合。
- 二叉堆 (BinaryHeap) :默认是 最大堆 。无论插入顺序如何,每次弹出的总是集合中最大的元素。
代码示例:BinaryHeap
use std::collections::BinaryHeap;
fn main() {
let mut heap = BinaryHeap::new();
// 乱序插入
heap.push(1);
heap.push(5);
heap.push(2);
// 总是弹出当前最大的值
println!("弹出最大值: {:?}", heap.pop()); // 输出 Some(5)
println!("再次弹出: {:?}", heap.pop()); // 输出 Some(2)
}总结:如何选择集合?
| 需求场景 | 推荐集合类型 |
|---|---|
| 存储简单的列表、作为默认选择 | Vec |
| 需要频繁从头部插入数据 | VecDeque |
| 根据 ID 或名称快速查找数据 | HashMap |
| 需要查找数据且要求结果按顺序排列 | BTreeMap |
| 只需要去重,不关心关联值 | HashSet |
| 始终要处理“优先级最高”的任务 | BinaryHeap |
泛型
泛型是 Rust 实现 零开销抽象(Zero-cost Abstractions) 的核心,它允许你编写不依赖于具体类型的通用代码。
- 什么是泛型?:使用类型参数(如 )定义代码,允许在不同类型上重用。T 是占位符,在使用时替换为具体类型。
- 优势:代码复用、类型安全、性能高(编译时展开)。
- 语法:在函数、struct 等后用 <参数>,如 fn foo(arg: T)。
- 与 trait 的关系:泛型常结合 trait bound(如 T: Clone)限制类型。
1. 泛型基础(Generics Basics)
泛型类型参数
Rust 中的泛型允许我们在编写函数或结构体时不指定具体类型,从而让代码更具通用性。例如:
fn swap<T>(x: T, y: T) -> (T, T) {
(y, x)
}
fn main() {
let (a, b) = swap(1, 2);
println!("Swapped values: {}, {}", a, b);
let (x, y) = swap("Hello", "World");
println!("Swapped strings: {}, {}", x, y);
}swap 函数接受两个相同类型的参数 x 和 y,并返回它们的交换值。T 在调用时会被具体类型替换,确保返回的元组类型与输入类型一致。
泛型约束
有时我们希望泛型类型参数满足特定的条件,例如只允许实现了某个特征(trait)的类型。可以使用 T: Trait 来为泛型添加约束。
- 语法:fn foo<T: Trait1 + Trait2>(arg: T)
- 常见 bound:Copy、Clone、Debug、PartialEq、PartialOrd 等。
fn print_debug<T: std::fmt::Debug>(val: T) {
println!("{:?}", val);
}
fn main() {
print_debug(42); // 传递整数,符合 Debug 特征
// print_debug("Hello"); // 编译错误,因为字符串没有 Debug 特征
}泛型方法
方法与函数类似,但它们是定义在结构体、枚举、trait 等类型上的。在定义方法时,你可以在impl块中使用泛型类型参数。
struct Pair<T> {
x: T,
y: T,
}
impl<T> Pair<T> {
// 泛型方法,接受一个泛型参数并返回其和
fn new(x: T, y: T) -> Self {
Pair { x, y }
}
fn get_x(&self) -> &T {
&self.x
}
fn get_y(&self) -> &T {
&self.y
}
}
fn main() {
let pair = Pair::new(1, 2); // T = i32
println!("Pair: {} and {}", pair.get_x(), pair.get_y());
let pair_str = Pair::new("Hello", "World"); // T = &str
println!("Pair: {} and {}", pair_str.get_x(), pair_str.get_y());
}在这个例子中,Pair 是一个泛型结构体,new 方法和 get_x、get_y 方法都是泛型方法。它们可以处理任何类型 T,确保类型一致性。
对于复杂 bound,用 where 子句提高可读性
#![allow(unused)]
fn main() {
fn some_function<T, U>(t: T, u: U) -> U
where
T: Debug + Clone,
U: Clone + PartialEq,
{
if t.clone() == u { // 错误!T 和 U 类型不同,不能比较
// ...
}
u
}
}解释:where 在签名后。适用于函数、impl、trait。
2. 结构体和枚举中的泛型
泛型结构体
结构体也可以使用泛型类型,字段类型由泛型决定,以便存储不同类型的数据。
struct Pair<T, U> {
x: T,
y: U,
}
fn main() {
let int_float = Pair { x: 42, y: 3.14 };
let string_int = Pair { x: "Hello", y: 100 };
println!("int_float: ({}, {})", int_float.x, int_float.y);
println!("string_int: ({}, {})", string_int.x, string_int.y);
}在这个示例中,Pair 结构体有两个泛型参数 T 和 U,它们可以代表不同的类型。
泛型枚举
枚举类型也可以使用泛型,允许它们处理不同类型的数据。例如,标准库中的 Option<T> 和 Result<T, E> 就是泛型枚举。
// 定义一个泛型枚举
enum MyOption<T> {
Some(T),
None,
}
fn main() {
let some_int = MyOption::Some(42);
let none: MyOption<i32> = MyOption::None;
match some_int {
MyOption::Some(value) => println!("Some: {}", value),
MyOption::None => println!("None"),
}
}3. 特征(Trait)与泛型
泛型与特征结合
特征(trait,具体看下一节介绍))可以与泛型结合使用,限制泛型类型必须实现特定的特征。例如:
// 定义一个 trait
trait Printable {
fn print(&self);
}
// 为 `i32` 实现 `Printable` 特征
impl Printable for i32 {
fn print(&self) {
println!("Printing i32: {}", self);
}
}
// 泛型函数,只有实现了 `Printable` 特征的类型才能使用
fn print_value<T: Printable>(val: T) {
val.print();
}
fn main() {
let x = 42;
print_value(x); // 可以,因为 i32 实现了 Printable 特征
}4. 生命周期(Lifetime)与泛型
有时,生命周期和泛型约束会结合使用,以确保泛型类型满足特定条件。在某些情况下,泛型类型可能是引用类型,因此需要生命周期标注。(其他复杂情况见生命周期小节)
// 一个泛型函数,它的类型 T 必须是引用类型,并且带有生命周期标注
fn first_word<'a, T>(s: &'a T) -> &'a str
where
T: AsRef<str>, // 泛型类型 T 必须实现 AsRef<str> 特征
{
let str_ref: &str = s.as_ref(); // 将 T 转换为 &str
let bytes = str_ref.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &str_ref[0..i];
}
}
&str_ref[..]
}
fn main() {
let string = String::from("Hello world");
let word = first_word(&string);
println!("The first word is: {}", word);
}5. 关联类型(Associated Types)
Rust 允许在 trait 中定义“关联类型”,这些类型在 trait 的实现中被具体化。这样可以简化泛型的使用。
// 定义一个 trait,带有关联类型
trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}
// 为 Vec 实现 Iterator 特征
impl<T> Iterator for Vec<T> {
type Item = T;
fn next(&mut self) -> Option<Self::Item> {
self.pop()
}
}
fn main() {
let mut vec = vec![1, 2, 3];
let mut iter = vec.into_iter();
println!("{:?}", iter.next()); // 输出 Some(3)
}6. 泛型与性能考虑
在 Rust中,泛型是非常强大的工具,它允许编写类型安全且灵活的代码。然而,许多人担心使用泛型是否会影响程序的性能。幸运的是,Rust的设计非常注重性能,尤其是与泛型相关的部分。让我们深入探讨泛型如何影响性能,以及如何最大程度地避免性能损失。
Rust使用一种称为 单态化(Monomorphization) 的机制来处理泛型。单态化是指编译器在编译时将泛型类型的代码转换为具体类型的实现。这意味着泛型代码在编译期间被实例化为不同类型的具体代码,因此没有运行时的性能开销。
这种机制确保了泛型代码的 零成本抽象(Zero-cost Abstraction)。也就是说,使用泛型不会导致额外的运行时开销。
尽管泛型本身不会带来运行时的性能损失,但它们可能会影响 内存布局 和 大小,特别是当涉及到动态分发时。泛型类型的大小由编译器在单态化时决定。如果泛型类型的大小变化较大,可能会导致更多的内存分配或数据拷贝。编译器会为每种具体类型生成不同的内存布局,从而避免了不必要的浪费。
7. 与标准库的泛型交互
标准库中的许多类型,如 Vec<T>、Option<T>、Result<T, E> 都使用泛型。你可以通过这些泛型类型来简化代码。
Rust 标准库几乎处处是泛型。
- 常见容器:
Vec<T>(动态数组)、HashMap<K, V>(键值对)。 - 错误处理:
Result<T, E>是编写健壮代码的核心。 - 迭代器与闭包:它们利用泛型接口实现高度灵活的数据处理流。
8. 高级泛型使用
高阶类型(HKT)的模拟
HKT (Higher Kinded Types)模拟:通过type alias和Trait模拟对“容器的抽象”。- 并发/异步:使用
Send和Sync特征约束确保泛型数据在多线程间安全传递。 - 宏与泛型:结合使用以生成复杂的泛型
boilerplate代码。
Trait
Rust 中的 trait 是一种非常强大的特性,它允许我们定义共享行为的契约,并使得不同类型可以实现这些行为。学习 Rust 中的 trait 是深入理解 Rust 编程语言的重要一步,尤其是在类型系统和抽象的层次上。
需掌握:
- 特征基础:定义、实现、默认实现。
- 特征约束 (静态分发):Trait Bound、
where子句、impl Trait。 - 多态与分发 (核心)
- 静态分发:泛型展开,性能最高。
- 动态分发:
dyn Trait对象,虚函数表 。
- 进阶特性:关联类型、Supertraits(继承)、完全限定语法。
- 高级规则:孤儿规则、覆盖实现。
- 特殊特征
- 标准库三巨头:
Debug,Display,Default - 所有权控制:
Copy,Clone,Drop - 标记特征:
Sized,Send,Sync - 运算符重载:
std::ops
- 标准库三巨头:
下面是学习 trait 时应该掌握的主要知识点,以及相关的代码示例:
1. 定义 Trait
trait是行为的集合。你可以在trait中定义方法和关联类型,其他类型可以实现这些方法。trait定义了一组方法的签名,但不包含具体的实现。
示例:定义 Trait
#![allow(unused)]
fn main() {
// 定义一个 trait
trait Speak {
fn speak(&self);
}
}2. 为类型实现 Trait
- 类型(例如结构体、枚举等)可以通过
impl块来实现某个trait。 - 一个类型可以实现多个
trait,每个trait都可以定义一组方法。
示例:为结构体实现 Trait
trait Speak {
fn speak(&self);
}
struct Dog;
impl Speak for Dog {
fn speak(&self) {
println!("Woof!");
}
}
struct Cat;
impl Speak for Cat {
fn speak(&self) {
println!("Meow!");
}
}
fn main() {
let dog = Dog;
let cat = Cat;
dog.speak(); // 输出 "Woof!"
cat.speak(); // 输出 "Meow!"
}3. Trait 默认实现
trait可以为某些方法提供默认实现,这样某些类型可以选择不实现这些方法,而是使用默认实现。
示例:Trait 的默认实现
trait Speak {
fn speak(&self) {
println!("I can speak in a default way!");
}
}
struct Dog;
impl Speak for Dog {
// 不需要显式实现 speak 方法,使用默认实现
}
fn main() {
let dog = Dog;
dog.speak(); // 输出 "I can speak in a default way!"
}4. Trait 和生命周期
- 你可以在
trait中使用生命周期标注,确保实现该trait的类型处理引用时,能够正确管理引用的生命周期。
示例:Trait 和生命周期
trait PrintWithLifetime<'a> {
fn print(&self, s: &'a str);
}
struct Printer;
impl<'a> PrintWithLifetime<'a> for Printer {
fn print(&self, s: &'a str) {
println!("{}", s);
}
}
fn main() {
let printer = Printer;
let message = "Hello, world!";
printer.print(message);
}5. 关联类型
trait可以定义 关联类型 ,这种类型在实现trait时需要指定。这种方式使得trait更加灵活和强大。
示例:使用关联类型
trait Iterator {
type Item; // 关联类型
fn next(&mut self) -> Option<Self::Item>;
}
struct Counter {
count: i32,
}
impl Iterator for Counter {
type Item = i32; // 为关联类型指定具体类型
fn next(&mut self) -> Option<Self::Item> {
self.count += 1;
Some(self.count)
}
}
fn main() {
let mut counter = Counter { count: 0 };
println!("{}", counter.next().unwrap()); // 输出 1
println!("{}", counter.next().unwrap()); // 输出 2
}6. Trait 的继承
- 一个
trait可以继承其他trait。这使得一个trait可以继承另一个trait的方法和行为。
示例:Trait 的继承
trait Animal {
fn sound(&self);
}
trait DogBehavior: Animal { // DogBehavior 继承 Animal
fn fetch(&self);
}
struct Dog;
impl Animal for Dog {
fn sound(&self) {
println!("Woof!");
}
}
//实现 DogBehavior 时,必须也实现 Animal。
impl DogBehavior for Dog {
fn fetch(&self) {
println!("Fetching the ball!");
}
}
fn main() {
let dog = Dog;
dog.sound(); // 输出 "Woof!"
dog.fetch(); // 输出 "Fetching the ball!"
}7. Trait Bound 和泛型
trait可以和泛型一起使用,通过 trait bound 来约束泛型类型,确保传入的类型实现了特定的trait。
示例:Trait Bound 和泛型
trait Speak {
fn speak(&self);
}
struct Dog;
impl Speak for Dog {
fn speak(&self) {
println!("Woof!");
}
}
fn make_speak<T: Speak>(animal: T) {
animal.speak();
}
fn main() {
let dog = Dog;
make_speak(dog); // 输出 "Woof!"
}在这个例子中,make_speak 函数的参数 T 被约束为实现了 Speak trait 的类型,因此它可以接受任何实现了 Speak 的类型作为参数。
8. Trait 作为参数和返回类型
在 Rust 的 trait 系统中,将 trait 用作参数或返回类型是实现抽象和多态的核心手段。根据性能需求和灵活性要求,Rust 提供了**静态分发(Static Dispatch)和动态分发(Dynamic Dispatch)**两种机制。
Trait 作为参数
当你希望函数能够接受多种不同类型,只要这些类型实现了特定行为时,可以使用 trait 作为参数。
A. impl Trait 语法(语法糖)
这是最简单、最常用的方式,适用于参数较少的情况。
trait Summary {
fn summarize(&self) -> String;
}
// 接受任何实现了 Summary 的类型
fn notify(item: &impl Summary) {
println!("新闻更新: {}", item.summarize());
}
fn main() {
struct Tweet { content: String }
impl Summary for Tweet {
fn summarize(&self) -> String { self.content.clone() }
}
let tweet = Tweet { content: String::from("Rust 是一种系统级语言") };
notify(&tweet); // 输出 "新闻更新: Rust 是一种系统级语言"
}B. Trait Bound(特征约束)
impl Trait 实际上是泛型特征约束的简写。在复杂的场景下(例如要求两个参数必须是同一种泛型类型),必须使用特征约束。
#![allow(unused)]
fn main() {
// 强制要求 item1 和 item2 必须是相同的具体类型 T
fn notify_double<T: Summary>(item1: &T, item2: &T) {
// ...
}
}Trait 作为返回类型
这是 Rust 抽象能力的高级体现,但根据返回的是“一种类型”还是“多种类型”,处理方式截然不同。
A. 静态分发:impl Trait
当你确定函数在编译时只会返回一种具体的类型,但不想写出冗长的类型名(如闭包或复杂的迭代器)时,使用 impl Trait。
- 优点:性能极高(零开销抽象),编译器会进行单态化处理。
- 局限:函数的所有分支必须返回同一种具体类型。
struct NewsArticle { content: String }
impl Summary for NewsArticle {
fn summarize(&self) -> String { self.content.clone() }
}
fn returns_summarizable() -> impl Summary {
NewsArticle { content: String::from("内容...") }
}
fn main() {
let article = returns_summarizable();
println!("{}", article.summarize()); // 输出 "内容..."
}
B. 动态分发:Trait 对象 (dyn Trait)
如果你需要在运行时根据条件返回不同类型的对象,必须使用特征对象。特征对象必须通过指针来使用,如引用 &dyn Trait 或智能指针 Box<dyn Trait>。
- 优点:支持真正的多态,允许在同一个函数中根据逻辑返回不同的结构体。
- 原理:使用虚函数表(vtable)在运行时查找方法。
struct Dog;
struct Cat;
impl Summary for Dog { fn summarize(&self) -> String { "汪".into() } }
impl Summary for Cat { fn summarize(&self) -> String { "喵".into() } }
// 使用智能指针 Box 包装特征对象
fn get_animal(is_dog: bool) -> Box<dyn Summary> {
if is_dog {
Box::new(Dog)
} else {
Box::new(Cat)
}
}
fn main() {
let animal = get_animal(true); // 返回 Dog 的特征对象
println!("{}", animal.summarize()); // 输出 "汪"
let animal = get_animal(false); // 返回 Cat 的特征对象
println!("{}", animal.summarize()); // 输出 "喵"
}trait Speak {
fn speak(&self);
}
struct Dog;
impl Speak for Dog {
fn speak(&self) {
println!("Woof!");
}
}
fn make_speak(animal: &dyn Speak) {
animal.speak();
}
fn main() {
let dog = Dog;
make_speak(&dog); // 使用 trait 对象动态分发
}
静态分发 vs 动态分发
| 特性 | impl Trait (静态分发) | dyn Trait (动态分发) |
|---|---|---|
| 分发时机 | 编译期 (Compile-time) | 运行期 (Runtime) |
| 性能开销 | 无(类似于内联函数) | 有(虚表查询、无法内联优化) |
| 二进制大小 | 较大(代码膨胀/单态化) | 较小 |
| 类型限制 | 必须返回单一具体类型 | 可以返回多种实现了特征的类型 |
| 指针需求 | 不需要 | 必须通过 Box, & 等指针使用 |
特征对象安全 (Object Safety)
并非所有的 trait 都能转换成 dyn Trait 对象。为了保证对象安全,trait 必须满足以下条件:
- 方法的返回类型不能是
Self。 - 方法不能有泛型类型参数。
- 方法的第一参数必须是
&self,&mut self,Box<Self>等(不能没有self)。
笔记要点:如果一个
trait不满足“对象安全”,你只能将其用作泛型约束(静态分发),而不能创建特征对象。
9. where 子句与 trait 约束
where子句可以用来指定泛型参数的 trait 约束,这使得代码更加清晰和可读。
示例:where 子句和 trait 约束
fn print_value<T>(value: T)
where
T: std::fmt::Debug, // 使用 where 子句进行 trait 约束
{
println!("{:?}", value);
}
fn main() {
print_value(42); // 可以,因为 i32 实现了 Debug trait
// print_value("Hello"); // 编译错误,字符串没有实现 Debug trait
}10. Copy 和 Clone 特征
Copy和Clone是两个常用的trait,用于控制类型的值是否可以被复制(而不是移动)。它们在处理需要复制的类型时非常重要。
示例:使用 Copy 和 Clone
trait CustomClone {
fn custom_clone(&self) -> Self;
}
#[derive(Clone)]
struct Point {
x: i32,
y: i32,
}
impl CustomClone for Point {
fn custom_clone(&self) -> Self {
Point { x: self.x, y: self.y }
}
}
fn main() {
let p1 = Point { x: 1, y: 2 };
let p2 = p1.custom_clone();
println!("p2: ({}, {})", p2.x, p2.y);
}11. 孤儿规则 (Orphan Rules)
这是 Rust 保证代码安全性的核心:你不能为外部类型实现外部特征。
- 规则:只有当特征或类型其中之一是在当前 crate(包)中定义的,你才能为该类型实现该特征。
- 目的:防止不同库之间因为冲突的实现而导致代码行为混乱。
示例:你不能在自己的项目中为 Vec<T>(标准库)实现 Display 特征(标准库),因为两者都不是你定义的。
12. 完全限定语法 (Fully Qualified Syntax)
当一个类型实现的两个不同 trait 拥有同名方法时,Rust 需要你明确指定调用哪一个。
示例:解决同名冲突
trait Pilot {
fn fly(&self);
}
trait Wizard {
fn fly(&self);
}
struct Human;
impl Pilot for Human {
fn fly(&self) { println!("准备起飞。"); }
}
impl Wizard for Human {
fn fly(&self) { println!("飞向云端。"); }
}
fn main() {
let person = Human;
// person.fly(); // ❌ 报错:歧义
Pilot::fly(&person); // 调用 Pilot 的实现
Wizard::fly(&person); // 调用 Wizard 的实现
}
13. Blanket Implementations (覆盖实现)
Rust 允许你为所有满足特定特征约束的类型实现另一个特征。这在标准库中非常常见(例如 ToString)。
示例:覆盖实现
trait MyTrait {
fn info(&self);
}
// 为所有实现了 Display 的类型实现 MyTrait
impl<T: std::fmt::Display> MyTrait for T {
fn info(&self) {
println!("信息: {}", self);
}
}
fn main() {
42.info(); // i32 实现了 Display,所以它自动拥有了 MyTrait
}14. 标记特征 (Marker Traits): Sized, Send, Sync
标记特征没有方法定义,它们告诉编译器该类型具备某种属性。
Sized:编译时已知大小的类型(默认情况下泛型T都是T: Sized)。?Sized:专门用于解除Sized限制,常用于处理dyn Trait或[T]。Send/Sync:用于并发安全,标记类型是否可以安全地跨线程传递或共享。
15. 运算符重载 (Operator Overloading)
在 Rust 中,所有的运算符(如 +, -, *)本质上都是通过特定的 trait 实现的(位于 std::ops 模块)。
示例:重载 +
use std::ops::Add;
#[derive(Debug, PartialEq)]
struct Point { x: i32, y: i32 }
impl Add for Point {
type Output = Point;
fn add(self, other: Point) -> Point {
Point { x: self.x + other.x, y: self.y + other.y }
}
}
fn main() {
let p1 = Point { x: 1, y: 0 } + Point { x: 2, y: 3 };
println!("{:?}", p1); // Point { x: 3, y: 3 }
}智能指针
Rust 里“智能指针”这块,按 “它解决什么问题 + 它的所有权/借用规则 + 运行时成本” 来系统学。下面把需要掌握的知识点尽量全列出来,并按学习路径组织。
定义
什么算“智能指针”
- 智能指针 vs 普通引用
&T/&mut T:智能指针是“像指针一样用(Deref)+ 还带管理/策略”的类型 - 三个核心 trait:
Deref/DerefMut:让*p、方法调用、解引用自动转换成立Drop:离开作用域时自动清理资源(RAII)CoerceUnsized/DispatchFromDyn(了解即可):Box<T>到Box<dyn Trait>的不定大小转换等
要理解为什么 Box 或 String 是智能指针,必须先看它们背后的两个关键特征。智能指针本质上是一个实现了 Deref 和 Drop 的结构体。
A. Deref 特征:让结构体“像”指针
普通的结构体不能被解引用(即不能用 *)。实现了 Deref 之后,智能指针就可以像普通引用一样工作。
- 解引用强制转换 (Deref Coercion):这是
Rust的魔法。如果一个函数需要&str参数,你传给它&String(String实现了Deref),Rust会自动帮你转换。
use std::ops::Deref;
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
// 实现 Deref 告诉编译器:当我对 MyBox 使用 * 时,返回内部的那个值
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &T {
&self.0
}
}
fn main() {
let x = 5;
let y = MyBox::new(x);
assert_eq!(5, x);
assert_eq!(5, *y); // 这里的 *y 实际上执行的是 *(y.deref())
println!("{}", *y);
}
B. Drop 特征:自动清理的“析构函数”
Drop 特征允许你自定义:当一个变量离开作用域时该发生什么。对于智能指针,这通常意味着释放它所拥有的堆内存。
- 自动调用:你不需要手动调用
drop,Rust 会自动在变量生命周期结束时插入清理代码。 - 防止泄漏:有了
Drop,Rust 确保了即便程序在中间出错退出,堆内存也会被正确回收。
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("正在清理数据: {}!", self.data);
}
}
fn main() {
let c = CustomSmartPointer { data: String::from("我的数据") };
let d = CustomSmartPointer { data: String::from("其他数据") };
println!("智能指针已创建。");
// 函数结束时,d 先被清理,c 后被清理(先进后出)
}
智能指针通过 Deref 让我们能方便地访问数据,通过 Drop 让我们不再担心内存回收。
1. Box<T>:堆分配 & 递归类型
你要会的点:
- 什么时候需要
Box- 把值放到堆上(存储实际的数据
T),而在栈(存储指针地址,64 位系统通常是8字节)上仅保留一个指向堆数据的指针 - 处理 递归类型 (编译期需要知道每个类型占用多少内存空间–如:链表)
- 作为 trait object 的持有者:当你需要一个“实现了某个特征的类型”而不是具体类型时,通常使用
Box<dyn Trait> - 转移大数据所有权,如果你有一个非常大的结构体或数组,将其作为参数传递给函数时,如果不使用指针,
Rust默认会进行栈拷贝,这非常消耗性能。
- 把值放到堆上(存储实际的数据
- 所有权语义 :
Box<T>独占所有权,同一时间只能有一个Box指向该堆数据,移动后原变量不可用 - 解引用与方法调用 :
Box<T>自动Deref到T
示例:递归类型(链表)
enum List {
Cons(i32, List), // 错误:List 包含 List,会导致无限大小
Nil,
}编译器会报错,因为 Cons 变体包含另一个 List,这会形成无限递归,编译器无法计算 List 结构的大小。解决方案: 使用Box 智能指针,将递归类型“在堆上间接存储”,List本身就有固定大小了。
// 递归 enum:如果没有 Box,编译器无法在编译期知道 List 的大小。
// Box<List> 让递归“在堆上间接存储”,List 本身就有固定大小了。
#[derive(Debug)]
enum List {
Cons(i32, Box<List>),//Cons 占用:一个 i32 的空间 + 一个指针的空间
Nil,
}
impl List {
fn new() -> Self {
List::Nil
}
fn prepend(self, v: i32) -> Self {
List::Cons(v, Box::new(self))
}
fn len(&self) -> usize {
match self {
List::Cons(_, next) => 1 + next.len(),
List::Nil => 0,
}
}
}
fn main() {
let list = List::new().prepend(3).prepend(2).prepend(1);
println!("{list:?}");
println!("len = {}", list.len());
}示例:返回 trait object(动态分发)
trait Draw {
fn draw(&self);
}
struct Circle {r: f32}
impl Draw for Circle {
fn draw(&self) {
println!("Circle radius = {}", self.r);
}
}
struct Square {side: f32}
impl Draw for Square {
fn draw(&self) {
println!("Square side = {}", self.side);
}
}
// 返回 Box<dyn Draw>:调用者只知道“它能 draw”,不关心具体类型。
// 这会使用动态分发(vtable)。
fn make_shape(kind: &str) -> Box<dyn Draw> {
match kind {
"circle" => Box::new(Circle { r: 2.0 }),
_ => Box::new(Square { side: 3.0 }),
}
}
fn main() {
let s1 = make_shape("circle");
let s2 = make_shape("square");
s1.draw();
s2.draw();
}2. Rc<T>:单线程引用计数共享所有权
在 Rust 的所有权规则中,通常一个值只能有一个所有者。但在某些复杂的应用场景中(例如图结构、社交网络或共享配置),一个数据可能需要被多个不同的部分共同拥有。这时,Box<T> 的独占所有权就不够用了,我们需要 Rc<T>(Reference Counted引用计数)。
你要会的点:
- 为什么需要 Rc :它允许一个数据拥有多个所有者。它在堆上存储数据,并额外记录一个“引用计数器”,用来统计目前有多少个指针指向这份数据
- 只读共享:
Rc<T>默认只允许你不可变地借用数据。如果你想通过其中一个Rc修改数据,编译器会拒绝(除非配合后面要讲的RefCell)。 - 共享而非拷贝:当你“克隆”一个
Rc<T>时,Rust 并不会在堆上重新分配内存并拷贝数据,而是- 增加引用计数:计数器加 1。
- 拷贝指针地址:在栈上创建一个新的指针指向同一个堆位置。
- 只有当计数器归零时: 堆上的数据才会被真正清理。
- 强引用/弱引用
Rc::clone(&rc)增加强引用计数(不是深拷贝)Weak<T>用于打破环,避免内存泄漏
- 循环引用问题 :
Rc形成环会 泄漏 (计数永远不为 0) - 常用 API:
Rc::new、Rc::clone、Rc::strong_count、Rc::weak_count、Rc::downgrade
示例:共享一段数据
use std::rc::Rc;
fn main() {
// 1. 在堆上创建共享数据,初始计数为 1
let config = Rc::new(String::from("核心配置程序"));
println!("--- 初始状态 ---");
println!("内容: {}", config);
println!("引用计数: {}", Rc::strong_count(&config));
// 2. 共享数据:创建两个新的指针指向同一块堆内存
// Rc::clone 仅增加计数,不会拷贝字符串文本
let user_a = Rc::clone(&config);
let user_b = Rc::clone(&config);
println!("\n--- 共享后 ---");
println!("User A 看到的内容: {}", user_a);
println!("User B 看到的内容: {}", user_b);
println!("当前总引用计数: {}", Rc::strong_count(&config));
// 3. 释放其中一个引用
drop(user_a);
println!("\n--- 释放 User A 后 ---");
println!("剩余引用计数: {}", Rc::strong_count(&config));
}- 内存物理表现:
config、user_a和user_b是三个存储在栈上的指针,它们内部存储的内存地* 址完全相同,都指向堆上的同一个String。 - 内容访问:由于实现了
Deref特征,你可以像使用普通String一样直接打印user_a或user_b。 - 计数变化:每次调用
Rc::clone,计数器加 1;每次指针离开作用域(或被drop),计数器减 1。
强引用 (Strong Reference) 与 弱引用 (Weak Reference)
这是管理 Rc 生命周期的两种手段:
-
强引用 (
Rc<T>):- 行为:使用
Rc::clone(&rc)会增加强引用计数。 - 本质:它不是深拷贝(Deep Copy),只是在栈上多了一个指向堆内存的指针,并在堆上把计数器加 1。
- 作用:只要强引用计数大于 0,堆上的数据就绝对不会被销毁。
- 行为:使用
-
弱引用 (
Weak<T>):- 行为:通过
Rc::downgrade(&rc)创建。 - 本质:它会增加弱引用计数,但不影响强引用计数。
- 作用:它不拥有数据的所有权。即便还有 100 个
Weak指针指向数据,只要强引用计数归零,数据依然会被清理。 - 使用:因为数据可能已被销毁,使用前必须通过
weak_ptr.upgrade()将其“升级”回Option<Rc<T>>进行检查。
- 行为:通过
use std::rc::Rc;
fn main() {
// 1. 创建一个强引用 Rc
let strong_ptr = Rc::new(String::from("Rust 智能指针"));
// 2. 从强引用创建一个弱引用
// downgrade 不会增加 strong_count
let weak_ptr = Rc::downgrade(&strong_ptr);
let weak_ptr2 = Rc::downgrade(&strong_ptr);
println!("--- 初始状态 ---");
println!("强引用计数: {}", Rc::strong_count(&strong_ptr)); // 1
println!("弱引用计数: {}", Rc::weak_count(&strong_ptr)); // 2
// 3. 尝试使用弱引用访问数据
// 必须通过 upgrade() 升级为 Option<Rc<T>>
match weak_ptr.upgrade() {
Some(rc) => println!("弱引用升级成功,得到数据: {}", rc),
None => println!("弱引用升级失败,数据已销毁"),
}
// 销毁一个弱引用
drop(weak_ptr2);
println!("销毁一个弱引用后强引用计数: {}", Rc::strong_count(&strong_ptr)); // 1
println!("销毁一个弱引用后弱引用计数: {}", Rc::weak_count(&strong_ptr)); // 1
println!("\n--- 销毁强引用后 ---");
// 4. 手动销毁强引用(模拟离开作用域)
drop(strong_ptr);
// 5. 再次尝试使用弱引用访问数据
// 此时强引用计数为 0,数据已被回收
match weak_ptr.upgrade() {
Some(rc) => println!("弱引用升级成功: {}", rc),
None => println!("弱引用升级失败,数据已销毁"),
}
}Rc 环
循环引用问题:这是Rc 最危险的陷阱。
- 成因:如果两个
Rc指针互相指向对方(例如:节点 A 拥有指向节点 B 的 Rc,而节点 B 也拥有指向节点 A 的 Rc),就会形成一个环。 - 后果:由于环的存在,这两个对象的强引用计数永远至少为 1。当外部作用域结束时,它们无法被清理,导致内存泄漏(
Memory Leak)。 - 解决方案:将其中一条路径改为
Weak<T>。例如:父节点用Rc指向子节点(强引用),而子节点用Weak指向父节点(弱引用)。这样环就被打破了。
由于 Rc<T> 默认是只读的,为了在创建节点后能修改指针指向对方,我们需要配合使用 RefCell<T>演示环形引用。
use std::rc::Rc;
use std::cell::RefCell;
// 定义一个简单的 Node,它可以指向另一个 Node
#[derive(Debug)]
struct Node {
next: RefCell<Option<Rc<Node>>>,
}
impl Drop for Node {
fn drop(&mut self) {
println!("Node 被销毁了!");
}
}
fn main() {
// 1. 创建两个节点 A 和 B
let a = Rc::new(Node { next: RefCell::new(None) });
let b = Rc::new(Node { next: RefCell::new(None) });
println!("--- 建立环之前 ---");
println!("A 的强引用计数: {}", Rc::strong_count(&a)); // 1
println!("B 的强引用计数: {}", Rc::strong_count(&b)); // 1
// 2. 建立环:A 指向 B,B 指向 A
*a.next.borrow_mut() = Some(Rc::clone(&b));
*b.next.borrow_mut() = Some(Rc::clone(&a));
println!("--- 建立环之后 ---");
println!("A 的强引用计数: {}", Rc::strong_count(&a)); // 2
println!("B 的强引用计数: {}", Rc::strong_count(&b)); // 2
// 3. 函数结束前,我们尝试让 a 和 b 离开作用域
println!("--- main 函数即将结束 ---");
}
// 正常情况下,这里应该打印两次 "Node 被销毁了!",但实际上什么都不会打印。笔记:为什么会泄漏?
- 计数器逻辑:当 main 函数结束时,变量 a 和 b 被丢弃。
- a 被丢弃,其对应的堆内存计数从 2 降到 1。
- b 被丢弃,其对应的堆内存计数从 2 降到 1。
- 死循环:堆内存 A 还在等待堆内存 B 释放以便将其计数减为 0;而堆内存 B 也在等待堆内存 A 释放。
- 结果:两个内存块的计数器永远卡在 1,drop 方法永远不会被触发,这块堆内存就泄漏了。
解决方案
use std::cell::RefCell;
use std::rc::{Rc, Weak};
// 一个“父-子”节点结构:
// - 子节点用 Rc 拥有(多个地方可以共享孩子)
// - 父指针用 Weak 指向父(避免形成 Rc 环)
#[derive(Debug)]
struct Node {
value: i32,
parent: RefCell<Weak<Node>>, // Weak<Node>:这是指向父节点的指针, Weak 不增加强引用计数
children: RefCell<Vec<Rc<Node>>>, // children 拥有子节点
}
impl Drop for Node {
fn drop(&mut self) {
println!("Node 被销毁了!");
}
}
fn main() {
let parent = Rc::new(Node {
value: 1,
parent: RefCell::new(Weak::new()),// 初始化时,父节点没有“父”,设为空弱引用
children: RefCell::new(vec![]),// 初始化时,子节点列表为空向量
});//将 Node 实例放入堆中,并返回一个智能指针,此时 parent 的强引用计数为 1,弱计数 = 0
let child = Rc::new(Node {
value: 2,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![]),
});//child 的强计数 = 1,弱计数 = 0
// 建立父 -> 子 的强引用关系
parent.children.borrow_mut().push(Rc::clone(&child));
// 通过 borrow_mut() 获取 Vec 的可变借用,然后把 child 的一个克隆存进去。
// 此时 child 的强引用计数变为 2(一个是变量 child,一个是 parent.children 里的克隆)
// 建立子 -> 父 的弱引用关系(关键:避免环)
*child.parent.borrow_mut() = Rc::downgrade(&parent);
//通过 Rc::downgrade 将 parent 的强引用转为弱引用并存入 child.parent
//parent 的强计数保持为 1。parent 的弱计数变为 1。
println!("parent strong = {}, weak = {}",
Rc::strong_count(&parent),
Rc::weak_count(&parent)
);
println!("child strong = {}, weak = {}",
Rc::strong_count(&child),
Rc::weak_count(&child)
);
// Weak::upgrade:尝试把 Weak 变回 Rc(如果父节点已释放则返回 None)
if let Some(p) = child.parent.borrow().upgrade() {
println!("child's parent value = {}", p.value);
} else {
println!("parent already dropped");
}
}
核心设计:为什么这样设计结构?
在 Rust 中,指针是表示内存地址的类型。为了实现父子双向链接,代码采用了“强弱结合”的策略:
children: RefCell<Vec<Rc<Node>>>(向下强引用):- 父节点需要“拥有”它的子节点,所以使用
Rc<Node>。只要父节点存在,子节点就不会被销毁。
- 父节点需要“拥有”它的子节点,所以使用
parent: RefCell<Weak<Node>>(向上弱引用):- 这是破环关键。子节点只需要“知道”父节点是谁,但不应该“拥有”父节点。
- 使用
Weak<Node>不会增加父节点的强引用计数,因此不会阻止父节点被回收。
RefCell(内部可变性):- 因为节点创建时是孤立的,必须在创建后修改属性(建立连接),所以需要 RefCell 绕过编译期的不可变检查。
| 执行阶段 | Parent 计数 (Strong/Weak) | Child 计数 (Strong/Weak) | 逻辑说明 |
|---|---|---|---|
| 创建后 | 1 / 0 | 1 / 0 | 变量 parent 和 child 各自拥有 1 个所有权 |
| 建立父->子连接 | 1 / 0 | 2 / 0 | parent.children 存了一个 Rc::clone(&child),强计数加 1 |
| 建立子->父连接 | 1 / 1 | 2 / 0 | child.parent 存了一个 downgrade(&parent),仅增加弱计数 |
常用 API 速查表
| API | 功能描述 |
|---|---|
Rc::new(val) | 创建一个新的 Rc 实例,初始强计数为 1。 |
Rc::clone(&rc) | 增加强引用计数,返回新指针。 |
Rc::strong_count(&rc) | 查看当前的强引用数量。 |
Rc::weak_count(&rc) | 查看当前的弱引用数量。 |
Rc::downgrade(&rc) | 获取一个 Weak<T> 指针。 |
weak.upgrade() | 尝试将弱引用转回强引用,返回 Option<Rc<T>>。 |
3. Arc<T>:多线程引用计数共享所有权
如果在多线程环境下使用 Rc<T>,编译器会直接报错,因为 Rc<T> 内部的引用计数是非原子的,无法在多个线程间安全地更新。为了解决这个问题,Rust 提供了 Arc<T>(Atomic Reference Counted 原子引用计数),它允许在多个线程之间安全地共享同一个堆数据的所有权。和 Rc<T> 一样,Arc<T> 默认也是只读的。如果你需要多个线程同时修改数据,你还需要配合下一阶段我们要讲的锁机制(如 Mutex)。
在计算机中,普通的整数加减(如 count += 1)并不是一个不可分割的操作。如果两个线程同时尝试修改 Rc 的计数器,可能会导致计数错误,进而引发提前释放内存或内存泄漏。Arc<T> 使用了 原子操作来更新计数。这是一种硬件层面的特殊指令,能确保在多线程竞争时计数器依然准确。
你要会的点:
Arc= Atomic Rc(线程安全,计数操作是原子的)- 成本:比
Rc更贵(原子操作),单线程场景优先Rc以获得最佳性能 - 常见组合:
Arc<Mutex<T>>、Arc<RwLock<T>> - 线程安全标志:
Rc<T>未实现Send和Sync特征,因此不能跨线程传递Arc<T>实现了Send和Sync(前提是内部的T也是线程安全的),可以在线程间自由穿梭
示例:多线程共享只读
use std::sync::Arc;
use std::thread;
fn main() {
// 1. 创建一个 Arc 指针
let data = Arc::new(String::from("多线程共享数据"));
println!("Arc-data 初始计数: {}", Arc::strong_count(&data));
let mut handles = vec![];
for i in 0..5 {
// 2. 克隆 Arc 指针:这只是增加原子计数,不拷贝字符串本身
let data_clone = Arc::clone(&data);
let handle = thread::spawn(move || {
// 3. 在子线程中使用数据
println!("线程 {} 看到的数据: {}", i, data_clone);
});
handles.push(handle);
}
// 等待所有线程结束
for handle in handles {
handle.join().unwrap();
}
println!("所有线程已完成,最后计数: {}", Arc::strong_count(&data));
}4. 线程安全内部可变性:Mutex<T> / RwLock<T>
在多线程环境下,单靠 Arc<T> 只能解决“谁拥有数据”的问题,但由于 Arc<T> 提供的引用是不可变的,我们无法修改数据。为了在多线程中修改数据,我们需要使用“锁”。
你要会的点:
Mutex<T>:互斥锁,提供独占可变访问(锁守卫MutexGuard)RwLock<T>:读写锁,多读单写- 死锁、锁粒度、持锁时间 (工程上很关键)
- 常见组合:
Arc<Mutex<T>>、Arc<RwLock<T>> - 运行时成本:加锁/解锁、竞争、可能阻塞
示例:Mutex<T> (互斥锁)
Mutex 是 Mutual Exclusion(互斥)的缩写。它保证在任何时刻,只有一个线程可以访问数据。
工作机制:
- 线程尝试通过
.lock()获取锁。 - 如果锁已被占用,线程会阻塞(等待)。
- 获取成功后,返回一个
MutexGuard(智能指针)。 - 自动释放:由于
MutexGuard实现了Drop特征,当它离开作用域时,锁会自动释放,无需手动解锁。
use std::sync::Mutex;
fn main() {
let m = Mutex::new(5);
{
// lock() 返回一个 Result,因为如果另一个线程在持有锁时 panic,锁会变得“中毒”
let mut num = m.lock().unwrap();
*num = 6; // 通过解引用修改内部数据
} // num 离开作用域,锁自动释放
println!("m = {:?}", m);
}示例:RwLock<T> (读写锁)
RwLock 代表 Read-Write Lock。它比 Mutex 更灵活,遵循“多读单写”规则:
- 多读:允许多个线程同时持有只读锁 (
.read())。 - 单写:同一时间只允许一个线程持有写锁 (
.write())。此时不允许任何读锁。
适用场景:适用于“读多写少”的场景,性能通常优于 Mutex。
Mutex<T> 的规则很简单:任何人要用,必须排队。
而 RwLock<T> 引入了“多读”逻辑,这虽然提高了并发效率,但也让逻辑变得复杂:你不能直接把一个读锁“升级”为写锁。你必须先释放读锁,然后再去竞争写锁
use std::sync::{Arc, RwLock};
use std::thread;
use std::time::Duration;
fn main() {
// 1. 使用 Arc 包装 RwLock,实现多线程共享所有权
let lock = Arc::new(RwLock::new(5));
let mut handles = vec![];
// --- 模拟多个读取者 ---
for i in 0..3 {
let lock_clone = Arc::clone(&lock);
let handle = thread::spawn(move || {
// 获取读锁:允许多个线程同时进入此处
let r = lock_clone.read().unwrap();
println!("读者 {} 读取到的值: {}", i, *r);
// 读锁在这里自动释放
});
handles.push(handle);
}
// --- 模拟一个写入者 ---
{
let lock_clone = Arc::clone(&lock);
let handle = thread::spawn(move || {
println!("写入者正在尝试获取写锁...");
// 获取写锁:此时所有读锁和其他写锁都会被阻塞
let mut w = lock_clone.write().unwrap();
*w += 10;
println!("写入者已将值修改为: {}", *w);
// 写锁在这里自动释放
});
handles.push(handle);
}
// 等待所有线程结束
for handle in handles {
handle.join().unwrap();
}
println!("最终结果: {}", *lock.read().unwrap());
}关键细节解析
-
.read().unwrap():- 返回一个
ReadGuard。只要这个 guard 存在,其他线程也可以调用.read()获取读锁。 - 限制:一旦有人持有读锁,任何尝试调用
.write()的线程都会进入睡眠等待状态。
- 返回一个
-
.write().unwrap():- 返回一个
WriteGuard。 - 排他性:只有当没有任何人持有读锁且没有任何人持有写锁时,它才能成功获取。
- 返回一个
-
死锁风险:
- 如果在同一个线程中,你已经持有了读锁,又尝试去获取写锁,会导致死锁。
- 在写操作频繁的场景下,可能会出现“读者饥饿”。
总结对比:Mutex vs RwLock
| 特性 | Mutex<T> | RwLock<T> |
|---|---|---|
| 访问规则 | 一次只能一个线程访问, | 多个读者 OR 一个写者 |
| 内部可变性 | 是(通过锁获取可变引用) | 是(通过写锁获取可变引用) |
| 线程安全 | 是 | 是 |
| 性能 | 简单、开销固定 | 读操作多时性能更好,管理成本略高 |
💡 笔记要点:为什么它们也叫“内部可变性”?
因为即使你只有一个指向 Mutex<T> 的不可变引用 &Mutex<T>,你依然可以通过调用 .lock() 方法来修改其内部包裹的数据。这种“外表不可变,内部可变”的特性正是它们被称为内部可变性的原因。
示例:多线程共享可变(Arc<Mutex<T>>)
核心分工:
- Arc(所有权管理者):解决“谁拥有数据”的问题。它让多个线程可以同时持有指向同一个堆内存的指针
- Mutex(访问权限管理者):解决“谁能修改数据”的问题。它确保即使多个线程都有指针,同一时间也只有一个线程能真正碰到里面的数据
use std::sync::{Arc, Mutex};
use std::thread;
fn main() {
let counter = Arc::new(Mutex::new(0));//最外层是 Arc,给这把锁加上引用计数功能,中间层是 Mutex,给数据加上一把锁
let mut handles = vec![];
for _ in 0..4 {
let c = Arc::clone(&counter);//克隆的是指针地址和计数器,锁和数据始终只有一份
handles.push(thread::spawn(move || {
// lock() 返回一个 guard:guard 活着就持有锁
let mut guard = c.lock().unwrap();
*guard += 1;
// 不需要手动写 unlock(), guard drop 时自动解锁(RAII)
}));
}
for h in handles {
h.join().unwrap();
}
println!("counter = {}", *counter.lock().unwrap()); // 4
}
示例:多线程共享可变(读多写少Arc<RwLock<T>>)
核心分工:
- Arc:解决“谁拥有数据”的问题,确保堆内存地址在所有线程执行完毕前保持有效。
- RwLock:解决“如何高效访问”的问题。它允许 100 个线程同时读取(并发),但只要有 1 个线程在写,其他人都必须等待(排他)。
use std::sync::{Arc, RwLock};
use std::thread;
use std::time::Duration;
fn main() {
// 1. 初始化数据,Arc 负责跨线程共享,RwLock 负责并发权限
let data = Arc::new(RwLock::new(0));
let mut handles = vec![];
let start_time = std::time::Instant::now();
// 2. 开启 5 个读者线程
for i in 0..5 {
let d = Arc::clone(&data);
handles.push(thread::spawn(move || {
// 获取读锁:注意!多个线程可以同时成功获取读锁
let _guard = d.read().unwrap();
println!("读者 {} 正在读取...", i);
// 模拟一个耗时的读取操作(1秒)
thread::sleep(Duration::from_secs(1));
println!("读者 {} 读取完毕", i);
}));
}
// 3. 开启 1 个写者线程
let d_writer = Arc::clone(&data);
handles.push(thread::spawn(move || {
// 模拟等待一段时间再写,确保读者们已经先拿到了锁
thread::sleep(Duration::from_millis(500));
println!("写者:尝试获取写锁(会被阻塞,直到所有读者读完)...");
// 获取写锁:必须等所有读锁释放
let mut w = d_writer.write().unwrap();
*w += 1;
println!("写者:修改完毕!");
}));
for h in handles {
h.join().unwrap();
}
println!("--- 总耗时: {:?} ---", start_time.elapsed());
}代码逻辑深度拆解
- 读锁并发 (
.read().unwrap())- 当
reader1调用read()时,如果此时没有写线程,它会立即获得ReadGuard。 - 优势:如果有
reader2、reader3同时进来,只要当前没有线程持有“写锁”, 它们都可以获取读锁。这比Mutex快得多,因为Mutex会强制让读者也排队。
- 当
- 写锁独占 (
.write().unwrap()):- 当
writer调用write()时,写锁具有排他性, 它必须等待所有正在读取的线程释放读锁,且没有其他写线程在工作。反之,只要有任何读锁未释放,写锁获取也会被阻塞。
- 当
5. Cell<T>:Copy 类型的轻量内部可变性
在掌握了 Rc 和 Arc 之后,你可能已经发现它们默认是不可变共享的。为了在“不可变”的外壳下修改数据,我们需要内部可变性(Interior Mutability)。
在 Rust 中,如果你使用普通引用,最怕的是:“我手里拿着指向数据的指针,结果别人把数据改了/删了,导致我手里的指针失效”。
但 Cell 完美避开了这个问题,因为它禁止你获取内部数据的指针:
- 没有借用:你调用
c.get()时,它直接给你一个全新的副本。你手里的副本和Cell里面的原始数据已经没关系了。 - 随便覆盖:既然谁也拿不到指向
Cell内部的指针,那么无论你调用多少次set,都只是在修改那一块内存的值,不会破坏任何人的指针(因为根本没人持有指针)。
你要会的点:
Cell<T>主要用于实现了Copy特征的类型(如i32, bool, f64等简单类型)Cell的操作逻辑不是“借用”,而是“值拷贝”。它不会给你内部数据的引用,而是让你把值取出来或存进去。- 与其它智能指针不同,
Cell不提供.borrow()或.borrow_mut()方法,只有两个核心动作:.get():返回内部值的一个全新的副本(Copy).set(value):将新值拷贝进去,覆盖旧值
- 应用场景:
- 简单标志位:在结构体内部存储一些状态标记(如
is_valid: Cell<bool>),即使结构体是以不可变引用的形式传递,也能随时更新这些标记。 - 性能敏感场景:如果你只需要操作简单的数字或布尔值,且不需要获取它们的引用,选
Cell而不是RefCell。
- 简单标志位:在结构体内部存储一些状态标记(如
use std::cell::Cell;
fn main() {
// 即使变量 c 本身没有声明为 mut
let c = Cell::new(10);
// 我们可以通过不可变引用修改它的值
let c_ref1 = &c;
let c_ref2 = &c;
c_ref1.set(20);
c_ref2.set(30);
println!("当前值: {}", c.get()); // 输出 30
}6. RefCell<T>:运行时借用检查(内部可变性)
如果说 Cell<T> 是通过“不给你指针”来保证安全,那么 RefCell<T>(Reference Cell) 就是通过雇佣一个运行时保安来让你安全地持有指针。
你要会的点:
- 用于那些不方便拷贝(非
Copy类型,比如Vec或自定义结构体),且你需要获取其引用的场景 - 内部可变性(Interior Mutability) :即便外面是不可变绑定,也能在内部修改
- 借用规则从编译时延后到运行时:
borrow()获取一个不可变引用, 得到Ref<T>borrow_mut()获取一个可变引用, 得到RefMut<T>- 在程序运行时,RefCell 内部会维护一个计数器来记录当前的借用状态,运行时违反了规则则会 panic
- 与
Rc组合:Rc<RefCell<T>>是单线程常见共享可变方案
示例:共享 + 可变(单线程)
use std::cell::RefCell;
fn main() {
// 数据包裹在 RefCell 中
let data = RefCell::new(vec![1, 2, 3]);
// 即使 data 是不可变的,我们也能获取可变借用
{
let mut mut_ref = data.borrow_mut();
mut_ref.push(4);
} // mut_ref 在这里离开作用域,借用标记被释放
// 获取两个不可变借用
let ref1 = data.borrow();
let ref2 = data.borrow();
println!("数据内容: {:?}", ref1);
}为什么会 Panic?(违反规则的后果)
如果你尝试在同一个作用域内同时进行不可变和可变借用,RefCell 就会报错:
let data = RefCell::new(5);
let r1 = data.borrow(); // 运行时:不可变借用计数 +1
let r2 = data.borrow_mut(); // 运行时:发现已有不可变借用,直接 PANIC!Cell<T> 与 RefCell<T> 的深度对比
这是笔记中最重要的部分:
| 特性 | Cell<T> | RefCell<T> |
|---|---|---|
| 适用类型 | 实现了 Copy 的简单类型 | 任何类型(通常是较大的对象) |
| 获取方式 | 返回值的副本(.get()) | 返回数据的引用(.borrow()) |
| 性能开销 | 零开销(仅内存拷贝) | 有开销(运行时维护借用计数) |
| 安全性 | 编译时安全(无引用) | 运行时可能 Panic |
| 线程安全 | 不安全 (!Sync) | 不安全 (!Sync) |
💡 为什么需要 RefCell?
最常见的场景是:你实现了一个 Trait,而该 Trait 的方法签名要求使用不可变引用 &self,但你的具体实现却需要修改内部状态(比如缓存、日志记录等)。
总结一句话
Cell是“搬家”(拷贝值),RefCell是“登记处”(在运行时盯着谁拿了钥匙,违规就报警)。
Rc<RefCell<T>>:单线程共享 + 可变
这是 Rust 单线程开发中最强大的组合拳。如果你理解了 Rc(解决所有权共享)和 RefCell(解决不可变外壳下的修改),那么把它们套在一起就得到了:一个可以被多个地方同时持有、且每个地方都能修改的“共享变量”。
在 Rust中,指针是表示内存地址的类型。为了实现“多处读写”这种在其他语言中很常见的行为,我们需要这种“套娃”结构。
核心逻辑
- 外层
Rc<T>**:负责共享**。它允许多个变量持有指向同一块堆内存的指针,解决了“谁能拿到这块内存”的问题。 - 内层
RefCell<T>**:负责修改**。它允许你在只有Rc提供的不可变引用的情况下,通过运行时检查来修改内部数据。
当你创建 let x = Rc::new(RefCell::new(5)) 时,内存中发生了以下情况:
- 栈上:有一个
Rc指针 - 堆上:分配了一块空间,包含
Rc的引用计数器RefCell的借用状态标志位- 实际的数据
T。
代码示例:共享计数器
use std::rc::Rc;
use std::cell::RefCell;
fn main() {
// 1. 创建共享的可变数据
let shared_data = Rc::new(RefCell::new(vec![1, 2, 3]));
// 2. 克隆 Rc 指针(增加强引用计数)
let shared_data_clone = Rc::clone(&shared_data);
// 3. 在一处修改
{
let mut mut_ref = shared_data.borrow_mut();
mut_ref.push(4);
}
// 4. 在另一处读取,发现数据已经变了
println!("克隆端看到的数据: {:?}", shared_data_clone.borrow());
// 输出: [1, 2, 3, 4]
}
深度对比:单线程 vs 多线程
这个组合有一个完美的“多线程对应版本”,请务必记在笔记中对比:
| 场景 | 工具组合 | 逻辑 |
|---|---|---|
| 单线程 | Rc<RefCell<T>> | 引用计数 + 运行时借用检查 |
| 多线程 | Arc<Mutex<T>> | 原子计数 + 互斥锁 |
风险警示:运行时崩溃
虽然这个组合很强,但它保留了 RefCell 的风险:
- 如果你在同一个线程中,通过
shared_data.borrow()拿到了一个引用还没放手,又尝试用shared_data_clone.borrow_mut()去修改,程序会直接 Panic。 - 它依然不是线程安全的,不能跨线程传递。
7. Cow<'a, T>:写时克隆(Copy-On-Write)
这是 Rust 中一个非常“聪明”且能显著提升性能的智能指针。Cow 的全称是 Copy-On-Write(写时克隆)。它的核心思想是:不到万不得已,绝不分配内存。将内存分配推迟到真正发生修改的那一刻。
核心定义
Cow 是一个枚举类型,包含两个变体:Borrowed(&'a T) 和 Owned(T::Owned)。它允许你以一种统一的方式处理借用的数据和拥有的数据。
Borrowed(&'a T):持有数据的只读引用Owned(T::Owned):持有数据的所有权(通常在堆上)
懒惰是美德
- 初始状态: 当你创建一个
Cow时,它通常从Borrowed开始。这不需要分配新内存,开销极小。 - 读取数据:当你只需要读取时,它保持 Borrowed 状态,性能损耗为
O(1)。 - 修改数据:当你调用
.to_mut()尝试修改数据时,Cow会检查:如果已经是Owned,直接返回引用。如果是Borrowed,此时才会执行克隆(Clone),将数据变为Owned,然后再让你修改。
你要会的点:
- 表示“要么借用,要么拥有”
- 读操作零拷贝,写操作才会
to_mut()触发克隆 - 常见场景:字符串处理、API 既接受
&str又能返回String的优化
use std::borrow::Cow;
// 如果不需要修改,就借用输入(零拷贝);
// 如果需要修改,再转成拥有的 String。
fn normalize(s: &str) -> Cow<'_, str> {
if s.contains(' ') {
// 需要修改:分配新 String(Owned)
Cow::Owned(s.replace(' ', "_"))
} else {
// 不需要修改:直接借用(Borrowed)
Cow::Borrowed(s)
}
}
fn main() {
let a = normalize("hello");
let b = normalize("hello world");
println!("a = {}", a);
println!("b = {}", b);
}8. Pin<P>:禁止被移动(自引用/异步)
这是 Rust 中最“玄学”但也最底层、最重要的智能指针之一。如果说 Box 是为了放进堆里,那么 Pin 就是为了锁死内存地址。
Define
A. 核心危机:自引用结构 (Self-referential Structs)
在 Rust 中,几乎所有类型都是可以移动的(Move)。这意味着如果你把一个变量传给另一个函数,它的内存地址可能会发生改变。但在某些特殊场景下,这种“移动”会导致程序崩溃。
想象一个结构体,它的一个字段是指向另一个字段的指针:
struct SelfRef {
data: String,
ptr: *const String, // 这个指针指向同一个结构体里的 data
}
- 初始状态:
ptr记录了data在内存中的地址(比如0x100)。 - 发生移动:如果你把这个结构体移动到堆上或者传给另一个线程,整个结构体的内存地址变了(变成了
0x200)。 - 结果:
data的新地址是0x200,但ptr仍然指着旧地址0x100。指针失效了! 这会导致未定义行为。
B. Pin<P> 的作用
Pin 的作用就是:给指针加一个约束,保证它指向的数据在内存中永远不会被移动。
- 一旦数据被
Pin住,你无法再通过mem::swap或移动所有权等方式改变它的物理位置。 - 它主要配合
P(通常是Box或引用)使用,形成Pin<Box<T>>或Pin<&mut T>。
C. 为什么异步(Async/Await)必须用它?
这是 Pin 最主要的应用场景。
- 当你写
async块时,编译器会将其转换为一个状态机(实现了Futuretrait)。 - 这个状态机内部经常包含自引用(例如:一个局部变量被引用后跨越了
.await点)。 - 因此,
Future的poll方法签名必须是fn poll(self: Pin<&mut Self>, ...)。没有Pin,异步代码就无法保证内存安全。
D. Unpin 特征:谁可以豁免?
并不是所有东西都需要被“锁死”。Rust 定义了一个标记特征 Unpin:
Unpin类型:绝大多数普通类型(如i32,String,Box)。它们即便被移动也是安全的。对于这些类型,Pin<P>没有任何实际限制,可以随意拿回可变引用。!Unpin类型:不能被移动的类型(如异步生成的Future、自引用结构)。它们必须被Pin保护,否则编译器会阻止某些危险操作。
如何通俗理解 Pin?
- 普通指针:像一张写着地址的便签。你可以把便签传来传去,房子(数据)也可能搬家。
Pin指针:像一颗钉子。它不仅告诉你地址,还将房子死死地钉在原地,不准搬家,直到房子被拆除(Drop)为止。
选型指南
- 如果你的数据不包含指向自身的指针,**不需要
Pin**。 - 如果你在手写复杂的
Future或者构建自引用底层库,**必须用Pin**。
这个示例只是让你看到 Pin<Box<T>>的写法;真正需要 Pin 的场景主要在 async/Future 或自引用结构里。
use std::pin::Pin;
fn main() {
let x = Box::new(123);
// Pin<Box<T>>:把堆上的 T “固定住”,承诺之后不会再移动它的内存地址
let pinned: Pin<Box<i32>> = Box::pin(*x);
// 访问内部值:as_ref 得到 Pin<&T>,get_ref 拿到 &T
let r: &i32 = pinned.as_ref().get_ref();
println!("pinned value = {}", r);
}9. Box<dyn Trait> / Rc<dyn Trait>:trait object 与动态分发
这是 Rust 智能指针系列的最后一项核心应用。如果你需要处理不同类型但实现了相同特征的对象(例如一个数组里既有“圆形”又有“正方形”),你就必须用到 Box<dyn Trait> 或 Rc<dyn Trait>。
在 Rust 中,指针是表示内存地址的类型。由于不同类型的大小不同,我们无法直接在栈上存储“某个特征”,必须通过智能指针将其包装成 Trait Object。
你要会的点:
- 静态分发(泛型) vs 动态分发(trait object)
- 对象安全(object safety)限制:哪些 trait 能变成
dyn Trait - fat pointer(数据指针 + vtable),大小/性能直觉
前置知识
A. 为什么必须用 Box 或 Rc?
特征(Trait)本身是 DST (Dynamically Sized Type),即“动态大小类型”。
- 编译器在编译时不知道具体是哪个结构体实现了该特征,因此不知道它占用多少内存。
- 解决方案:将对象放入堆中。
Box<dyn Trait>的大小是固定的(指针大小),无论堆上的对象实际有多大。
B. 物理结构:胖指针 (Fat Pointer)
当你使用 Box<dyn Trait> 时,这个指针在栈上占用 2 个单元(通常是 16 字节):
- 数据指针:指向堆内存中具体的对象数据。
- vtable 指针:指向一个“虚函数表”。表中记录了该特定类型实现该 Trait 的方法地址。
C. 静态分发 vs 动态分发
| 特性 | 静态分发 (Generics <T: Trait>) | 动态分发 (dyn Trait) |
|---|---|---|
| 原理 | 编译时为每种类型生成一份代码(单态化)。 | 运行时通过 vtable 查找函数地址。 |
| 性能 | 极快。编译器可以进行内联优化。 | 略慢。存在指针跳转开销,无法内联。 |
| 灵活性 | 集合中只能存同一种类型。 | 极高。集合中可以存多种不同类型。 |
D. 代码示例:不同类型的“绘图”
trait Draw {
fn draw(&self);
}
struct Button { width: u32 }
impl Draw for Button {
fn draw(&self) { println!("渲染按钮,宽度: {}", self.width); }
}
struct Image { url: String }
impl Draw for Image {
fn draw(&self) { println!("渲染图片,源自: {}", self.url); }
}
fn main() {
// 使用 Box<dyn Draw> 存储不同类型的对象
let components: Vec<Box<dyn Draw>> = vec![
Box::new(Button { width: 100 }),
Box::new(Image { url: String::from("logo.png") }),
];
for comp in components {
comp.draw(); // 运行时动态分发:查表并调用对应方法
}
}
什么时候用 Box<dyn Trait>?
- 异质集合:当你需要一个
Vec存储多种实现了相同接口的类型时。 - 解耦:当你不想在函数签名中暴露具体类型,只想表达“只要实现了这个特征就行”时。
- 减少编译时间:泛型会导致代码膨胀(单态化),而
dyn Trait只有一份代码,可以缩短大型项目的编译时间。
10. 自定义智能指针(进阶)
你要会的点:
- 如何实现自己的指针类型:
- 实现
Deref/DerefMut,让它像引用一样用 - 实现
Drop,在释放时执行资源回收
- 实现
- RAII 模式(文件句柄、网络连接、锁守卫等)
PhantomData(用于告诉编译器“我逻辑上拥有/借用某个 T”,影响 drop check/variance)——偏高级,但智能指针写多了会遇到
要自定义一个智能指针,本质上是创建一个结构体,并为它实现两个核心特征(Trait):Deref 和 Drop。在 Rust 中,正是这两个特征让普通结构体拥有了“像指针一样工作”和“自动管理资源”的超能力。
1. 自定义智能指针的核心公式
Deref特征:允许你通过解引用操作符(*)访问内部数据。Drop特征:定义当指针离开作用域时该执行什么清理逻辑(例如释放内存、关闭文件、打印日志)。
2. 实战演练:创建一个简单的 MyBox<T>
我们将模仿 Box<T> 的行为,创建一个能包裹数据的智能指针。
use std::ops::Deref;
//A. 定义结构体
struct MyBox<T>(T); // 元组结构体
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
//B. 实现 `Deref` (让它能被 `*` 解引用)
//如果不实现 `Deref`,编译器就不知道执行 `*my_box` 时该返回什么。
impl<T> Deref for MyBox<T> {
type Target = T; // 关联类型,指定解引用后得到的类型
fn deref(&self) -> &Self::Target {
&self.0 // 返回元组中的第一个元素引用
}
}
//C. 实现 `Drop` (赋予它自动清理的能力)
impl<T> Drop for MyBox<T> {
fn drop(&mut self) {
println!("MyBox 指针被销毁了,资源已释放!");
}
}
fn main() {
let x = 5;
let y = MyBox::new(x);
assert_eq!(5, x);
assert_eq!(5, *y); // 这里触发了 y.deref()
println!("y 的值是: {}", *y);
} // y 在这里离开作用域,触发 drop() 方法3. 深度原理:Deref 强制转换 (Deref Coercion)
这是 Rust 智能指针极其好用的秘密武器。Deref 强制转换可以将一个实现了 Deref 的类型的引用转换为它内部类型的引用。
例子:
如果你有一个 MyBox<String>,Rust 可以自动将其转换为 &str:
fn hello(name: &str) {
println!("Hello, {}!", name);
}
fn main() {
let m = MyBox::new(String::from("Rust"));
// &m 是 &MyBox<String>
// Rust 自动调用 deref 将其变为 &String
// String 也实现了 Deref,再次调用 deref 变为 &str
hello(&m);
}11. 选择指南
| 需求场景 | 推荐指针 | 备注 |
|---|---|---|
| 堆分配、大数据传递、递归类型 | Box<T> | 唯一所有权,开销最低。 |
| 单线程、多处共享只读数据 | Rc<T> | 引用计数。 |
| 多线程、多处共享只读数据 | Arc<T> | 原子引用计数,线程安全。 |
| 单线程、小对象内部可变 (Copy类型) | Cell<T> | get/set 值拷贝。 |
| 单线程、大对象内部可变 (非Copy) | RefCell<T> | 运行时借用检查。 |
| 单线程、多所有权共享且可修改 | Rc<RefCell<T>> | 经典套娃组合。 |
| 多线程、共享且可修改 | Arc<Mutex<T>> | 并发黄金搭档。 |
| 避免循环引用、内存泄漏 | Weak<T> | 配合 Rc 或 Arc 使用。 |
| 性能优化、按需克隆 | Cow<T> | 写时克隆。 |
| 异步编程、锁死内存地址 | Pin<P> | 防止自引用结构移动。 |
生命周期
一、基础概念
1. 生命周期的本质:悬空引用预防机制
生命周期(Lifetimes)是 Rust 编译器用来确保引用在有效范围内的机制。它用于防止悬空引用(Dangling References)问题,确保引用指向的数据在引用存在期间不会被销毁。例如:
// 错误示例:试图返回局部变量引用
// 报错:returns a reference to data owned by the current function
/*
fn get_data() -> &String {
let s = String::from("Hello");
&s // s 在函数结束时被销毁,返回引用会导致悬空指针
}
*/
// 正确方案 1:转移所有权(最常用)
fn get_data_owned() -> String {
String::from("Hello")
}
// 正确方案 2:传入引用,返回引用(建立生命周期关联)
fn identity<'a>(input: &'a String) -> &'a String {
input
}在 Rust 中,借用检查器会确保引用的有效性,防止程序出现不安全的悬空引用。
2. 借用检查器(Borrow Checker)的工作原理
借用检查器通过分析变量的生命周期,确保引用始终在有效范围内 作用域(数据源) - 生命周期(引用) >= 0。它会验证以下规则:
- 不允许在拥有可变借用时同时存在不可变借用。
- 不允许在不可变借用存在时修改数据。
3. 生命周期与作用域的关系
生命周期通常与作用域(scope)密切相关,作用域定义了一个变量或引用的有效区域,而生命周期则追踪这个变量或引用的生存时间,避免悬空引用。每个引用都会有一个生命周期,与它指向的数据的生命周期匹配。
fn main() {
let mut x = 10;
let r;
{
let y = &x; // y 的生命周期在此作用域内
r = y; // 将 y 赋值给 r
} // y 离开了作用域,但 r 还在
// println!("{}", r); // 如果取消注释会报错:因为 r 指向的内容寿命不足
x = 20; // 此时修改 x 是安全的,因为旧的借用 r 已经无效了
println!("x: {}", x);
}4. 显式标注语法('a)
显式标注并不是为了“告诉编译器这个引用活多久”,而是为了建立输入和输出之间的一致性约束。
fn longest<'a>(s1: &'a str, s2: &'a str) -> &'a str {
if s1.len() > s2.len() {
s1
} else {
s2
}
}
fn main() {
let a = String::from("Hello World");
let b = String::from("Hello");
let longest = longest(&a, &b);
println!("longest: {}", longest);
}此处 'a 是生命周期标注,表示函数返回的引用与传入参数的生命周期相同。
二、生命周期省略规则(Lifetime Elision)
为了避免开发者在所有地方都手动书写 'a,Rust 编译器内置了一套确定性的模式。如果代码符合这些模式,编译器会自动补全生命周期。这被称为“省略”,但生命周期依然客观存在,只是被编译器隐藏了。
1. 输入生命周期与输出生命周期
Rust 提供了生命周期省略规则,简化函数签名。当函数参数和返回值都没有生命周期标注时,编译器会推导出生命周期。
- 输入生命周期 (
Input Lifetimes):函数参数中的引用。 - 输出生命周期 (
Output Lifetimes):函数返回值中的引用。
误以为“省略”意味着“没有约束”?
//fn first_word<'a>(s: &'a str) -> &'a str { ... } // 补全后
fn first_word(s: &str) -> &str {
s.split_whitespace().next().unwrap()
}
/* // 错误示例:编译器无法应用省略规则,因为没有输入引用作为来源
fn produce_str() -> &str {
let s = String::from("hello");
&s // 依然会报错:returns a reference to data owned by the current function
}
*/
fn main() {
let a = String::from("Hello World");
let first = first_word(&a);
println!("first: {}", first);
}编译器会推导出 first_word函数的生命周期。
2. 函数生命周期省略的三大准则
编译器按照以下顺序尝试推导,如果推导失败(即不符合这三条),则要求手动标注:
- 规则一:每一个是引用的参数都有它自己的生命周期参数(例如
fn(x: &'a i32, y: &'b i32))。 - 规则二:如果只有一个输入生命周期参数,那么该生命周期被赋给所有输出生命周期参数。
- 规则三:如果有多个输入生命周期参数,但其中一个是 &self 或 &mut self,那么 self 的生命周期被赋给所有输出生命周期参数。
// 实践场景:编译器会报错,因为不符合规则二(有两个输入)
/*
fn pick_one(x: &str, y: &str) -> &str {
x
}
*/
// 正确方案:手动介入,指明关联
fn pick_one<'a>(x: &'a str, _y: &str) -> &'a str {
x
}3. 方法签名中的生命周期省略(&self 与 &mut self)
在 Rust 的面向对象风格代码中,返回的引用通常是结构体自身的一部分。在方法中,返回值的生命周期默认与 self 绑定,这意味着只要你手里拿着方法返回的引用,你就一直持有对整个结构体的借用。
struct Level {
content: String,
}
impl Level {
// 自动应用规则三:fn get_content<'a>(&'a self) -> &'a str
fn get_content(&self) -> &str {
&self.content
}
}
fn main() {
let mut lv = Level { content: "Rust".into() };
let res = lv.get_content(); // res 绑定了 lv 的生命周期
// lv.content.push_str("!"); // 报错:无法修改 lv,因为 res 还在引用它
println!("{}", res);
lv.content.push_str("!"); // 成功:res 在 println 之后不再使用,借用结束(NLL特性)
}三、函数中的生命周期
函数签名中的生命周期标注是对编译器的一种“承诺”。它并不改变引用的实际寿命,而是描述了输入引用的寿命如何“流向”输出引用。当编译器无法通过省略规则自动推导时,我们需要手动精确定义这种流动关系。
1. 单个与多个生命周期参数
函数可以接收多个生命周期参数,每个生命周期都需要进行标注。例如:
fn example<'a, 'b>(x: &'a str, y: &'b str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}如果你给所有参数都标注同一个 'a,编译器会强制将它们关联在一起,取其中的**交集(即最短的那个寿命)**作为结果。这有时会导致过度限制。如果两个输入参数之间没有逻辑上的关联,使用不同的生命周期标注可以给调用者更大的灵活性。
// 情况 A:使用单个生命周期。x 和 y 被锁定在同一个寿命中。
fn pick_x<'a>(x: &'a str, y: &'a str) -> &'a str {
x
}
// 情况 B:使用多个生命周期。返回值只与 x 关联,与 y 无关。
fn pick_x_flexible<'a, 'b>(x: &'a str, y: &'b str) -> &'a str {
x
}
fn main() {
let x_long = String::from("Long lived");
let res;
{
let y_short = String::from("Short");
// 如果使用 pick_x(x_long, y_short),res 会因为 y_short 而被缩短寿命,报错。
// 使用 flexible 版本,res 的寿命只取决于 x_long。
res = pick_x_flexible(&x_long, &y_short);
} // y_short 在这里销毁,但 res 依然有效
println!("res: {}", res);
}2. 多个引用输入的约束关系
多个引用参数之间的生命周期关系需要通过显式标注进行约束。有时我们需要表达“引用的引用”或者“参数 A 必须活得比参数 B 久”。这通常通过生命周期约束(Bounds)实现,例如 'a: 'b(读作:’a 至少活得和 ’b 一样久)。
当你需要把一个引用存入另一个引用的目标位置时(例如在处理缓存或修改器时)。
// 需求:将 source 的内容更新到 target 指向的地方
// 约束:'a: 'b 表示 source 的寿命必须覆盖 target 的寿命
fn update_and_return<'a, 'b>(target: &mut &'b str, source: &'a str)
where 'a: 'b
{
*target = source; // 只有 source 活得够久,赋值才是安全的
}
fn main() {
// 1. target 在外层作用域,它的生命周期很长
let mut target: &str = "I am long-lived";
{
// 2. source 在内层作用域,它在大括号结束时就会被销毁
let source_data = String::from("I am short-lived");
let source_ref = &source_data;
// 3. 尝试赋值:
// 这里的 'a 是内部作用域,'b 是外部作用域。
// 显然 'a 并不比 'b 活得久,违反了 'a: 'b。
// 编译器报错:`source_data` does not live long enough
update_and_return(&mut target, source_ref);
}
// 4. 危险:如果上面不报错,这里打印 target 就会访问到已经死掉的内存!
println!("{}", target);
}当内容和容器在同一个作用域,或者内容活得更久时,代码是安全的。
fn update_and_return<'a, 'b>(target: &mut &'b str, source: &'a str)
where 'a: 'b
{
*target = source;
}
fn main() {
// 1. source 先创建,它的生命周期最长
let source_data = String::from("I live long enough");
let source_ref = &source_data;
// 2. target 后创建(或在同一层)
let mut target: &str = "initial";
// 3. 赋值:
// 此时 source_ref 的寿命 ('a) 覆盖了 target 的寿命 ('b)。
// 满足 'a: 'b,安全通过!
update_and_return(&mut target, source_ref);
// 4. 这里的 target 指向 source_data,而 source_data 还没死,安全。
println!("{}", target);
}3. 返回引用的生命周期标注要求
返回引用时,必须明确标注返回值生命周期的关系。
- 来源合法性:返回的引用必须来源于输入参数。
- 绝对禁止:严禁返回指向函数内局部变量的引用。
struct Config {
env: String,
port: u32,
}
// 实践:从结构体引用中提取内部字段的引用
// 这里的 'a 建立了“整体”与“部分”的寿命契约
fn get_env_ref<'a>(config: &'a Config) -> &'a str {
&config.env
}
// 错误尝试:如果你试图返回一个跟输入无关的引用
/*
fn mistake<'a>(input: &'a str) -> &'a str {
let s = String::from("I am local");
&s // 即使标注了 'a,编译器也会发现 s 的实际寿命达不到 'a 的要求
}
*/四、结构体与枚举中的生命周期
当一个结构体或枚举中包含引用时,这个结构体本身就失去了“独立性”。它变成了一个从属品,其寿命被强制绑定到它所指向的数据上。Rust 要求必须在类型定义上显式标注寿命,以提醒调用者:这个结构体不能比它内部的引用活得久。
1. 持有引用的结构体定义
当结构体包含引用时,需要显式标注结构体的生命周期。如果你试图构建一个结构体来存放解析后的数据(如 User 持有 &str 名字),你必须保证 User 在使用时,原始字符串还没被销毁。
struct User<'a> {
name: &'a str, // 结构体持有引用
}
/* fn create_user() -> User<'_> {
let name = String::from("Alice");
let user = User { name: &name };
user // 报错:name 在函数结束时销毁,user 的引用失效
}
*/
fn main() {
let raw_data = String::from("Alice-25-Engineer");
// 假设我们解析这段字符串
let name_slice = &raw_data[0..5];
let user = User { name: name_slice };
println!("User name: {}", user.name);
} // user 和 raw_data 在此处一起安全销毁2. 持有引用的枚举定义
和结构体类似,枚举类型也需要为引用添加生命周期标注。 枚举的生命周期规则与结构体完全一致。只要有一个变体(Variant)持有了引用,整个枚举就必须带有生命周期标注。
enum Message<'a> {
Quit,
Move { x: i32, y: i32 },
Write(&'a str), // 只要这里有引用,上面定义就得加 <'a>
}3. impl 块中的生命周期声明
在 impl 块中,生命周期需要明确标注与结构体的关系。例如:
&self vs &'a self
fn method(&self):这是最常见的方法签名,表示对结构体的借用是临时的,只在方法调用期间有效。它不需要显式的生命周期标注,Rust 编译器会根据结构体的生命周期推导出它的有效期。fn method(&'a self):这个签名意味着对结构体的借用必须持续到结构体的生命周期 ’a 结束。这种做法是非常危险的,因为它可能会锁定结构体的借用,直到结构体被销毁为止,导致其他代码无法使用这个结构体。
struct Inspector<'a> {
context: &'a str,
}
impl<'a> Inspector<'a> {
// 正常的方法:借用 &self,用完就还
fn read(&self) {
println!("读取内容: {}", self.context);
}
// 危险的方法:强制借用 self 持续时间为 'a
// 这里的 'a 是 context 的寿命,也是这个结构体能活的最长寿命
fn lock_forever(&'a mut self) {
println!("!!! 锁定整个结构体 !!!");
}
}
fn main() {
let data = String::from("重要卷宗");
let mut detective = Inspector { context: &data };
detective.read(); // 第一次读取:成功
detective.read(); // 第二次读取:成功,说明前两次借用都“还”了
// 关键点:调用这个“终身锁定”的方法
detective.lock_forever();
// --- 观察点 ---
// 按理说,detective 这个变量现在还活着(还没到 main 结尾)
// 但是,如果你尝试再次调用 read():
// detective.read();
// 报错:cannot borrow `detective` as immutable because it is also borrowed as mutable
// 编译器的逻辑:
// 1. lock_forever 要求可变借用 detective 持续 'a 那么久。
// 2. 'a 是 data 的寿命。
// 3. 在 main 结束前,data 一直活着,所以那个可变借用一直没还。
// 4. 一个对象被可变借用期间,不能进行任何其他借用(哪怕是只读)。
}如果我们将 &’a mut self 改回正常的 &mut self(编译器会自动推导一个临时的生命周期 ’b),你会发现一切都恢复了正常。
struct Inspector<'a> {
context: &'a str,
}
impl<'a> Inspector<'a> {
// 正常的方法:借用 &self,用完就还
fn read(&self) {
println!("读取内容: {}", self.context);
}
// 正常的方法:不标注 'a,使用匿名的临时生命周期
fn quick_work(&mut self) {
println!("快速处理,完事还回权力。");
}
}
fn main() {
let data = String::from("重要卷宗");
let mut detective = Inspector { context: &data };
detective.read();
detective.quick_work(); // 借用开始 -> 方法执行 -> 借用结束(归还权力)
detective.read(); // 成功!因为权限已经还回来了。
detective.quick_work(); // 再次成功。
}深度总结:为什么 &'a self 这么直观地“坏事”?
你可以这样理解:
-
普通
&self:像你去图书馆借书。看完(方法结束)就把书还给图书馆了。其他人(或你后续的代码)还能再借。 -
&'a self:像你跟图书馆签了个霸王条款:“这书我借了,直到图书馆倒闭('a结束)我才还。”
- 结果:虽然你手里拿着书(变量还在作用域内),但因为你一直占着“借阅名额”不放,图书馆(编译器)认为这本书一直处于“被借出且不可用”状态,导致后续任何尝试访问该书的操作都会报错。
为什么会出现这种代码?
通常是因为开发者想在结构体里存储一个指向自己的引用(自引用),或者在复杂的 trait 嵌套中写错了标注。在 99% 的情况下,你都不应该在方法的 self 前加上结构体的生命周期参数。
4. 结构体字段间的生命周期约束
如果一个结构体有多个引用字段,你可以给它们不同的寿命,或者强制它们同命。
struct Dual<'a, 'b> {
short: &'a str,
long: &'b str, // 独立寿命 'b
}
fn main() {
let s_long: &'static str = "I am static";
let mut res: &str = "";
{
let s_short = String::from("short");
let d = Dual {
short: &s_short,
long: s_long, // 'b 被识别为 'static
};
// 成功!因为 d.long 的寿命 'b 是独立的。
// 编译器知道即使 d 销毁了,d.long 引向的数据依然是 'static 的。
res = d.long;
}
println!("结果: {}", res); // 运行成功:打印 "I am static"
/* {
let s_short = String::from("short");
let d = Dual {
short: &s_short, // 寿命是这个大括号
long: s_long, // 静态寿命被“传染”,降级为大括号寿命
};
// 报错点:虽然 d.long 引用的是静态字符串,
// 但编译器认为 d.long 的寿命受限于 DualSingle<'a> 的 'a。
// 而 'a 已经在刚才被 s_short 锁定为大括号寿命了。
res = d.short;
} // s_short 销毁,'a 结束
println!("{}", res); // 报错:res 借用的数据存活时间不够长
*/
}五、生命周期约束与绑定
核心逻辑:生命周期约束是 Rust 处理“嵌套关系”和“泛型安全性”的铁律。它通过两种符号:'a: 'b(生命周期比拼)和 T: 'a(类型寿命担保),确保在复杂的嵌套结构中,没有任何一个零件会提前损坏。
1. 生命周期子类型化(Subtyping):'a: 'b
生命周期子类型化表示一个生命周期 'a 至少比 'b 长。在编写如缓存、包装器或视图(View)结构时,你经常会遇到“一个引用指向另一个引用”的情况。这时,必须确保内部引用比外部引用更长命。
❌ 错误演示:内部引用比外部引用早死
struct Buffer<'a>(&'a [u8]);
// 需求:Manager 持有一个 Buffer 的引用。
// 逻辑错误:没有指定 'a 和 'b 的关系。
// 如果 'a (数据源) 比 'b (Manager对Buffer的引用) 先死,Manager 就会崩溃。
struct Manager<'a, 'b> {
buf: &'b Buffer<'a>,
}
fn main() {
let mut manager_ptr: Option<Manager> = None;
{
let data = vec![1, 2, 3];
let buffer = Buffer(&data); // 'a 是 data 的寿命
let m = Manager { buf: &buffer }; // 'b 是 buffer 的寿命
manager_ptr = Some(m);
} // data 在这里被销毁,'a 结束。
// 但 'b 可能还没结束(如果 manager_ptr 还在使用),导致悬空指针。
}✅ 正确演示:显式声明 'a: 'b
通过约束,编译器会强制要求:你想给 Manager 用的数据,必须比 Manager 本身活得久。
// 约束:'a 必须覆盖 'b (数据源必须比借用它的 Manager 活得久)
struct Manager<'a, 'b>
where 'a: 'b
{
buf: &'b Buffer<'a>,
}
// 这样编译器就能在 main 函数中发现:你给的 Buffer 活不过大括号,
// 从而阻止你把 Manager 赋值给外部的 manager_ptr。2. 泛型类型生命周期约束:T: 'a
真实含义是:类型 T 中包含的所有引用,都必须活得比 'a 久。 如果 T 是一个不带引用的普通结构体(如 i32),它默认满足任何 'a(因为它永远不会因引用失效而崩溃)。
当你编写一个容器来装载第三方泛型数据时,你必须确保这些数据在容器存在期间是有效的。
✅ 正确演示:RefWrapper 模式
// T: 'a 保证了不管 T 是什么,只要它里面有引用,那些引用就得比 'a 活得久
struct RefWrapper<'a, T: 'a> {
data_ref: &'a T,
}
fn main() {
let val = String::from("hello");
// T 是 String,String 不含引用,天然满足 T: 'static,当然也满足任何 'a
let wrapper = RefWrapper { data_ref: &val };
// 如果 T 是另一个含有引用的结构体,编译器就会检查 T 内部的引用是否覆盖 'a
}3. Trait 对象生命周期约束:dyn Trait + 'a
当你把一个对象转换成 dyn Trait(动态分发)并存储起来时,编译器需要知道这个“背后的具体对象”能活多久。
为动态对象打上“保质期”标签
如果不加 + 'a,编译器默认 dyn Trait 是 + 'static。这会导致你无法将带有局部引用的对象转为 Trait 对象。
trait Message {
fn print(&self);
}
struct SimpleMessage<'a>(&'a str);
impl<'a> Message for SimpleMessage<'a> {
fn print(&self) { println!("{}", self.0); }
}
// 重点:加上 + 'a,允许这个 Trait 对象持有非静态引用
fn box_message<'a>(msg: SimpleMessage<'a>) -> Box<dyn Message + 'a> {
Box::new(msg)
}
fn main() {
let text = String::from("临时消息");
let msg = SimpleMessage(&text);
let boxed = box_message(msg);
boxed.print();
}六、特殊生命周期
在 Rust 中,有两个特殊的生命周期符号,一个是代表“永生”的 'static,另一个是代表“由你推导”的 '_。理解它们对于编写高质量的库代码至关重要。
1. 'static 静态生命周期
'static 生命周期代表程序整个运行期间有效的引用,通常用于程序的常量和静态变量:
static NAME: &str = "Rust";这是 Rust 中最长命的生命周期。但它有两种完全不同的用法,混淆这两者是很多开发者的噩梦。
A. 引用类型:&'static T
这表示引用指向的数据在程序的整个运行期间都存在(通常存储在二进制文件的 .data 或 .rodata 段中)。
// 正确:字符串字面量默认就是 &'static str
let s: &'static str = "我永远存在";
/* 错误演示:试图将局部变量标记为 'static
fn main() {
let local_string = String::from("I am local");
// 报错:local_string 存活时间不够长,无法变为 'static
let s: &'static str = &local_string;
}
*/B. 特征绑定:T: 'static
这是最容易误解的地方。它不代表 T 必须活一辈子,而是代表:T 内部要么不包含任何引用,要么包含的所有引用都是 'static 的
为什么 String 满足 T: 'static?
String 拥有它自己的数据,它内部不持有任何对外界的引用。所以它被认为是“自给自足”的,满足 T: 'static。
fn print_it<T: 'static>(item: T) {
println!("我接受任何 'static 的数据");
}
fn main() {
let s = String::from("我虽然是局部的,但我没有引用别人");
// ✅ 正确:String 满足 T: 'static
print_it(s);
let local_val = 10;
let r = &local_val;
// ❌ 错误:r 是一个包含局部引用的类型,它不满足 T: 'static
// print_it(r);
}2. 匿名生命周期占位符 '_
'_ 并不代表一个新的生命周期,它是一个语法糖。它告诉编译器:“这里确实需要一个生命周期,但我不想手动起名字,请按照省略规则帮我填上。”
简化 impl 块中的冗余
当你在为带有生命周期的结构体编写 impl 时,'_ 能让代码清爽很多。
❌ 繁琐写法:到处都是 'a
#![allow(unused)]
fn main() {
struct StrHolder<'a> {
s: &'a str,
}
// 每次都要声明并写出 <'a>
impl<'a> StrHolder<'a> {
fn get_s(&self) -> &str { self.s }
}
}✅ 优雅写法:使用 '_
// 在 impl 中使用 '_,编译器会自动关联 self 的生命周期
impl StrHolder<'_> {
fn new(s: &str) -> StrHolder<'_> {
StrHolder { s }
}
}匿名生命周期占位符通常用于简化函数签名,它告诉编译器自动推导生命周期
fn first_word(s: &str) -> &str {
s.split_whitespace().next().unwrap()
}| 符号 | 它的“潜台词” | 典型场景 |
|---|---|---|
&'static T | “这个数据永远不会死” | 硬编码的配置、静态常量 |
T: 'static | “这个对象内部没有任何临时工” | 需要把对象发给另一个线程 |
'_ | “这里该有个寿命,但我懒得取名,编译器你看着办” | 结构体实现、复杂的嵌套引用省略 |
七、型变
型变是 Rust 编译器处理“子类型转换”的一套规则。在生命周期中,如果 'a: 'b('a 比 'b 长),我们认为 'a 是 'b 的子类型。型变决定了当你把一个“长命引用”传给需要“短命引用”的地方时,这种转换是否合法。
1. 协变(Covariance):长命变短命(向上转型)
协变是指子类型可以作为父类型的替代品。例如,在 Rust 中,&T 是协变的:
#![allow(unused)]
fn main() {
let x: &str = "hello";
let y: &dyn ToString = &x; // 协变
}这是最自然的逻辑。你有一个活 100 年的引用,传给一个只需要 10 年引用的函数,这显然是安全的。
fn take_short<'b>(input: &'b str) {
println!("我只需要短命引用: {}", input);
}
fn main() {
let s: &'static str = "我是永生的"; // 'static 是所有生命周期的子类型
// ✅ 协变:&'static str 自动转换(降级)为 &'b str
take_short(s);
}结论:&'a T 对 'a 是协变的,对 T 也是协变的。
2. 逆变(Contravariance): 短命变长命(反向转型)
逆变是指父类型可以作为子类型的替代品,通常在函数类型中出现。
如果 $’a : ’b$,则 $F<’b>$ 可以转换为 $F<’a>$。
// 这里的 F 是 fn(&'a str)
// 如果一个函数能处理短命引用,那么它一定也能处理长命引用。
// 所以 fn(&'short str) 实际上比 fn(&'long str) 的兼容性更强(它是父类)。
// 这是一个“要求高”的函数:它要求传入的处理器必须能处理 'static 引用
fn execute_static_handler(handler: fn(&'static str)) {
handler("I am static");
}
// 这是处理器 A:只能处理 'static
fn static_only(s: &'static str) {
println!("Only static: {}", s);
}
// 这是处理器 B:能力极强,能处理任何生命周期的引用(比如 'a)
fn flexible_handler<'a>(s: &'a str) {
println!("I can handle anything, even short: {}", s);
}
fn main() {
// 1. 传入匹配的处理器,毫无疑问可以
execute_static_handler(static_only);
// 2. 传入“能力更强”的处理器(逆变生效!)
// 虽然 execute_static_handler 要求的是 fn(&'static str)
// 但我们可以把 fn(&'a str) 传给它。
// 因为一个能处理短命引用的函数,必然能安全地处理长命引用。
execute_static_handler(flexible_handler);
}3. 不变性(Invariance): 严丝合缝(禁止转换)
不变性意味着类型不能进行替换。在 Rust 中,&mut T 是不变的。想象中的错误(如果 &mut 是协变的):
fn swap_ref<'a>(target: &mut &'a str, new_val: &'a str) {
*target = new_val;
}
fn main() {
let mut long_lived: &'static str = "static";
{
let short_lived = String::from("short");
// 如果 &mut 是协变的,这里就会允许把 &mut &'static 降级为 &mut &'local
// 然后 swap_ref 就会把 short_lived 的地址塞进 long_lived 变量
// swap_ref(&mut long_lived, &short_lived);
}
// 大括号结束,short_lived 销毁。
// 如果上面成功了,这里的 long_lived 就指向了垃圾内存!
// println!("{}", long_lived);
}结论:&mut T 对于 T 是不变的。这种限制强制要求你存入的数据寿命必须与容器定义的寿命绝对相等。
4. 常见容器与智能指针的型变规则
Box<T>、Rc<T>、Cell<T> 等智能指针的型变规则需要特别注意。
在 Rust 的生命周期进阶中,理解常见容器的型变规则(Variance)是避开“生命周期冲突”报错的关键。下表总结了标准库中常用类型的型变特性:
常见类型型变对照表
| 类型 | 对 'a 的型变 | 对 T 的型变 | 备注 |
|---|---|---|---|
&'a T | 协变 | 协变 | 最灵活。长命引用可降级为短命引用。 |
&'a mut T | 协变 | 不变 (Invariant) | 引用本身的寿命可缩短,但指向的内容必须严格匹配。 |
Box<T> | - | 协变 | 拥有所有权,行为类似 T 本身。 |
Vec<T> | - | 协变 | 类似 Box<T>,拥有所有权。 |
**Rc<T> / Arc<T>** | - | 协变 | 虽然共享所有权,但因其不可变性(除非通过内部可变性),保持协变。 |
**Cell<T> / RefCell<T>** | - | 不变 (Invariant) | 内部可变性会导致型变失效,必须严格匹配。 |
fn(T) -> U | - | 逆变 (T), 协变 (U) | 参数是反向的(逆变),返回值是正向的(协变)。 |
A. 为什么 &mut T 对 T 是不变的(Invariant)?
你已经理解了“长命存入短命容器”是危险的。由于 &mut T 允许写入,如果它是协变的,你可能会把一个短命引用塞进一个长命的引用变量里。
fn overwrite<'a>(container: &mut &'a str, new_val: &'a str) {
*container = new_val;
}
fn main() {
let mut static_str: &'static str = "I'm static";
{
let short_string = String::from("short");
// 如果 &mut T 是协变的,这里会把 &mut &'static 降级为 &mut &'a
// 然后 overwrite 会把 short_string 的地址存进 static_str。
// Rust 强制要求 T 必须【完全匹配】,所以这里会报错。
// overwrite(&mut static_str, &short_string);
}
}B. 为什么 Vec<T> 却是协变的?
这看起来很奇怪:Vec<T> 也能写入,为什么它是协变的?
原因在于所有权(Ownership)。
当你拥有一个 Vec<&'static str> 时,你拥有这个向量的所有权。你可以把它“降级”看作一个 Vec<&'a str>。当你往里面 push 短命引用时,编译器会根据你当前的、降级后的 Vec 类型来检查。
fn main() {
let mut my_vec: Vec<&'static str> = vec!["static"];
// 协变:我们可以把 Vec<&'static str> 传递给接受 Vec<&'a str> 的函数
fn consume_vec<'a>(v: Vec<&'a str>) { /* ... */ }
consume_vec(my_vec); // 成功,发生了协变(所有权转移)
}关键区别:&mut T 是借用(你是在改别人的东西),而 Vec<T> 是拥有(你在改自己的东西)。
C. 内部可变性的“不变性”陷阱:Cell<T>
Cell<T> 和 RefCell<T> 与 &mut T 一样,允许在不拥有所有权的情况下修改数据。因此,它们必须是不变的。
use std::cell::Cell;
fn main() {
let static_cell: Cell<&'static str> = Cell::new("static");
// 尝试把 Cell<&'static str> 降级为 Cell<&'a str>
// 这在 Rust 中是不允许的(Invariant)
// let cell_alias: &Cell<&str> = &static_cell;
// 如果允许降级,你可以通过 cell_alias 存入一个短命引用,
// 从而破坏原始 static_cell 的静态担保。
}八、高级特性与复杂模式
1. 高阶特征边界(HRTBs):for<'a>
通常情况下,生命周期参数是由调用者确定的。但有时,我们需要一个函数能够接收一个闭包,而这个闭包处理的引用是在函数内部临时创建的。
无法描述“未来的借用”
如果你使用普通的 <'a>,编译器会认为这个寿命必须在进入函数之前就存在。
// 错误尝试:
/*
fn execute<'a, F>(f: F)
where F: Fn(&'a str)
{
let s = String::from("local");
f(&s); // 报错:s 的寿命不够长。因为 'a 是在调用 execute 前就定死的。
}
*/
// ✅ 正确方案:使用 HRTBs (High-Rank Trait Bounds)
// for<'a> 读作:对于“任何”可能的生命周期 'a
fn execute<F>(f: F)
where F: for<'a> Fn(&'a str)
{
let s = String::from("local");
f(&s); // 成功!f 现在被要求能处理任何寿命的引用,包括函数内部这个临时的
}2. 闭包中的生命周期推导与显式标注
Rust 闭包的生命周期推导有时会很顽固。特别是当你返回一个借用时,编译器可能无法识别出它应该关联哪个输入。
强制闭包生命周期
在复杂的 Trait 实现中,你可能需要手动给闭包的参数加上“暗示”。
fn main() {
let mut data = vec![1, 2, 3];
// 闭包有时需要显式标注来打破推导僵局
// 这里的标注确保闭包内部的借用不会“逃逸”或错误绑定
let closure = |x: &i32| -> &i32 { x };
let res = closure(&data[0]);
println!("{}", res);
}3. 再借用(Reborrowing)机制
这是 Rust 默默为你做的一项优化。当你把一个 &mut T 传给函数时,你并没有“移动”这个可变引用,而是进行了一次透明的再借用。
为什么可变引用可以连续使用?
按理说 &mut T 是不具备 Copy 特性的,传给函数后应该就没了。但得益于再借用,你可以这样做:
fn touch(s: &mut String) {
s.push_str("!");
}
fn main() {
let mut message = String::from("Hello");
let r = &mut message;
touch(r); // 这里发生了 reborrow: touch(&mut *r)
touch(r); // r 依然可用!
// 但是:你不能在持有再借用的同时使用原始引用
// let r2 = &mut *r; // r2 是从 r 再借用的
// touch(r); // 错误:此时 r 被 r2 锁定了
// touch(r2);
}4. 非词法生命周期(NLL, Non-Lexical Lifetimes)
在旧版 Rust 中,生命周期必须持续到大括号结束。NLL 引入后,编译器会分析数据流图,只要一个引用在之后不再被使用,它的寿命就会提前结束。
在同一个块中先借用再修改
这在处理字典(HashMap)的“查询并修改”逻辑时非常有用。
use std::collections::HashMap;
fn main() {
let mut map = HashMap::new();
map.insert("key", "value");
let val = map.get("key"); // 不可变借用开始
if let Some(v) = val {
println!("{}", v);
} // NLL 识别到 val 的使用到此结束
map.insert("key", "new_value"); // ✅ 成功:即使没出大括号,借用也已提前释放
}5. 生命周期收缩(Lifetime Narrowing)
这其实是协变的一种表现。当编译器发现你把一个长命引用赋值给一个短命需求时,它会自动“收缩”引用的法律身份。这通常发生在匹配分支或循环中,确保类型系统能通过。
迭代器
Rust 的迭代器(iterators)是处理序列数据的强大工具,允许你以懒惰(lazy)方式遍历集合,而不立即计算所有元素。这提高了效率,尤其在链式操作中。迭代器实现了 Iterator trait,提供 next() 方法返回 Option<Item>。Rust 标准库中的许多类型如 Vec、HashMap、Range 等都支持迭代器。迭代器是零成本抽象,编译时优化。
一、 核心概念
1. 迭代器的本质:延迟计算(Lazy Evaluation)
在 Rust 中,创建一个迭代器并不会立刻执行任何计算。它更像是一个“处方”或“计划书”。只有当你真正开始向迭代器“要东西”时,它才会开始工作。
为什么我的代码没运行?
很多初学者写了 map 却发现没有任何输出,这就是因为没有触发“消费”。这就是 Lazy:先建管道,后执行。
fn main() {
let v = vec![1, 2, 3];
// 这一行代码几乎不消耗时间,也不会打印任何东西
// 它只是创建了一个“计划”:把每个元素加 1
let v_iter = v.iter().map(|x| {
println!("正在计算: {}", x);
x + 1
});
println!("迭代器已创建,准备开始...");
// 只有到了这一步,或者使用 for 循环,计算才会真正发生
let result: Vec<_> = v_iter.collect();
println!("最终结果: {:?}", result);
}2. 迭代器与 for 循环的关系
核心逻辑:Rust 的 for 循环其实是语法糖。当你写 for x in items 时,编译器在底层会自动将其转换为迭代器调用。
编译器做了什么?
当你写下这段代码:
#![allow(unused)]
fn main() {
for x in vec![1, 2, 3] {
println!("{}", x);
}
}编译器实际上将其“展开”为类似这样的逻辑:
#![allow(unused)]
fn main() {
let mut iter = vec![1, 2, 3].into_iter(); // 转换为迭代器
while let Some(x) = iter.next() { // 不断调用 next()
println!("{}", x);
}
}- 注意:迭代器内部维护了一个状态(通常是一个指针或索引),每次调用
next(),状态就会向后移动。
3. 消费端(Consumers)与适配器(Adapters)
迭代器的操作可以分为两类,理解它们的区别是掌握数据流的关键。
| 类别 | 作用 | 特点 | 例子 |
|---|---|---|---|
| 适配器 (Adapters) | 将一个迭代器转变为另一个迭代器 | 惰性。不触发计算,只定义变换逻辑。 | map, filter, zip, take |
| 消费端 (Consumers) | 启动迭代过程,产生最终结果 | 主动。会调用 next(),触发整个链条的运行。 | collect, sum, fold, count |
组合的威力
你可以通过适配器构建一条复杂的“流水线”,最后用一个消费端收尾。
fn main() {
let numbers = vec![1, 2, 3, 4, 5, 6];
// 流水线设计:
let sum: i32 = numbers.iter()
.filter(|&&x| x % 2 == 0) // 适配器:只要偶数
.map(|&x| x * x) // 适配器:平方
.take(2) // 适配器:只要前两个
.sum(); // 消费端:触发所有计算并求和
println!("前两个偶数的平方和: {}", sum); // (2*2) + (4*4) = 20
}二、三大核心 Trait
Iterator Trait:核心接口,理解next()方法与Item关联类型IntoIterator Trait:如何将集合(如Vec, HashMap)转换为迭代器FromIterator Trait:collect()方法背后的原理(如何将迭代器转回集合)
在 Rust 中,迭代器不是某种特殊的语言构造,而是通过三个核心 Trait 构建的体系。理解了这三个 Trait,你就理解了数据如何在“集合”与“流水线”之间流转。 这一部分你只要抓住一条主线就够了:
for 负责把东西变成迭代器(IntoIterator) → 迭代器用 next() 吐元素(Iterator) → collect() 把元素“装回去”(FromIterator)
可以把它想成一条流水线:
集合/自定义类型 ──(IntoIterator)──> 迭代器 ──(Iterator::next)──> 元素序列 ──(FromIterator/collect)──> 新集合
1. Iterator Trait:迭代器的基石
这是最核心的 Trait。只要一个类型实现了它,它就是一个迭代器。
最核心的两个东西:Item + next()
Iterator 的本质就是一个状态机:每次调用 next(),迭代器推进内部状态并尝试产出一个元素。
next() 的签名必须是
&mut self:因为每次迭代都会改变“我迭到哪了”的内部状态。
典型形态(要记住结构):
trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}type Item:关联类型,定义了迭代器每次产出什么。fn next(&mut self) -> Option<Self::Item>:这是唯一需要手动实现的方法。
手动实现一个“步进器”
通过手动实现,你会发现迭代器只是一个记录了当前状态的结构体。
struct Counter {
count: u32,
max: u32,
}
impl Counter {
fn new(max: u32) -> Counter {
Counter { count: 0, max }
}
}
// 手动实现 Iterator
impl Iterator for Counter {
type Item = u32; // 告诉编译器,我们产出的是 u32
fn next(&mut self) -> Option<Self::Item> {
if self.count < self.max {
self.count += 1;
Some(self.count)
} else {
None // 返回 None 代表迭代结束
}
}
}
fn main() {
let mut counter = Counter::new(3);
// 我们可以手动调用 next
assert_eq!(counter.next(), Some(1));
assert_eq!(counter.next(), Some(2));
assert_eq!(counter.next(), Some(3));
assert_eq!(counter.next(), None);
}手动调用 next():最直观理解迭代器
fn main() {
let v = vec![10, 20, 30];
// Vec<T> 的 into_iter() 生成一个“拿走所有权”的迭代器
let mut it = v.into_iter();
println!("{:?}", it.next()); // Some(10)
println!("{:?}", it.next()); // Some(20)
println!("{:?}", it.next()); // Some(30)
println!("{:?}", it.next()); // None
println!("{:?}", it.next()); // 依然 None(很多迭代器是 fused 的,但不是 trait 强制)
}你看到的就是:迭代器每次吐一个元素,吐完就 None。
Iterator 的“很多方法”从哪来的?
map/filter/take/fold/sum/… 这些几乎都是 Iterator trait 上的默认方法,基于 next() 组合出来的。你只要实现 next(),Rust 标准库就送你一整套“函数式管道工具”。
fn main() {
let sum: i32 = (1..=10)
.map(|x| x * 2) // 适配器:生成新迭代器
.filter(|x| x % 3 == 0)
.sum(); // 消耗器:触发执行
println!("{sum}");
}2. IntoIterator Trait:集合如何变成迭代器(for 循环背后)
核心逻辑:这个 Trait 定义了如何将一个非迭代器类型(如 Vec)转换为迭代器。这也是 for 循环能够工作的根本原因。
for 循环到底做了什么?
for x in something 做的第一件事是:
调用
something.into_iter()(准确地说是IntoIterator::into_iter(something))
然后不断 next()。
等价理解(伪展开):
let mut iter = something.into_iter();
while let Some(x) = iter.next() {
// ...
}
## `IntoIterator`的定义
```rust,ignore
trait IntoIterator {
type Item;
type IntoIter: Iterator<Item = Self::Item>;
fn into_iter(self) -> Self::IntoIter;
}这里的关键是:
IntoIterator负责“怎么生成迭代器”- 生成的迭代器必须实现
Iterator Item决定了你在for x in ...里拿到的x是什么类型
同一个容器有 3 种常见 IntoIterator 实现
以 Vec<T> 为例:
Vec<T>(按值)→into_iter()产出T(消耗原集合)&Vec<T>(共享借用)→into_iter()产出&T&mut Vec<T>(可变借用)→into_iter()产出&mut T
fn main() {
let v = vec![String::from("a"), String::from("b")];
// 1) 借用遍历:拿到 &String
for s in &v {
println!("borrowed: {s}");
}
println!("still have v: {:?}", v);
// 2) 所有权遍历:拿到 String(v 被 move 走)
for s in v {
println!("owned: {s}");
}
// println!("{:?}", v); // ❌ v 已经被消耗
}自定义类型实现 IntoIterator:让它能直接 for .. in ..
比如自定义一个范围类型:
struct MyRange {
start: i32,
end: i32,
}
struct MyRangeIter {
cur: i32,
end: i32,
}
impl Iterator for MyRangeIter {
type Item = i32;
fn next(&mut self) -> Option<i32> {
if self.cur >= self.end {
None
} else {
let v = self.cur;
self.cur += 1;
Some(v)
}
}
}
impl IntoIterator for MyRange {
type Item = i32;
type IntoIter = MyRangeIter;
fn into_iter(self) -> MyRangeIter {
MyRangeIter { cur: self.start, end: self.end }
}
}
fn main() {
for x in MyRange { start: 0, end: 3 } {
println!("{x}");
}
}3. FromIterator Trait:流水线的终点 (collect)
核心逻辑:这是 collect() 方法背后的英雄。它定义了如何将迭代器中的元素“收集”回一个新的集合。
collect() 不是魔法,它靠 FromIterator
你可以把 collect() 理解成:
“请把这个迭代器的元素,按目标类型的规则装起来”
装的规则来自:
trait FromIterator<A> {
fn from_iter<T: IntoIterator<Item = A>>(iter: T) -> Self;
}能 collect 成什么类型,取决于那个类型实现没实现 FromIterator。
collect() 为什么经常需要你标注类型?
因为光看迭代器元素,编译器不知道你要装进 Vec 还是 HashSet 还是别的。
两种常见写法:
fn main() {
let v = vec![1, 2, 3];
// 写法 1:变量类型标注
let a: Vec<i32> = v.iter().map(|x| x * 10).collect();
println!("{a:?}");
// 写法 2:turbofish
// let a = v.iter().map(|x| x * 10).collect::<Vec<i32>>();
// println!("{a:?}");
}常见 collect 目标:Vec / HashMap / String
collect 到 Vec:
fn main() {
let out: Vec<i32> = (0..5).map(|x| x * 2).collect();
println!("{out:?}");
}collect 到 HashMap:
use std::collections::HashMap;
fn main() {
let pairs = vec![("a", 1), ("b", 2)];
let map: HashMap<&str, i32> = pairs.into_iter().collect();
println!("{map:?}");
}collect 到 String(从 char 序列):
fn main() {
let s: String = ['R', 'u', 's', 't'].into_iter().collect();
println!("{s}");
}collect::<Result<Vec<_>, _>>():FromIterator 的“高级爽点”
Result(以及 Option)也实现了非常强大的 FromIterator:
- 只要所有元素都是
Ok(x),就collect成Ok(Vec<x>) - 只要遇到一个
Err(e),就立刻返回Err(e)(短路)
fn main() {
let inputs = vec!["10", "20", "nope", "40"];
let parsed: Result<Vec<i32>, _> = inputs
.into_iter()
.map(|s| s.parse::<i32>())
.collect();
println!("{parsed:?}"); // Err(...)
}这在解析、校验、批处理里非常常用:把错误处理“自动织入” collect。
自定义 FromIterator:让别人能 collect::<你的类型>()
我们实现一个 EvenVec:只收集偶数(演示“自定义收集规则”)。
#[derive(Debug)]
struct EvenVec(Vec<i32>);
impl FromIterator<i32> for EvenVec {
fn from_iter<T: IntoIterator<Item = i32>>(iter: T) -> Self {
let mut out = Vec::new();
for x in iter {
if x % 2 == 0 {
out.push(x);
}
}
EvenVec(out)
}
}
fn main() {
let evens: EvenVec = (0..10).collect();
println!("{evens:?}"); // EvenVec([0,2,4,6,8])
}三、迭代器的三种模式
核心逻辑:在 Rust 中,迭代器不仅决定如何处理数据,还决定了你是拥有这些数据,还是仅仅借用这些数据。这直接关系到借用检查器(Borrow Checker)是否会报错。
几乎所有的集合(如 Vec, HashMap, BTreeMap)都提供了这三种方法。
这三者的核心差异只有一件事:**迭代时“元素的所有权/借用”**到底归谁。
iter():共享借用(read-only),产出&Titer_mut():可变借用(read-write),产出&mut Tinto_iter():拿走所有权(move),产出 T(通常会消耗原集合)
iter 借只读,iter_mut 借可写,into_iter 拿走不还。
1. iter():不可变借用模式(&T)
- 产生类型:产生元素的不可变引用
&T。 - 使用场景:你只想读取集合中的数据,而不改变数据,也不想销毁集合。
- 知识点:不移动集合元素,只是“借来看看”。迭代结果类型:&T。原集合仍可继续使用(只要借用期结束)。
代码演示:读取但不修改
fn main() {
let v = vec![1, 2, 3];
// iter() 产生 &i32
let mut v_iter = v.iter();
assert_eq!(v_iter.next(), Some(&1));
assert_eq!(v_iter.next(), Some(&2));
assert_eq!(v_iter.next(), Some(&3));
// 重点:集合 v 在迭代后依然可以继续使用
println!("v 依然存在: {:?}", v);
}代码演示:map 时注意解引用
fn main() {
let v = vec![1, 2, 3];
// iter() 产生 &i32,因此 map 的参数是 &i32
let doubled: Vec<i32> = v.iter().map(|x| x * 2).collect();
// 这里 x 是 &i32,但 * 运算符对 &i32 会自动解引用(Deref coercion / Copy)
println!("{:?}", doubled);
}2. iter_mut():可变借用模式(&mut T)
- 产生类型:产生元素的可变引用
&mut T。 - 使用场景:你需要原地修改集合中的每一个元素。
- 知识点:允许修改元素内容,但仍不拿走所有权。迭代结果类型:
&mut T。迭代期间,集合被“独占可变借用”,不能同时被其他借用使用。
代码演示:原地修改元素
fn main() {
let mut v = vec![1, 2, 3];
// iter_mut() 产生 &mut i32
// 注意:必须要求 v 本身是 mut 的
for x in v.iter_mut() {
*x *= 2; // 通过解引用修改原始值
}
println!("v 已被原地修改: {:?}", v); // [2, 4, 6]
}代码演示:配合 enumerate 做位置相关修改
fn main() {
let mut v = vec![5, 5, 5, 5];
for (i, x) in v.iter_mut().enumerate() {
*x += i as i32;
}
println!("{:?}", v); // [5, 6, 7, 8]
}3. into_iter():所有权模式(T)
- 产生类型:产生元素本身
T。 - 使用场景:你需要获取元素的所有权(例如移动到另一个线程,或者转换类型),并且不再需要原始集合。
- 知识点:
- 消耗原集合(通常 move),把元素一个个“搬走”。
- 迭代结果类型:T
- 原集合之后一般不能再用(已经 moved)。
重要:into_iter() 的具体行为和返回类型,取决于你对谁调用:
- 对
Vec<T>调用:通常产出 T(拿走元素) - 对
&Vec<T>调用:相当于 iter(),产出&T - 对
&mut Vec<T>调用:相当于 iter_mut(),产出&mut T
代码演示:消费集合,拿到元素所有权
fn main() {
let v = vec![String::from("a"), String::from("b")];
// into_iter() 产生 String(所有权)
let upper: Vec<String> = v.into_iter()
.map(|s| s.to_uppercase())
.collect();
println!("{:?}", upper);
// println!("{:?}", v); // ❌ v 已被 move(被 into_iter 消耗)
}代码演示:对引用调用 into_iter(类型不同)
fn main() {
let v = vec![1, 2, 3];
let a: Vec<i32> = (&v).into_iter().copied().collect(); // &Vec -> &i32
let b: Vec<i32> = v.into_iter().collect(); // Vec -> i32 (move)
println!("{:?}", a);
println!("{:?}", b);
}三种模式深度对比表
| 方法 | 产生的 Item | 背后 Trait 实现 | 集合之后是否可用? | 核心性质 |
|---|---|---|---|---|
iter() | &T | impl IntoIterator for &Vec<T> | 是 | 只读观察 |
iter_mut() | &mut T | impl IntoIterator for &mut Vec<T> | 是 | 原地手术 |
into_iter() | T | impl IntoIterator for Vec<T> | 否 | 彻底消耗 |
fn main() {
let mut v = vec![1, 2, 3];
let it1 = v.iter(); // Iterator<Item = &i32>
let it2 = v.iter_mut(); // Iterator<Item = &mut i32>
let it3 = v.into_iter(); // Iterator<Item = i32> (v 被 move)
}for 循环到底用的是谁?
for x in something {} 本质上会调用 IntoIterator
for x in v→v.into_iter()(可能消耗v)for x in &v→(&v).into_iter()(等价iter)for x in &mut v→(&mut v).into_iter()(等价iter_mut)
代码演示:三种 for 写法
fn main() {
let mut v = vec![10, 20, 30];
for x in &v {
// x: &i32
println!("read {x}");
}
for x in &mut v {
// x: &mut i32
*x += 1;
}
for x in v {
// x: i32,v 被消费
println!("owned {x}");
}
// println!("{:?}", v); // ❌ v 已被消费
}选型建议:什么时候用哪个?
- 只读遍历:用
iter()/for x in &v - 原地改元素:用
iter_mut()/for x in &mut v - 需要拿到元素所有权(如 String 拼接/转移/线程传递):用
into_iter()/for x in v - 想保留原集合,但又想得到“拥有的值”:
iter().cloned()(针对Clone)iter().copied()(针对Copy)
fn main() {
let v = vec![1, 2, 3];
let owned1: Vec<i32> = v.iter().copied().collect(); // 不消耗 v
let owned2: Vec<i32> = v.clone().into_iter().collect(); // 通过 clone 再消费
println!("{:?}", owned1);
println!("{:?}", owned2);
println!("{:?}", v);
}四、常用迭代器适配器
核心逻辑:适配器(Adapters)是迭代器的“加工车间”。它们接收一个迭代器,经过某种变换,输出一个新的迭代器。最重要的一点是:它们是惰性的(Lazy),除非最后的“消费端”(如 collect)发出指令,否则这些加工车间根本不会开工。
1. 基础转换:map 与 filter
这是最常用的组合,类似于 SQL 中的 SELECT 和 WHERE。
map:对每个元素执行转换。filter:根据布尔值决定是否保留元素。
map:逐元素变换
- 用途:把 Item 变成另一个东西。
- 签名直觉:
Iterator<Item=A> -> Iterator<Item=B>
示例:&i32 / i32 的差异(最常见坑)
fn main() {
let v = vec![1, 2, 3];
// v.iter() 产出 &i32,所以闭包参数是 &i32
let a: Vec<i32> = v.iter().map(|&x| x * 10).collect();// 写法 A:参数里解构, 把 &i32 解引用一层,绑定到 x: i32
//写法 B:闭包体里解引用:
// let b: Vec<i32> = v.iter().map(|x| *x * 10).collect();
// 或者:map(|x| x * 10) 也能过(很多运算会自动解引用),但建议显式 |&x| 养成习惯
// v.into_iter() 产出 i32,闭包参数是 i32
let b: Vec<i32> = v.into_iter().map(|x| x * 10).collect();
println!("{a:?} {b:?}");
}filter:筛选(0/1 对 1)
- 用途:按条件保留元素。
- 关键点:闭包拿到的是 引用的引用 时要解两次(比如 v.iter())
示例:过滤偶数(注意 |&&x|)
fn main() {
let v = vec![1, 2, 3, 4, 5];
let evens: Vec<i32> = v.iter()
.filter(|&&x| x % 2 == 0) // 这里 x: &&i32
.copied()
.collect();
println!("{evens:?}"); // [2, 4]
}常用替代:filter_map(过滤 + 映射,一步到位)
这在实际项目里非常高频(解析、容错、跳过非法数据)
fn main() {
let v = vec!["1", "oops", "3", "-7"];
let nums: Vec<i32> = v.into_iter()
.filter_map(|s| s.parse::<i32>().ok())
.collect();
println!("{nums:?}"); // [1, 3, -7]
}2. 结构操作:zip 与 chain
zip:将两个迭代器“拉”在一起,像拉链一样产生一对对的元组(a, b)。如果长度不等,以短的为准。chain:将两个迭代器“接”在一起,一个完了接另一个。
zip:并行配对(短的结束就结束)
- 用途:将两个迭代器“拉”在一起,并行产出元组
(a, b)。 - 输出类型:
Iterator<Item=(A, B)>
fn main() {
let names = vec!["alice", "bob", "cindy"];
let ages = vec![20, 30];
// 只会产出 2 组:因为 ages 更短
let out: Vec<_> = names.iter()
.zip(ages.iter())
.map(|(&n, &a)| (n, a))
.collect();
println!("{out:?}"); // [("alice",20), ("bob",30)]
}chain:拼接两个迭代器(类型要一致)
- 用途:将两个迭代器“接”在一起,一个完了接另一个。
- 输出类型:
Iterator<Item=A>(或Iterator<Item=B>,取决于输入)
fn main() {
let a = vec![1, 2];
let b = vec![3, 4];
let out: Vec<i32> = a.into_iter().chain(b.into_iter()).collect();
println!("{out:?}"); // [1,2,3,4]
}3. 处理嵌套:flatten 与 flat_map
实践场景:当你有一个 Vec<Vec<T>> 或者迭代器产生的元素本身又是 Option 或 Result 时。
flatten:把嵌套结构“拍平”一层。flat_map:先map再flatten。
flatten:拍平一层(元素本身是 iterable)
- 用途:把
Vec<Vec<T>>拍平成Vec<T>。 - 输出类型:
Iterator<Item=T>
典型:Vec<Vec<T>>、Vec<Option<T>>、Iterator<Item=Result<T,E>>(配合技巧)
fn main() {
let v = vec![vec![1, 2], vec![3], vec![4, 5]];
let out: Vec<i32> = v.into_iter().flatten().collect();
println!("{out:?}"); // [1,2,3,4,5]
}经典技巧:Option 的 flatten = “把 Some 留下,把 None 丢掉”
fn main() {
let v = vec![Some(1), None, Some(3)];
let out: Vec<i32> = v.into_iter().flatten().collect();
println!("{out:?}"); // [1,3]
}flat_map:map + flatten(常用于拆分/展开)
- 用途:先
map再flatten,常用于拆分/展开。 - 输出类型:
Iterator<Item=T>
示例:拆分字符串(按空格)
fn main() {
let lines = vec!["hello world", "rust iter"];
let words: Vec<&str> = lines.into_iter()
.flat_map(|line| line.split_whitespace())
.collect();
println!("{words:?}"); // ["hello","world","rust","iter"]
}4. 引用处理:cloned 与 copied
当你在使用 iter()(产生 &T)但后续操作需要 T 时,这两个适配器非常有用。
-
cloned():调用clone()产生拥有所有权的值(适用于String等)。 -
copied():调用按位拷贝(适用于i32等实现了Copy的类型)。 -
copied():&T -> T,要求 T: Copy(如 i32、bool、char)
-
cloned():&T -> T,要求 T: Clone(如 String、Vec、Arc 等)
fn main() {
let a = vec![1, 2, 3];
let x: Vec<i32> = a.iter().copied().collect();
let b = vec!["hi".to_string(), "rust".to_string()];
let y: Vec<String> = b.iter().cloned().collect();
println!("{x:?}");
println!("{y:?}");
}5. 截取与跳过:take, skip, take_while, skip_while
take(n):只取前n个元素。skip(n):跳过前n个元素。take_while(pred):取元素直到pred为false。skip_while(pred):跳过元素直到pred为false。
take(n) / skip(n):按数量切
fn main() {
let v = vec![1, 2, 3, 4, 5];
let a: Vec<i32> = v.iter().take(3).copied().collect(); // [1,2,3]
let b: Vec<i32> = v.iter().skip(3).copied().collect(); // [4,5]
println!("{a:?} {b:?}");
}take_while / skip_while:按条件切(遇到不满足就停止/开始)
fn main() {
let v = vec![1, 2, 3, 4, 3, 2];
let a: Vec<i32> = v.iter().take_while(|&&x| x < 4).copied().collect();
let b: Vec<i32> = v.iter().skip_while(|&&x| x < 4).copied().collect();
println!("{a:?}"); // [1,2,3]
println!("{b:?}"); // [4,3,2] 注意:从第一个不满足开始,后面不再检查条件
}skip_while 不是“过滤”,它只在开头连续跳过;一旦开始产出,后续不会再跳。
6. 辅助工具:enumerate 与 inspect
enumerate:在迭代时顺便产出索引(index, value)。inspect:不修改元素,只是查看(常用于调试,看看流水线中间的状态)。
enumerate:给元素附上索引
- 用途:做“位置相关”的逻辑(比如给每个元素编号)。
- 输出类型:
(usize, Item)
fn main() {
let v = vec!["a", "b", "c"];
let pairs: Vec<(usize, &str)> = v.iter()
.enumerate()
.map(|(i, &s)| (i, s))
.collect();
println!("{pairs:?}"); // [(0,"a"), (1,"b"), (2,"c")]
}调试辅助:inspect
- 用途:在链条中间打印/埋点,不改变元素。
- 注意:仍然 lazy,只有终结器触发才会打印。
fn main() {
let out: Vec<i32> = (1..=5)
.inspect(|x| println!("before map: {x}"))
.map(|x| x * 10)
.inspect(|x| println!("after map: {x}"))
.filter(|x| x >= &30)
.collect();
println!("{out:?}");
}适配器选型
下面是提到的这些**迭代器适配器(中间操作)**的汇总表
| 分类 | 适配器 | 作用 |
|---|---|---|
| 基础转换 | map | 对每个元素做映射变换(1→1),生成新迭代器 |
| 基础转换 | filter | 按条件过滤元素(保留满足条件的) |
| 基础转换 | enumerate | 给每个元素附带索引 (usize, item) |
| 结构操作 | zip | 把两个迭代器按位置配对成 (a, b),以较短者结束 |
| 结构操作 | chain | 把两个迭代器首尾拼接成一个连续迭代器 |
| 结构操作 | flatten | 拍平一层:把“元素本身可迭代”的迭代器展开一层 |
| 结构操作 | flat_map | map 后再 flatten:每个元素映射为迭代器并展开 |
| 截取/跳过 | take | 只取前 n 个元素 |
| 截取/跳过 | skip | 跳过前 n 个元素 |
| 截取/跳过 | take_while | 从头开始取,直到条件首次不满足就停止 |
| 截取/跳过 | skip_while | 从头开始跳过,直到条件首次不满足就开始产出(之后不再检查条件) |
| 调试辅助 | inspect | 在迭代链中插入观察/打印,不改变元素(仍是 lazy) |
| 引用处理 | cloned | 把 &T 变成 T(要求 T: Clone) |
| 引用处理 | copied | 把 &T 变成 T(要求 T: Copy) |
五、 常用消耗器(终结操作)
核心逻辑:消耗器(Consumers)是流水线的“出口”。如果没有消耗器,前面的适配器(如 map, filter)永远不会执行。消耗器会通过循环不断调用迭代器的 next() 方法,直到返回 None 为止。一旦调用了消耗器,该迭代器就被消耗掉了,不能再次使用。
终极集合器:collect
这是最常见的消耗器,我们在前几节已经多次用到。它将迭代器中的元素收集到某种集合中(如 Vec, HashMap, String 等)。
- 特点:高度泛型,通常需要类型暗示。
- 技巧:它可以将
Option<T>的迭代器收集成Option<Vec<T>>。
关键点:类型推断
编译器不知道你要收集成什么就会报错,所以常见写法:
fn main() {
let v = vec![1, 2, 3];
let a = v.iter().map(|&x| x * 10).collect::<Vec<i32>>();
let b: Vec<i32> = v.iter().map(|&x| x * 10).collect();
println!("{a:?} {b:?}");
}收集成 HashMap
fn main() {
let v = vec![1, 2, 3];
// collect 触发了迭代
let doubled: Vec<_> = v.iter().map(|x| x * 2).collect();
// 进阶:处理 Option。如果其中有一个 None,最终结果就是 None
let maybe_numbers = vec![Some(1), Some(2), None];
let result: Option<Vec<i32>> = maybe_numbers.into_iter().collect();
println!("{:?}", result); // None
}基础聚合:sum, product, count
这些操作非常直观,用于数值计算或统计数量。
count() 返回元素个数(usize)
fn main() {
let c = (1..=10).filter(|x| x % 2 == 0).count();
println!("{c}"); // 5
}sum() / product() : 返回元素总和 / 乘积
fn main() {
let v = vec![1, 2, 3, 4];
let s: i32 = v.iter().sum();
let p: i32 = v.iter().product();
println!("{s} {p}"); // 10 24
}查找与匹配: find, position, any, all, nth
核心优势:这些方法具有**短路(Short-circuiting)**特性。例如,any 只要找到一个满足条件的元素,就会立即停止迭代,不再处理后续数据。这对于性能优化至关重要。
any:只要有一个符合条件就返回true。all:必须全部符合条件才返回true。find:返回第一个符合条件的元素的引用(包裹在Option中)。position:返回第一个符合条件的元素的索引(Option<usize>)。
find 找到第一个满足条件的元素(返回 Option<Item>)
fn main() {
let v = vec![10, 20, 30, 40];
let f = v.iter().find(|&&x| x >= 25);
println!("{f:?}"); // Some(&30)
}position 找到第一个满足条件的索引(返回 Option<usize>)
fn main() {
let v = vec![10, 20, 30, 40];
let p = v.iter().position(|&x| x == 30);
println!("{p:?}"); // Some(2)
}any / all
any:只要有一个符合条件就返回true。all:必须全部符合条件才返回true。
fn main() {
let v = vec![2, 4, 6, 7];
println!("{}", v.iter().any(|&x| x % 2 == 1)); // true
println!("{}", v.iter().all(|&x| x % 2 == 0)); // false
}nth(k): 取第 k 个元素,但会消耗掉前 k 个(不是随机访问)
fn main() {
let mut it = (10..=20);
println!("{:?}", it.nth(3)); // Some(13) 消耗 10,11,12,13
println!("{:?}", it.next()); // Some(14) 迭代器状态已经推进
}折叠与归约:fold, reduce, scan
这三个是“最像算法”的消耗器/半消耗器。
fold(init, f):你提供初始值
- 总是返回一个值(不会是 Option)
- 适合:累计、构建字符串、构建 map、统计等
fn main() {
let v = vec![1, 2, 3];
let r = v.iter().fold(100, |acc, &x| acc + x);
println!("{r}"); // 106
}典型:fold 拼字符串
fn main() {
let words = vec!["hello", "rust", "iter"];
let s = words.iter().fold(String::new(), |mut acc, &w| {
if !acc.is_empty() { acc.push(' '); }
acc.push_str(w);
acc
});
println!("{s}");
}reduce(f):用第一个元素当初始值(返回 Option)
- 空迭代器会返回 None
- 适合:最大值、求和等“有自然单位元但不想写 init”的场景
fn main() {
let v = vec![1, 2, 3];
let r = v.into_iter().reduce(|acc, x| acc + x);
println!("{r:?}"); // Some(6)
}scan(state, f):它是适配器(但非常像 fold)
- scan 会产生一个新迭代器,把“中间状态”也作为输出
- 适合:前缀和、状态机、解析流
fn main() {
let v = vec![1, 2, 3, 4];
// 前缀和:1,3,6,10
let prefix: Vec<i32> = v.into_iter()
.scan(0, |state, x| {
*state += x;
Some(*state)
})
.collect();
println!("{prefix:?}");
}极值处理:max,min,max_by,min_by
返回迭代器中的最大值或最小值。注意它们返回的是 Option,因为迭代器可能没有元素。
- 对于复杂结构,可以使用
max_by或max_by_key。
max/min
fn main() {
let v = vec![3, 10, 7];
println!("{:?}", v.iter().max()); // Some(&10)
println!("{:?}", v.iter().min()); // Some(&3)
}自定义比较:max_by / min_by
比如按字符串长度找最长:
fn main() {
let v = vec!["aa", "bbbb", "ccc"];
let best = v.iter().max_by(|a, b| a.len().cmp(&b.len()));
println!("{best:?}"); // Some("bbbb")
}本节“选择器”:我到底该用谁?
| 类别 | 名字 | 作用 | 返回/特点 |
|---|---|---|---|
| 集合转换 | collect | 把迭代器收集成集合(Vec/HashMap/HashSet/...) | 返回目标集合类型;常需标注 collect::<Vec<_>>() |
| 基础聚合 | count | 统计元素个数 | usize |
| 基础聚合 | sum | 求和 | 返回数值类型(需要可推断) |
| 基础聚合 | product | 连乘 | 返回数值类型(需要可推断) |
| 折叠/归约 | fold | 自定义累计(你提供初始值) | 返回累计结果(不会是 Option) |
| 折叠/归约 | reduce | 用第一个元素做初始值的归约 | Option<Item>,空迭代器为 None |
| 折叠/归约 | scan | 带状态地产生“中间结果序列”(前缀和/状态机) | 注意:它是适配器,返回新迭代器;通常再 collect() |
| 查找/匹配 | find | 找到第一个满足条件的元素 | Option<Item>(借用迭代器通常是 Option<&T>) |
| 查找/匹配 | position | 找到第一个满足条件的索引 | Option<usize> |
| 查找/匹配 | any | 是否存在任意元素满足条件(短路) | bool |
| 查找/匹配 | all | 是否所有元素都满足条件(短路) | bool |
| 查找/匹配 | nth | 取第 n 个元素(从 0 开始) | Option<Item>;会消耗掉前 n 个 |
| 极值处理 | max | 取最大元素 | Option<Item>(借用迭代器常为 Option<&T>) |
| 极值处理 | min | 取最小元素 | Option<Item> |
| 极值处理 | max_by | 自定义比较规则取最大 | Option<Item>,比较由闭包决定 |
| 极值处理 | min_by | 自定义比较规则取最小 | Option<Item>,比较由闭包决定 |
六、自定义迭代器
核心逻辑:在 Rust 中,要让一个结构体变成迭代器,你不需要继承任何复杂的类,只需要实现 Iterator 这个 Trait。你唯一需要做的,就是告诉编译器如何产出下一个元素(next 方法)以及产出什么(Item 类型)。
1. 实现 Iterator Trait 的两要素
要实现自定义迭代器,你的结构体必须具备两点:
- 状态维护:结构体里需要有字段记录当前迭代到了哪里。
next方法:每次调用时更新状态,并返回Some(value)或None。
斐波那契数列迭代器
斐波那契数列是一个完美的自定义迭代器例子,因为它具有清晰的内部状态转移。
struct Fibonacci {
curr: u32,
next: u32,
}
impl Fibonacci {
fn new() -> Fibonacci {
Fibonacci { curr: 0, next: 1 }
}
}
// 为 Fibonacci 实现 Iterator
impl Iterator for Fibonacci {
type Item = u32; // 产出 u32 类型
fn next(&mut self) -> Option<Self::Item> {
let current = self.curr;
// 计算下一项并更新状态
self.curr = self.next;
self.next = current + self.next;
// 斐波那契数列通常是无限的,但在 Rust 中我们需要设置一个边界
// 这里假设超过 1000 就停止
if current > 1000 {
None
} else {
Some(current)
}
}
}
fn main() {
let fib = Fibonacci::new();
// 一旦实现了 Iterator,你就可以使用 map, filter 等所有适配器!
for num in fib.take(10) {
println!("{}", num);
}
}2. 为集合实现 IntoIterator
如果你创建了一个自定义集合(比如 MyList),你可能希望直接写 for x in my_list。这时你需要实现 IntoIterator。
核心逻辑:IntoIterator 的作用是定义“如何从你的集合产生一个迭代器”。
struct MyCollection {
items: Vec<i32>,
}
impl IntoIterator for MyCollection {
type Item = i32;
type IntoIter = std::vec::IntoIter<i32>; // 直接复用 Vec 的迭代器类型
fn into_iter(self) -> Self::IntoIter {
self.items.into_iter()
}
}
fn main() {
let coll = MyCollection { items: vec![1, 2, 3] };
// 现在可以直接在 for 循环中使用
for x in coll {
println!("{}", x);
}
}3. 自定义迭代器的优势:节省内存
自定义迭代器最大的魅力在于:它是按需生成的。
想象一下你需要处理 100 万个数据,如果你先把它们全部存在 Vec 里,会占用大量内存。但如果你写一个自定义迭代器,它只需要记录“当前在哪”,内存占用几乎为零,无论你要处理多少数据。
🛠️ 进阶:带状态的过滤迭代器
你可以创建一个包装另一个迭代器的自定义迭代器。
#![allow(unused)]
fn main() {
struct SkipNone<I> {
inner: I,
}
impl<I, T> Iterator for SkipNone<I>
where
I: Iterator<Item = Option<T>>, // 要求内部迭代器产出 Option
{
type Item = T;
fn next(&mut self) -> Option<Self::Item> {
// 循环调用内部迭代器,直到找到一个 Some 或者结束
while let Some(opt) = self.inner.next() {
if let Some(val) = opt {
return Some(val);
}
}
None
}
}
}核心总结:自定义三部曲
- 定义结构体:确定你需要哪些字段来记住迭代进度(比如索引、当前数值等)。
- 声明
Item类型:告诉 Rust 迭代器产出什么(引用&T还是值T)。 - 编写
next逻辑
- 如果有数据:更新状态,返回
Some(value)。 - 如果没数据:返回
None。
七、 高级与特殊迭代器
- DoubleEndedIterator:双端迭代器,支持从后往前迭代(rev())
- ExactSizeIterator:已知精确长度的迭代器(len())
- FusedIterator:融合迭代器,保证 None 之后永远返回 None
- Peekable:支持“预览”下一个元素而不消耗它
八、 性能与底层原理
- 迭代器的内部迭代 vs 外部迭代
- 编译器优化:循环展开(Loop Unrolling)与内联
- 迭代器在内存安全上的保障:避免索引越界
- itertools 库:了解社区标准扩展包
九、 迭代器与生命周期的交集
- 迭代器产生的引用寿命约束
- 在结构体中存储迭代器(涉及生命周期参数)
- 闭包捕获环境对迭代器生命周期的影响
宏
UnSafe Code
项目组织及依赖管理
项目结构
Cargo.Toml
文档
Cargo
Cargo 命令
Cargo 常用命令速查表
| 命令 | 目的 | 常用场景 |
|---|---|---|
cargo new | 创建新项目 | 开始一个全新的 Rust 项目 |
cargo build | 编译项目 | 检查代码是否能成功构建 |
cargo run | 编译并运行 | 开发时快速查看程序运行结果 |
cargo check | 快速检查错误 | 只检查语法和类型,不生成可执行文件(最快) |
cargo test | 运行测试 | 执行单元测试和集成测试 |
cargo add | 添加依赖 | 向 Cargo.toml中添加第三方库 |
cargo update | 更新依赖 | 升级依赖包到版本允许的最新的版本 |
cargo doc | 生成文档 | 查看当前项目及其依赖的离线 API 文档 |
cargo fmt | 格式化代码 | 自动统一代码风格 |
cargo clippy | 静态分析 | 查找代码中的潜在问题和不规范写法 |
cargo clean | 清理缓存 | 删除生成的 target目录以释放空间 |
cargo metadata | 显示项目元数据 | 查看项目的依赖信息、目标平台等 |
1. 项目初始化与创建
cargo new <name> : 创建一个名为 <name> 的目录,包含基本的项目结构(如 Cargo.toml 和 src/main.rs)
默认创建二进制项目。若要创建库,使用 --lib 参数
cargo init : 在当前目录下初始化 Rust 项目,而不是创建新文件夹
2. 构建与运行
cargo build : 默认进行 Debug 编译,包含调试信息,但运行速度较慢
cargo build --release : 进行优化编译,去掉调试信息,生成的程序运行速度最快,适合发布
cargo run : 它是 build 和执行的组合。如果你修改了代码,它会自动重新编译再运行
3. 依赖包管理
cargo add <crate> : 现代 Cargo 版本(1.62+)支持。直接从命令行添加库,例如 cargo add serde,会自动修改 Cargo.toml
cargo tree : 打印出当前项目所有依赖的树状结构,帮助排查版本冲突或依赖过多的问题
4. 测试与文档
cargo test : 自动寻找代码中带有 #[test] 标记的函数并运行
Rust 的测试主要分为三大类,以下是它们的对比表及详细拆解:
Rust 测试分类速查表
| 测试类型 | 存放位置 | 编写方式 | 执行命令 (精细化) |
|---|---|---|---|
| 单元测试 (Unit) | 逻辑代码文件内 (src/) | mod tests + #[test] | cargo test <模块名> |
| 集成测试 (Integration) | 项目根目录 tests/ 文件夹 | 独立 .rs 文件 | cargo test --test <文件名> |
| 文档测试 (Doc) | 源代码的文档注释中 | /// ```rust ... ``` | cargo test --doc |
a. 单元测试 (Unit Tests) —— 内部测试
- 位置:直接写在
src/*.rs文件里。通常为了不影响阅读,会放在文件底部的mod tests中。 - 特点:可以测试**私有(private)**函数。
- 命令技巧:
cargo test:运行所有测试。cargo test path::to::module:只运行某个特定模块下的单元测试。cargo test --lib:只运行库中的单元测试,忽略集成测试。
b. 集成测试 (Integration Tests) —— 外部测试
- 位置:项目根目录下创建一个
tests/目录,里面存放.rs文件(例如tests/common_test.rs)。 - 特点:
- Cargo 会将
tests/下的每个文件都编译成一个独立的 Crate(包)。 - 只能像外部用户一样测试**公开(pub)**接口。
- 如果你的项目只有
src/main.rs(二进制项目)而没有src/lib.rs,则无法直接使用tests/目录。
- 命令技巧:
cargo test --test common_test:只执行tests/common_test.rs里的测试。
c. 文档测试 (Doc Tests) —— 示例即测试
- 位置:写在函数上方的
///注释里。 - 特点:确保你给用户看的示例代码永远能跑通,不会因为代码重构而过时。
- 命令技巧:
cargo test --doc:专门只跑文档里的示例代码。
d. 常见的过滤与执行参数
当你觉得全量运行太慢时,这些参数非常有用:
-
按名称过滤:
-
cargo test login:运行所有函数名包含 “login” 的测试。 -
多包/工作区 (Workspaces):
-
cargo test -p package_name:在大型项目中,只运行某个特定子包的测试。 -
忽略某些测试:
-
在代码里标记
#[ignore]。 -
运行:
cargo test -- --ignored(专门跑被忽略的测试)。 -
隐藏输出/实时查看:
-
cargo test -- --nocapture:即便测试通过,也把代码里的println!打印出来。
cargo doc --open : 这是 Rust 最人性化的功能之一。它会提取代码中的文档注释(///)并结合依赖库的文档,生成一个精美的本地 HTML 网页并在浏览器中打开
5. 代码质量与规范
cargo fmt : 强制执行 Rust 官方代码风格。团队协作时,通过这个命令可以避免因代码格式不一导致的 Git 冲突
cargo clippy : 被称为“管家婆”。它不仅检查错误,还会告诉你“这里其实可以用更简洁的写法”,是学习地道 Rust(Idiomatic Rust)的最佳途径
6. 项目结构
| 命令 | 目的 | 常用场景 |
|---|---|---|
cargo metadata | 导出项目元数据 (JSON) | 让 IDE、构建脚本或第三方工具读取项目结构 |
--no-deps | 仅显示当前项目信息 | 排除庞大的第三方依赖树,只看本项目的包信息 |
--format-version 1 | 指定输出格式版本 | 目前仅支持版本 1,确保工具解析的兼容性 |
当你运行 cargo metadata 时,Cargo 会解析你的 Cargo.toml 和 Cargo.lock,然后生成一个包含以下信息的巨大 JSON 对象:
- 工作空间(Workspace)结构:包含哪些成员包(members)。
- 依赖树:每个依赖包的版本、来源、依赖的其他包等。
- 目标(Targets):每个包包含哪些二进制文件(bin)、库(lib)或示例(examples)。
- 编译路径:各种文件的绝对路径,方便工具直接访问源代码。
输出的 JSON 结构通常如下:
{
"packages": [ ... ], // 所有包的详细信息
"workspace_members": [ ... ], // 工作区成员的 ID
"resolve": { // 依赖图(谁依赖了谁)
"nodes": [ ... ]
},
"target_directory": "...", // 编译输出目录的路径
"version": 1 // 元数据格式版本
}
Cargo 工具链
三方库
serde
SeaORM
介绍
了解 SeaORM 的核心工作流
请记住这三个核心角色之间的转换关系
- Entity (实体): 对应数据库里的“表”。它定义了结构、关联关系和主键。
- Model (模型): 这是一个纯粹的 Rust 结构体,代表了数据库中的一行数据。它是只读的,通常用于查询结果。
- ActiveModel (活跃模型): 这是用于修改数据的结构体。当你需要 INSERT 或 UPDATE 时,你会把 Model 转换为ActiveModel,设置好字段后再存入数据库。
SeaORM 的核心逻辑
1. 读写分离(Model vs ActiveModel)
SeaORM 把“数据”分成了两种状态,这是它最特别的地方:
*Model (只读卡片): 你从数据库里查出来的数据。它就像一张 照片 ,你可以看,但不能直接在上面改。
*ActiveModel (可写表单): 当你要新增或改动数据时,必须把照片变成“表单”。它会记录哪个字段改了,哪个没改,最后再保存回数据库。
2. Entity 是“地图”
*Entity 就是数据库表的 定义(Schema) 。
- 它告诉程序:表名是什么、有哪些列、主键是谁、表与表之间怎么关联。
3. 连接要“亲手传递”
- SeaORM 没有全局变量 (不像某些框架可以直接调用
DB::save())。 - 你必须自己拿着“数据库连接对象”(
DatabaseConnection),把它传给需要操作数据库的函数。这样做虽然麻烦一点点,但代码更安全、更易于测试。
总结成一句话:
Entity 定义表,Model 用来读,ActiveModel 用来写,Connection 手动传。
安装与配置
PostgreSQL + SeaORM 的标准化安装与配置流程。按照这个顺序操作,你可以快速搭建起开发环境。
第一步:配置 Cargo.toml (依赖安装)首先,在你的 Rust 项目中引入 SeaORM。既然你使用 PostgreSQL,请务必开启 sqlx-postgres 驱动
[dependencies]
# SeaORM 核心配置
sea-orm = { version = "1.1.0", features = [
"sqlx-postgres", # 必选:PostgreSQL 驱动
"runtime-tokio-rustls", # 必选:异步运行时
"macros", # 必选:用于自动生成代码
"debug-print", # 建议:开发时查看 SQL 日志
"with-chrono", # 建议:处理数据库的时间类型
] }
# 日志捕获(用于配合 debug-print)
tracing = "0.1"
tracing-subscriber = "0.3"
# 异步库
tokio = { version = "1.0", features = ["full"] }
Extra features
-
debug-print - 将每个 SQL 语句打印到记录器
-
mock - 用于单元测试的模拟接口
-
macros - 过程宏,例如 DeriveEntityModel
-
rbac - 基于角色的访问控制
-
seaography - 启用 GraphQL 支持
-
schema-sync - 启用 SchemaBuilder 中的同步功能
-
with-chrono - 支持 chrono 类型
-
with-time - 支持 time 类型
-
with-json - 支持 serde-json 类型
-
with-rust_decimal - 支持 rust_decimal 类型
-
with-bigdecimal - 支持 bigdecimal 类型
-
with-uuid - 支持 uuid 类型
-
with-ipnetwork - 支持 Postgres ipnetwork
-
postgres-vector - 支持 Postgres pgvector
-
postgres-array - 支持 Postgres 数组类型,默认开启
-
sqlite-use-returning-for-3_35 - 为 SQLite 3.35+ 版本使用 RETURNING 语句,默认开启
-
mariadb-use-returning - 为 MariaDB 使用 RETURNING 语句,默认开启
第二步:配置连接选项 (Database Connection)
在代码中通过 ConnectOptions 建立与 PostgreSQL 的连接。你可以设置连接池的大小和超时时间。
用法说明:
usesea_orm::{ConnectOptions, Database, DatabaseConnection};
usestd::time::Duration;
pubasyncfnsetup_db() ->Result<DatabaseConnection, sea_orm::DbErr> {
// PostgreSQL 连接字符串格式
letdb_url="postgres://username:password@localhost:5432/database_name";
letmutopt=ConnectOptions::new(db_url);
opt.max_connections(20) // 最大连接数
.min_connections(5) // 最小连接数
.connect_timeout(Duration::from_secs(8)) // 连接超时
.sqlx_logging(false); // 关闭 SQLx 原生日志,改用 SeaORM 的 debug-print
// 返回连接对象 (DatabaseConnection)
Database::connect(opt).await
}第三步:开启调试日志 (Logging)
为了在控制台看到 SeaORM 生成的 SQL 语句,你需要在 main 函数开头初始化日志订阅者。
用法说明:
#[tokio::main]
async fn main() {
// 初始化日志系统,这样才能看到 debug-print 输出的 SQL
tracing_subscriber::fmt()
.with_max_level(tracing::Level::DEBUG)
.init();
letdb=setup_db().await.expect("数据库连接失败");
// ... 开始你的业务逻辑
}第四步:理解操作逻辑 (CRUD 模式)
配置完成后,你在编写业务逻辑时只需记住这套“三位一体”的操作流:
1.定义阶段 (Entity):写一个结构体代表 PostgreSQL 的表。
2.读取阶段 (Model):使用 Entity::find() 查询,结果存入 Model(只读)。
3.写入阶段 (ActiveModel):
- 要把
Model转成ActiveModel才能修改。 - 直接创建
ActiveModel用于插入新数据。
4.手动传递连接:把第二步生成的 db (DatabaseConnection) 对象传给查询函数。
迁移系统
迁移系统(Migration)简单来说就是数据库的版本控制工具。就像 Git 记录代码改动一样,Migration 记录数据库表结构的改动(新建表、加字段、删索引等)。
1. 完整的工作区 (Workspace) 结构
在 Rust 中,SeaORM 官方强烈建议使用 Workspace 模式。这能让你的“业务代码”和“数据库迁移代码”彻底解耦。
推荐的目录树如下:
my_project/
├── Cargo.toml # 根目录虚拟清单
├── src/ # 你的业务逻辑 (App Crate)
│ └── main.rs
└── migration/ # 迁移逻辑 (Migration Crate)
├── Cargo.toml
└── src/
├── lib.rs # 定义迁移器
├── main.rs # CLI 入口
└── m20240110_000001_create_user_table.rs # 具体的表变动记录
2. 第一步:初始化与配置
首先,安装工具并创建迁移目录。
安装 CLI
cargo install sea-orm-cli
初始化
在你的项目根目录下运行:
sea-orm-cli migrate init
配置 migration/Cargo.toml
这是最容易出错的地方。你需要为迁移脚本开启 PostgreSQL 支持:
[dependencies.sea-orm-migration]
version = "1.1.0"
features = [
"runtime-tokio-rustls", # 异步运行时
"sqlx-postgres", # 明确指定使用 Postgres
]
3. 第二步:编写迁移逻辑 (核心细节)
迁移文件(如 m..._create_table.rs)是纯 Rust 代码。SeaORM 使用 SeaQuery(一种 DSL)来描述 SQL。
up 函数:创建表
假设我们要创建一个用户表:
use sea_orm_migration::prelude::*;
//SeaORM 需要给每个迁移任务起个名字(存到 PostgreSQL 的 seaql_migrations 表里)。这个宏会自动把你的文件名(比如 m20240110_...)提取出来作为名字,省得你手动写。
#[derive(DeriveMigrationName)]
pub struct Migration;
// 实现 MigrationTrait 来定义具体的迁移逻辑
#[async_trait]
impl MigrationTrait for Migration {
async fn up(&self, manager: &SchemaManager) -> Result<(), DbErr> {
// 使用 manager 创建表
manager
.create_table(
Table::create()
.table(User::Table) // 表名
.if_not_exists() // 防御性编程
.col(
ColumnDef::new(User::Id)
.integer()
.not_null()
.auto_increment()
.primary_key(),
)
.col(ColumnDef::new(User::Username).string().not_null().unique_key())
.col(ColumnDef::new(User::CreatedAt).date_time().default(Expr::current_timestamp()))
.to_owned(),
)
.await
}
async fn down(&self, manager: &SchemaManager) -> Result<(), DbErr> {
// 回滚操作:删除表
manager
.drop_table(Table::drop().table(User::Table).to_owned())
.await
}
}
// 定义表和列的枚举,方便在 Rust 里引用. 在 SQL 里我们需要写 user(表名)、id(列名),如果不加这个,你得手写字符串 "user", "id"。加了它,你就可以写 User::Table 或 User::Id。如果有拼写错误,编译器会直接报错,这非常安全。
#[derive(DeriveIden)]
enum User {
Table,
Id,
Username,
CreatedAt,
}在数据库迁移(Migration)中,up 和 down 就像是版本控制里的 “前进” 和 “后退”。你可以把它们想象成一对“反义词”操作:up 负责建立,down 负责拆除。
1. fn up
当你运行 sea-orm-cli migrate up 时,执行的就是这个函数。
- 目的:改变数据库的结构,让它变成你想要的新样子。
- 常见操作:
- 创建新表(
create_table)。 - 给现有的表增加新列(
alter_table)。 - 创建索引或外键。
- 创建新表(
2. fn down
当你发现这次改动有问题,或者想回到上一个数据库版本,运行 sea-orm-cli migrate down,执行的就是这个函数。
- 目的:把
up函数做过的事情原样撤销,让数据库回到没改之前的状态。 - 常见操作:
- 如果
up是创建表,down就是删除表(drop_table)。 - 如果
up是加了一列,down就是删掉那一列。
- 如果
- 重要性:对称性。为了保证数据库的整洁,
down逻辑必须写得准确。如果up建了表但down没写删表,数据库就会留下“垃圾”。
3. 它们是如何工作的?
SeaORM 会在你的 PostgreSQL 数据库里自动维护一张表,叫 seaql_migrations。
| 版本号 (Version) | 应用时间 (Applied At) |
|---|---|
| m20220101_000001 | 2024-05-20 … |
- **当你执行
up**:SeaORM 运行up函数。如果成功,就把这个文件名(版本号)记入这张表。下次再跑up时,发现表里已经有了,它就会跳过,不会重复执行。 - **当你执行
down**:SeaORM 查找表里最后一条记录,找到对应的文件,执行它的down函数。如果成功,就从表里删掉这条记录。
4. 深入代码细节
让我们看看你刚才提供的代码块里,这两个函数具体在干什么:
// --- UP: 增加功能 ---
async fn up(&self, manager: &SchemaManager) -> Result<(), DbErr> {
manager
.create_table( // 动作:创建表
Table::create() // 建造者模式开始
.table(User::Table) // 表名:user
.col(...) // 具体的列定义
.to_owned()
)
.await
}
// --- DOWN: 撤销功能 ---
async fn down(&self, manager: &SchemaManager) -> Result<(), DbErr> {
manager
.drop_table( // 动作:删除表(撤销 up 的创建)
Table::drop()
.table(User::Table) // 指定要删哪张表
.to_owned()
)
.await
}4. 第三步:如何执行迁移
你有两个选择:命令行或代码内运行。
A. 命令行方式 (手动)
你需要设置环境变量来告诉 CLI 你的 PostgreSQL 连接串:
# 设置环境变量 (Linux/macOS)
export DATABASE_URL="postgres://user:pass@localhost:5432/my_db"
# 查看当前迁移状态
sea-orm-cli migrate status
# 执行所有待处理的迁移
sea-orm-cli migrate up
# 撤销最后一次迁移
sea-orm-cli migrate down
B. 代码方式 (自动化)
在 src/main.rs 中,连接数据库后立即执行迁移。这样每次你部署新代码,数据库都会自动更新。
use migration::{Migrator, MigratorTrait}; // 引入你的 migration crate
#[tokio::main]
async fn main() {
let db = sea_orm::Database::connect("postgres://...").await.unwrap();
// 这一行会自动运行所有未执行的 .rs 迁移文件
Migrator::up(&db, None).await.expect("迁移失败");
println!("数据库已就绪");
}5. 迁移系统的生命周期 (关键点)
为了防止弄乱 PostgreSQL,请务必理解这三个概念:
seaql_migrations表:SeaORM 会自动在你的数据库里建这张表。它记录了哪些.rs文件已经跑过了。不要手动删它。- 不可变性:一旦某个迁移文件已经
up到了生产环境,不要修改它。如果你想加字段,应该建一个新的迁移文件。 - Iden 宏:代码最后的
enum User { Table, Id... }是为了避免在代码里写硬编码字符串(如"username"),增加类型安全性。
编写迁移
1. 迁移系统的核心配置:MigratorTrait
迁移文件写好后,如果不进行 注册 ,系统是找不到它们的。这是通过 migration/src/lib.rs 实现的。
Migrator结构体 :它是整个迁移的控制塔。migrations函数 :- 它返回一个
Vec<Box<dyn MigrationTrait>>。 - 重要细节 :必须手动将每一个迁移文件(如
m20220101_...::Migration)用Box::new()包裹并放入数组。 - 顺序要求 :数组内的顺序必须是 时间顺序 。SeaORM 依赖这个顺序来依次执行。
- 它返回一个
// migration/src/lib.rs 完整还原
pub struct Migrator;
#[async_trait]
impl MigratorTrait for Migrator {
fn migrations() -> Vec<Box<dyn MigrationTrait>> {
vec![
Box::new(m20220101_000001_create_table::Migration),
// 每一个新生成的迁移文件,都要手动在这里“挂号”
]
}
}2. 深入 SchemaManager
你在 up 和 down 函数中使用的 manager 对象提供了极丰富的 API。
A. 结构创建 (Creation)
use sea_orm_migration::{prelude::*, schema::*};
manager
.create_table(
Table::create()
.table("post")
.if_not_exists()
.col(pk_auto("id"))
.col(string("title"))
.col(string("text"))
.col(enumeration_null("category", "category", ["Feed", "Store"]))
)
.await除了 create_table,还有这些你可能忽略的细节:
create_index:创建索引,eg:manager.create_index(sea_query::Index::create()..)。create_foreign_key:创建外键约束, eg:manager.create_foreign_key(sea_query::ForeignKey::create()..)。create_type(PostgreSQL 专有) :
use sea_orm_migration::prelude::extension::postgres::Type;
manager
.create_type(
Type::create()
.as_enum(CategoryEnum)
.values(["feed", "story"])
.to_owned()
)
.await?;B. 结构变更与删除
drop_table:删除表,eg:manager.drop_table(sea_query::Table::drop()..)alter_table:修改表结构(加字段、改类型)eg:manager.alter_table(sea_query::Table::alter()..)rename_table:重命名。eg:manager.rename_table(sea_query::Table::rename()..)truncate_table:清空表数据但保留结构。eg:manager.truncate_table(sea_query::Table::truncate()..)drop_index/drop_foreign_key:删除索引或外键,eg:manager.drop_index(sea_query::Index::drop()..);manager.drop_foreign_key(sea_query::ForeignKey::drop()..)truncate_table:截断表数据,eg:manager.truncate_table(sea_query::Table::truncate()..)alter_type:修改数据类型(仅限 PostgreSQL),eg:manager.alter_type(sea_query::Type::alter()..)drop_type:删除数据类型(仅限 PostgreSQL),eg:manager.drop_type(sea_query::extension::postgres::Type::drop()..)
C. 结构检查
在执行高风险操作前,可以使用检查方法防止报错:
has_table("name"):是否存在某表,eg:manager.has_table("table_name").await?。has_column("table", "col"):是否存在某列,eg:manager.has_column("table_name", "column_name")。has_index("table", "idx"):是否存在某索引,eg:manager.has_index("table_name", "index_name")。
3. 原始 SQL 的两种执行方式
虽然 SeaQuery 很好,但有时候你必须写原始 SQL。文档提到了两种方法,区别非常大:
-
execute_unprepared(sql):- 用于不带参数的纯 SQL(如
CREATE TABLE)。 - 它是最直接的字符串执行。
// Use `execute_unprepared` if the SQL statement doesn't have value bindings db.execute_unprepared( "CREATE TABLE `cake` ( `id` int NOT NULL AUTO_INCREMENT PRIMARY KEY, `name` varchar(255) NOT NULL )" ) .await?; - 用于不带参数的纯 SQL(如
-
execute_raw(Statement):
- 用于带参数绑定的 SQL(如
INSERT INTO table (name) VALUES (?))。 - 原理 :它通过
Statement::from_sql_and_values构建,能有效防御 SQL 注入。
// Construct a `Statement` if the SQL contains value bindings
db.execute_raw(Statement::from_sql_and_values(
manager.get_database_backend(),
r#"INSERT INTO `cake` (`name`) VALUES (?)"#,
["Cheese Cake".into()]
)).await?;4. 高级技巧与最佳实践 (Tips)
Tip 1:多原子操作组合
你可以在一个 up 函数里写多个操作。注意: 因为你用的是 PostgreSQL ,这些操作会自动被包裹在一个 Transaction(事务) 中。如果第 3 个操作失败了,前 2 个会自动回滚。
Tip 2:手动实现 ADD COLUMN IF NOT EXISTS
MySQL 不支持这个 SQL 语法,所以 SeaORM 建议通过代码逻辑实现:
async fn up(&self, manager: &SchemaManager) -> Result<(), DbErr> {
if !manager.has_column("user", "email").await? {
// 只有不存在时才执行 alter_table
}
Ok(())
}初学者暂时可以不考虑,直接写 create_table 和 add_column。等以后遇到报错了,再回来学这个“手动检查”的方法。
Tip 3:数据种子填充
你可以在 up 逻辑里直接使用 ActiveModel 插入初始数据。迁移文件不仅能改表结构,还能利用你已经写好的实体模型来操作数据。 它是将“结构变更”与“数据初始化”合二为一的优雅手段。
- 逻辑 :先
create_table,紧接着insert(db)。
#[async_trait]
impl MigrationTrait for Migration {
async fn up(&self, manager: &SchemaManager) -> Result<(), DbErr> {
// 1. 先用 SeaQuery 建表
manager.create_table(
Table::create().table(cake::Entity).if_not_exists()
.col(ColumnDef::new(cake::Column::Id).integer().not_null().auto_increment().primary_key())
.col(ColumnDef::new(cake::Column::Name).string().not_null())
.to_owned()
).await?;
// 2. 表建好了,立刻塞入一条初始数据
let db = manager.get_connection();
cake::ActiveModel {
name: Set("Cheesecake".to_owned()),
..Default::default() // 其他字段用默认值
}
.insert(db)// 真正的插入动作
.await?;
Ok(())
}
}迁移系统不仅仅是建表。它是通过 MigratorTrait 注册、利用 SchemaManager 丰富的 API 进行结构演进、并利用 PostgreSQL 的 原子性事务 确保数据安全的一整套工程化方案。
运行迁移
1. 命令行操作 (CLI)
在终端里,你可以手动控制数据库的进化。
注意 :运行这些命令前,必须先在终端设置环境变量:
export DATABASE_URL="postgres://user:pass@localhost:5432/db"。
常用命令对比表
| 命令 | 行为 | 危险等级 | 适用场景 |
|---|---|---|---|
up | 运行所有未执行的迁移。 | 🟢 安全 | 日常更新数据库。 |
down | 撤销最后一次迁移。 | 🟡 中等 | 发现刚写的脚本有错,回滚一下。 |
status | 列出哪些已跑,哪些还没跑。 | 🟢 安全 | 检查当前数据库版本。 |
refresh | 先回滚所有迁移,再重新全部跑一遍。 | 🔴 危险 | 相当于重置数据,但保留表结构的变化。 |
fresh | 直接删掉所有表 ,再重新跑一遍。 | 💀 极高 | 数据库搞乱了,想彻底推倒重来。 |
reset | 回滚所有已应用的迁移。 | 🔴 危险 | 清空数据库结构。 |
A. 命令行界面 (CLI) 常用操作
sea-orm-cli migrate init: 初始化迁移目录,生成基础结构, eg:sea-orm-cli migrate init。sea-orm-cli migrate generate [NAME]: 生成带时间戳的新迁移文件, eg:sea-orm-cli migrate generate create_user_table。sea-orm-cli migrate up: 应用所有挂起的(未执行的)迁移任务, eg:sea-orm-cli migrate up。sea-orm-cli migrate up -n [NUM]: 应用指定数量的挂起迁移任务, eg:sea-orm-cli migrate up -n 3。sea-orm-cli migrate down: 撤销最后一次应用的迁移任务, eg:sea-orm-cli migrate down。sea-orm-cli migrate down -n [NUM]: 撤销最近指定数量的迁移任务, eg:sea-orm-cli migrate down -n 2。sea-orm-cli migrate status: 查看所有迁移任务的状态(已应用或挂起), eg:sea-orm-cli migrate status。sea-orm-cli migrate fresh: 删除数据库中的所有表,并重新从头应用所有迁移, eg:sea-orm-cli migrate fresh。sea-orm-cli migrate refresh: 回滚所有已应用的迁移,然后重新应用它们, eg:sea-orm-cli migrate refresh。sea-orm-cli migrate reset: 回滚所有已应用的迁移任务, eg:sea-orm-cli migrate reset。
B. 程序化调用 (在 Rust 代码中运行)
Migrator::up(db, None): 在程序启动时自动应用所有挂起的迁移, eg:Migrator::up(&db, None).await?。Migrator::up(db, Some(n)): 在代码中应用前n个挂起的迁移, eg:Migrator::up(&db, Some(5)).await?。Migrator::down(db, None): 在代码中回滚所有已应用的迁移(等同于 reset), eg:Migrator::down(&db, None).await?。Migrator::down(db, Some(n)): 在代码中回滚最后n个迁移, eg:Migrator::down(&db, Some(1)).await?。Migrator::status(db): 在代码中检查迁移状态, eg:let status = Migrator::status(&db).await?。Migrator::fresh(db): 在代码中执行“删表重练”操作, eg:Migrator::fresh(&db).await?。Migrator::refresh(db): 在代码中执行“重置并重启”迁移, eg:Migrator::refresh(&db).await?。Migrator::reset(db): 在代码中撤销所有迁移, eg:Migrator::reset(&db).await?。Migrator::get_pending_migrations(db): 获取所有尚未应用的迁移列表, eg:let pending = Migrator::get_pending_migrations(&db).await?。Migrator::get_applied_migrations(db): 获取所有已经成功应用的迁移列表, eg:let applied = Migrator::get_applied_migrations(&db).await?。
2. 代码自动执行:生产环境必备
在生产环境,你不可能手动去敲命令行。通常在 main.rs 程序启动时自动检测并升级数据库。
use migration::{Migrator, MigratorTrait};
// 在连接数据库后调用
let db = Database::connect(url).await?;
// 自动把所有没跑的迁移补上
Migrator::up(&db, None).await?; 初始化数据
如何在数据库迁移过程中 初始化数据(Seeding Data) 。当你建好表后,通常需要塞入一些初始数据(如默认管理员、配置项等)。
1. 数据初始化 (Seeding Data) 的三种方式
- 使用 ActiveModel 初始化 : 借用已经定义好的 Rust 实体类来插入数据,具有最强的类型安全性:
let db = manager.get_connection();
cake::ActiveModel {
name: Set(
"Cheesecake".to_owned()),
..Default::default()
}
.insert(db)
.await?;- 使用 SeaQuery 语句初始化 : 不需要依赖具体的实体类,直接通过代码构造插入语句,适合在实体类尚未生成时使用, eg:
let stmt = Query::insert()
.into_table("cake")
.columns(["name"])
.values_panic(["Tiramisu".into()])
.to_owned();
manager.execute(&stmt).await?;- 事务式初始化 (Transactional) : 手动开启一个事务,确保数据插入要么全部成功,要么全部回滚,保证数据的一致性, eg:
let db = manager.get_connection();
let txn = db.begin().await?; // 开启事务
cake::ActiveModel {
name: Set("Cheesecake".to_owned()),
..Default::default()
}
.insert(&txn)
.await?;
txn.commit().await?; // 提交事务2. 深度细节解析
① 为什么使用 ActiveModel?
这是最推荐的方式。因为它是强类型的,如果你的数据库字段改了,这段代码在编译阶段就会报错,而不是等到运行时才崩溃。
注意 :这要求你的
migrationcrate 能够引用到entitycrate。
② 为什么使用 SeaQuery?
如果你在写迁移脚本时,还没生成对应的 entity 代码,或者不想让迁移脚本和业务代码耦合得太深,就可以用 Query::insert()。它直接操作字符串表名和列名,灵活性更高。
③ 关于 PostgreSQL 的事务 (Important!)
你使用的是 PostgreSQL ,有一个非常大的优势:
- 自动事务 :SeaORM 在 Postgres 上运行
up函数时,默认会把整个函数包裹在一个事务里。 - 手动事务的作用 :虽然有自动事务,但文档中的
db.begin()允许你在迁移逻辑内部进行更细粒度的控制,或者在复杂的逻辑中明确标注事务边界。
3. 核心 API 说明
manager.get_connection(): 从迁移管理器中获取当前的数据库连接对象 (DbConn)。Query::insert(): SeaQuery 的插入语句构造器。manager.execute(&stmt): 执行构造好的 SeaQuery 语句。db.begin(): 在当前连接上开启一个异步事务。txn.commit(): 提交事务,让所有更改永久生效。
迁移脚本不只是能改“结构(表)”,还能改“内容(数据)”。在 PostgreSQL 中,利用其原子性特点,结合 ActiveModel 的类型安全,你可以非常稳健地完成数据库的初始化。
生成实体
Using sea-orm-cli
sea-orm-cli 的实体生成功能(Generate Entity)可以让你不用手写复杂的 Rust 结构体,直接根据数据库里已经建好的表“一键生成”对应的代码。
1. 基础安装与配置
cargo install sea-orm-cli: 安装 SeaORM 命令行工具, eg:cargo install sea-orm-cli。DATABASE_URL=...: 在.env文件或环境变量中设置 PostgreSQL 连接字符串, eg:DATABASE_URL=postgres://user:pass@localhost/db。sea-orm-cli -h: 查看所有可用的命令列表, eg:sea-orm-cli -h。
2. 实体生成命令
这是最核心的命令,它会扫描数据库并生成 Rust 文件。
sea-orm-cli generate entity: 发现数据库中的所有表并生成对应的实体文件, eg:sea-orm-cli generate entity -o src/entities。-u / --database-url: 手动指定数据库连接地址(覆盖环境变量), eg:sea-orm-cli generate entity -u postgres://root:root@localhost/my_db。-s / --database-schema: (PostgreSQL 特有) 指定要扫描的 Schema(默认是 public), eg:sea-orm-cli generate entity -s my_custom_schema。-o / --output-dir: 指定生成文件的存放目录, eg:sea-orm-cli generate entity -o src/models。--with-serde: 为生成的实体自动添加 Serde 序列化/反序列化宏, eg:sea-orm-cli generate entity --with-serde both。--expanded-format: 使用“展开格式”生成代码(将 Column, Relation 等拆开写,更清晰), eg:sea-orm-cli generate entity --expanded-format。--compact-format: 使用“紧凑格式”生成代码(默认模式), eg:sea-orm-cli generate entity --compact-format。--date-time-crate: 指定时间处理库(chrono 或 time), eg:sea-orm-cli generate entity --date-time-crate time。--ignore-tables: 跳过指定的表不生成实体, eg:sea-orm-cli generate entity --ignore-tables seaql_migrations,secret_table。--model-extra-derives: 为生成的 Model 结构体额外添加指定的 Derive 宏, eg:sea-orm-cli generate entity --model-extra-derives "Default, Clone"。
3. PostgreSQL 用户的实战建议
当你运行生成命令时,建议带上以下参数,这在实际开发中最常用:
sea-orm-cli generate entity \
-u postgres://user:pass@localhost/my_db \
-o src/entities \
--with-serde both \
--expanded-format
参数解释:
-o src/entities: 把代码放在专门的目录,方便管理。--with-serde both: 几乎所有的 Web 项目都需要把数据库结果转成 JSON 传给前端,开启这个可以省去手动加#[derive(Serialize, Deserialize)]。--expanded-format: 虽然代码量会变多,但当你需要自定义关联关系(Relation)或者给字段加注释时,这种格式比“紧凑格式”更容易修改。
Entity Format
在 SeaORM 中,一个“实体”不仅仅是一个结构体,它是 Rust 对象与数据库表之间的桥梁
use sea_orm::entity::prelude::*;
#[sea_orm::model]
#[derive(Clone, Debug, PartialEq, Eq, DeriveEntityModel)]
#[sea_orm(table_name = "cake")]
pub struct Model {
#[sea_orm(primary_key)]
pub id: i32,
pub name: String,
#[sea_orm(has_one)]
pub fruit: Option<super::fruit::Entity>,
#[sea_orm(has_many, via = "cake_filling")]
pub fillings: Vec<super::filling::Entity>,
}
impl ActiveModelBehavior for ActiveModel {}核心组成部分
- Model (模型结构体):这是你最常打交道的。它定义了表中每一列的名字和数据类型。当你执行
SELECT查询时,结果会被填充进这个结构体。 - DeriveEntityModel 宏:这是 SeaORM 的魔法所在。你只需定义一个
Model结构体并加上这个宏,它会自动在后台帮你生成:
Entity结构体:用于代表整张表,执行find等操作。Column枚举:代表表中的每一列,用于过滤和排序。PrimaryKey枚举:定义谁是主键。
INFO ActiveModelBehavior (行为钩子):它允许你在数据“落库”前或“出库”后做逻辑处理。即使你什么都不写,也必须声明它,因为 SeaORM 需要它来完成
ActiveModel的闭环。
完整代码演示:PostgreSQL 风格的 User 实体
假设我们要为 PostgreSQL 建立一张用户表,包含主键、唯一索引、可选字段以及自动转换逻辑。
use sea_orm::entity::prelude::*;
use serde::{Deserialize, Serialize};
#[derive(Clone, Debug, PartialEq, DeriveEntityModel, Serialize, Deserialize)]
#[sea_orm(table_name = "users", schema_name = "public")] // 指定表名和 PG 的 schema
pub struct Model {
#[sea_orm(primary_key)] // 标记为主键,默认自增
pub id: i32,// Postgres 本身不支持无符号整数类型,不建议使用无符号类型(例如 u64 )
#[sea_orm(unique)] // 唯一约束
pub username: String,
#[sea_orm(column_type = "Text", nullable)] // 指定 PG 类型为 Text,允许为空
pub bio: Option<String>,
// 逻辑转换:数据库里存 citext(大小写不敏感),Rust 里用 String
#[sea_orm(select_as = "text", save_as = "citext")]
pub email: String,
#[sea_orm(ignore)] // 这个字段不会在数据库中创建,仅供 Rust 逻辑内部使用
pub temp_token: String,
}
// 定义关联关系(如果没有关联,写空即可)
#[derive(Copy, Clone, Debug, EnumIter, DeriveRelation)]
pub enum Relation {}
// 即使它是空的,也不要删除 ActiveModelBehavior impl 块。
// 生命周期钩子
#[async_trait::async_trait]
impl ActiveModelBehavior for ActiveModel {
// 每次创建新的 ActiveModel(比如插入前)时触发
fn new() -> Self {
println!("准备创建一个新的用户记录");
Self {
..ActiveModelTrait::default()
}
}
// Will be triggered before insert / update
async fn before_save<C>(self, _db: &C, insert: bool) -> Result<Self, DbErr>
where C: ConnectionTrait,
{
if insert {
println!("正在插入新用户...");
}
Ok(self)
}
/// Will be triggered before insert / update
async fn before_save<C>(self, db: &C, insert: bool) -> Result<Self, DbErr>
where
C: ConnectionTrait,
{
if self.price.as_ref() <= &0.0 {
Err(DbErr::Custom(format!(
"[before_save] Invalid Price, insert: {}",
insert
)))
} else {
Ok(self)
}
}
/// Will be triggered after insert / update
async fn after_save<C>(model: Model, db: &C, insert: bool) -> Result<Model, DbErr>
where
C: ConnectionTrait,
{
Ok(model)
}
/// Will be triggered before delete
async fn before_delete<C>(self, db: &C) -> Result<Self, DbErr>
where
C: ConnectionTrait,
{
Ok(self)
}
/// Will be triggered after delete
async fn after_delete<C>(self, db: &C) -> Result<Self, DbErr>
where
C: ConnectionTrait,
{
Ok(self)
}
}
核心标签(Attributes)深度解析
如果你手动看代码,最困惑的可能是 #[sea_orm(...)] 里的内容。我为你详细解释它们的设计意图:
A. 命名与映射
#[sea_orm(table_name = "user", rename_all = "camelCase")]
table_name: 必须指定。因为 Rust 结构体习惯大驼峰(UserModel),而 SQL 表习惯小写蛇形(users)。rename_all: 如果你的 PostgreSQL 表全是驼峰命名(非常少见),用这个可以一次性转换,不用给每个字段写column_name。
B. 类型微调
column_type: Rust 的String默认映射到Varchar(255)。如果你在 PostgreSQL 中想用更长的TEXT类型,就必须通过这个标签明确指定。Option<T>: 这是处理 Nullable(可为空) 的唯一方式。Rust 的类型安全强制你必须用Option来包裹数据库中可能为NULL的字段。
C. 主键逻辑
primary_key: SeaORM 看到它后,会自动把这个字段放进生成的PrimaryKey枚举里。auto_increment: 对于 PostgreSQL 的SERIAL类型,默认就是true。如果你用 UUID 或者手动指定 ID,记得把它设为false。
为什么会有 ActiveModelBehavior?
可能觉得 impl ActiveModelBehavior for ActiveModel {} 很多余。
文字说明: 它是为了实现 “领域驱动设计” (DDD)。
- 比如:你想在用户每次修改密码时,自动更新
updated_at时间戳。 - 你可以把这个逻辑写在
before_save钩子里。 - 这样无论你在项目的哪个位置执行
user.update(db),更新时间的逻辑都会自动触发,保证了业务逻辑的内聚性,不用到处复制粘贴代码。
这一章节非常关键,它详细定义了 Rust 类型与 PostgreSQL 类型之间的“翻译规则”。作为 PostgreSQL 用户,你需要特别关注那些 PG 特有的功能(如 JSONB、Array 和 Vector)。
以下是内容的详细拆解与文字说明:
列类型
1. 基础类型映射表
在 SeaORM 中,大多数基础类型是自动转换的。但请注意:PostgreSQL 不支持无符号整数(Unsigned)。
| Rust 类型 | PostgreSQL 类型 | 说明 |
|---|---|---|
String | VARCHAR / TEXT | 默认是 varchar,可用 column_type="Text" 改为 text。 |
i32 | INTEGER | 标准 4 字节整数。 |
i64 | BIGINT | 8 字节长整数。 |
**u32 / u64** | 不支持 | 重要: 在 PG 中请统一使用 i32 或 i64。 |
f64 | DOUBLE PRECISION | 高精度浮点数。 |
bool | BOOL | 布尔值。 |
Vec<u8> | BYTEA | 二进制大对象。 |
2. 时间与特殊类型映射
这些类型通常需要你在 Cargo.toml 中开启对应的 feature(如 with-chrono 或 with-uuid)。
-
UUID:
uuid::Uuid直接映射为 PostgreSQL 的uuid类型。 -
Decimal:
rust_decimal::Decimal映射为decimal。在定义时通常需要指定精度: -
#[sea_orm(column_type = "Decimal(Some((16, 4)))")] -
日期时间:
-
chrono::NaiveDateTime->timestamp(不带时区)。 -
chrono::DateTime<FixedOffset>->timestamp with time zone(带时区)。
3. JSON 与自定义结构 (JSONB)
PostgreSQL 的 JSONB 是其最强大的特性之一。SeaORM 提供了非常优雅的处理方式。
文字说明
- 基础 JSON: 使用
serde_json::Value处理动态格式。 - 强类型 JSON: 如果你希望 JSON 字段直接映射到 Rust 的
struct,只需让该结构体派生FromJsonQueryResult。 - JSONB 优化: 使用
#[sea_orm(column_type = "JsonBinary")]强制使用 PG 的二进制 JSON 格式,这样查询性能更高。
代码演示
#[derive(Clone, Debug, PartialEq, Serialize, Deserialize, FromJsonQueryResult)]
pub struct UserMeta {
pub login_count: i32,
pub last_ip: String,
}
#[derive(Clone, Debug, PartialEq, DeriveEntityModel)]
#[sea_orm(table_name = "profiles")]
pub struct Model {
#[sea_orm(primary_key)]
pub id: i32,
// 自动序列化/反序列化为 JSONB
#[sea_orm(column_type = "JsonBinary")]
pub meta: UserMeta,
}
4. PostgreSQL 专有功能 (Array / Vector / IP)
这是你选择 PostgreSQL 的“红利”,SeaORM 提供了原生支持:
- 数组 (Array): 直接使用
Vec<T>。例如Vec<String>会自动映射为 PG 的text[]。 - 向量 (Vector): 需要开启
postgres-vector模式。用于 AI 向量数据库(如 pgvector 扩展),对应PgVector类型。 - IP 地址: 需要开启
with-ipnetwork。IpNetwork类型对应 PG 的inet或cidr。
5. Unix 时间戳包装器 (New in 2.0.0)
有时候我们不希望在数据库存 Timestamp 类型,而是存一个 i64 的数字(秒数)。SeaORM 2.0 引入了包装器:
ChronoUnixTimestamp: 在 Rust 里它是日期时间对象,但存入数据库时会自动转成i64整数。这对于需要高性能时间比对的场景非常有用。
ActiveEnum
ActiveEnum 是一个非常强大的功能。它允许你直接在 Rust 代码中使用枚举类型,并将其安全地映射到数据库的字段中。
简单来说,它解决了“数据库存 0/1 或 'active'/'inactive',而 Rust 代码需要强类型”的需求。
以下是内容的详细拆解:
1. 三种映射策略
根据你希望在 PostgreSQL 里的存储方式,有三种选择:
| 映射方式 | 数据库存储类型 | 特点 |
|---|---|---|
| String (字符串) | VARCHAR 或 TEXT | 最通用,易于阅读,但在数据库层没有硬约束。 |
| Integer (整数) | INTEGER | 存储空间最省,但数据库里的数字(如 0, 1)不直观。 |
| Native Enum (原生) | CREATE TYPE ... AS ENUM | PostgreSQL 推荐。性能好,数据库层面会有严格的类型约束。 |
2. 字符串映射 (String-backed)
如果你想把 Category::BigTask 存成数据库里的 "bigTask":
- 自动化方式:使用
rename_all自动转换大小写(如camelCase)。 - 手动方式:使用
#[sea_orm(string_value = "xxx")]精确指定。
#![allow(unused)]
fn main() {
#[derive(EnumIter, DeriveActiveEnum)]
#[sea_orm(rs_type = "String", db_type = "String(StringLen::None)", rename_all = "camelCase")]
pub enum Category {
BigTask, // 存储为 "bigTask"
SmallWork, // 存储为 "smallWork"
}
}3. PostgreSQL 原生枚举 (Native Enum)
这是 PostgreSQL 的特色功能。你需要先在数据库创建一个 自定义类型。
第一步:在迁移文件 (Migration) 中创建类型
由于 PostgreSQL 要求先有类型再建表,你有两种写法:
- 写法 A (手动): 直接写明类型名和值。
- 写法 B (推荐): 直接从 Rust 的枚举类生成定义。
#![allow(unused)]
fn main() {
// 在 migration 的 up 函数中
let schema = Schema::new(DbBackend::Postgres);
manager.create_type(
schema.create_enum_from_active_enum::<Tea>()
).await?;
}4. 在 Model 中使用
定义好 ActiveEnum 后,你可以像使用普通类型(如 i32)一样在 Model 结构体里使用它。
#![allow(unused)]
fn main() {
#[derive(Clone, Debug, PartialEq, Eq, DeriveEntityModel)]
#[sea_orm(table_name = "tasks")]
pub struct Model {
#[sea_orm(primary_key)]
pub id: i32,
// 直接使用枚举类型
pub category: Category,
// 也可以是可选的
pub category_opt: Option<Category>,
}
}5. 核心 API 与属性总结
rs_type: 指定在 Rust 中对应的基础类型(通常是String或i32)。db_type: 指定在数据库中的存储格式(String,Integer或Enum)。enum_name: 仅用于原生枚举,指定 PostgreSQL 中该类型的名称(如CREATE TYPE "tea")。DeriveValueType: 如果你只需要简单的字符串映射且不想写复杂的宏,可以用这个更轻量级的替代方案(需手动实现to_str)。
Entity First
这是 SeaORM 2.0 引入的重磅功能:Entity First(实体优先) 工作流。
简单来说,以前你需要先写 SQL/Migration 建表,再写 Rust 代码;现在你只需写 Rust 的 Entity 结构体,SeaORM 会自动帮你把 PostgreSQL 里的表结构同步好。这非常适合快速迭代。
1. 基础配置:开启自动同步
要在项目中使用“实体优先”,首先要在 Cargo.toml 中开启功能,并在 main.rs 连接数据库后调用同步指令。
- Cargo.toml 配置:
[dependencies]
sea-orm = { version = "2.0", features = ["schema-sync", "entity-registry", "sqlx-postgres", "runtime-tokio-rustls"] }
- main.rs 启动逻辑:
use sea_orm::{Database, EntityTrait};
#[tokio::main]
async fn main() -> Result<(), sea_orm::DbErr> {
let db = Database::connect("postgres://user:pass@localhost/my_db").await?;
// 核心代码:自动同步。它会扫描当前 crate 的 entity 模块并更新 Postgres
// "my_app" 需要替换为你 Cargo.toml 里的 package name
db.get_schema_registry("my_app::entity::*").sync(&db).await?;
println!("数据库结构同步完成!");
Ok(())
}
2. 场景一:新增一个表(添加 Entity)
你只需要在 entity/ 目录下新建一个 Rust 文件,下次启动程序时,PostgreSQL 就会自动多出一张表。
- 代码示例 (
entity/post.rs):
#![allow(unused)]
fn main() {
use sea_orm::entity::prelude::*;
#[derive(Clone, Debug, PartialEq, Eq, DeriveEntityModel)]
#[sea_orm(table_name = "post")] // 只要写了这个,SeaORM 就会去建表
pub struct Model {
#[sea_orm(primary_key)]
pub id: i32,
pub title: String,
pub content: String,
}
#[derive(Copy, Clone, Debug, EnumIter, DeriveRelation)]
pub enum Relation {}
impl ActiveModelBehavior for ActiveModel {}
}结果:启动后,Postgres 会执行 CREATE TABLE "post" (...)。
3. 场景二:增加新字段(修改 Model)
如果你想给用户表加一个“出生日期”字段,直接改 Rust 代码即可。
- 代码示例:
#![allow(unused)]
fn main() {
pub struct Model {
#[sea_orm(primary_key)]
pub id: i32,
pub name: String,
// 新增字段:设为 Option 则在数据库中允许为 NULL
pub date_of_birth: Option<DateTimeWithTimeZone>,
// 新增字段:设置默认值,防止旧数据报错
#[sea_orm(default_value = 0)]
pub login_count: i32,
}
}结果:启动后,Postgres 会执行 ALTER TABLE "user" ADD COLUMN "date_of_birth" timestamptz;。
4. 场景三:重命名列(关键属性)
注意:如果你直接改代码里的变量名,SeaORM 会认为你“删了一个旧列,加了一个新列”。要实现真正的“改名”,需要使用 renamed_from。
- 代码示例:
#![allow(unused)]
fn main() {
pub struct Model {
#[sea_orm(primary_key)]
pub id: i32,
// 将数据库中的 "user_name" 改名为 "login_name"
#[sea_orm(renamed_from = "user_name")]
pub login_name: String,
}
}结果:启动后,Postgres 会执行 ALTER TABLE "user" RENAME COLUMN "user_name" TO "login_name";。
5. 场景四:添加/删除索引
通过属性标签控制索引的生命周期。
- 代码示例:
#![allow(unused)]
fn main() {
pub struct Model {
#[sea_orm(primary_key)]
pub id: i32,
#[sea_orm(unique)] // 添加这一行
pub email: String,
}
}结果:
- 添加时:执行
CREATE UNIQUE INDEX "idx-user-email" ON "user" ("email");。 - 删除
#[sea_orm(unique)]时:执行DROP INDEX "idx-user-email";。
6. 进阶:在迁移脚本中使用 SchemaBuilder
如果你不想在 main.rs 里全自动同步,而是在特定的 Migration 里使用这个功能,可以这样做:
- 代码示例:
#![allow(unused)]
fn main() {
#[async_trait]
impl MigrationTrait for Migration {
async fn up(&self, manager: &SchemaManager) -> Result<(), DbErr> {
let db = manager.get_connection();
// 注册并直接应用,不需要手动写一长串 ColumnDef
db.get_schema_builder()
.register(entity::user::Entity)
.register(entity::post::Entity)
.apply(db) // apply 是强制执行创建,sync 是智能对比
.await
}
}
}CURD
我们将使用这个基本模式进行演示:
- cake 一对多 fruit
- cake 多对多 filling
- cake_filling 是 cake 和 filling 之间的连接表
数据查询
1. 基础查询:通过主键获取
这是最简单的查询方式。SeaORM 会自动生成 WHERE id = ? 语句。
find_by_id(id): 根据主键查找。如果是复合主键,传入元组, eg:Cake::find_by_id(1).one(db).await?。.one(db): 期待返回 0 或 1 条数据。结果会被包装在Option<Model>中, eg:let model: Option<cake::Model> = ...。
// 查询主键为 1 的蛋糕
let cheese: Option<cake::Model> = Cake::find_by_id(1).one(db).await?;
// 查询复合主键 (6, 8) 的关联记录
let link: Option<cake_filling::Model> = CakeFilling::find_by_id((6, 8)).one(db).await?;2. 条件查询与排序
当需要更复杂的过滤逻辑时,使用 filter 和 order_by。
find(): 开启查询构造器,默认查询所有列, eg:Cake::find()。.filter(condition): 添加过滤条件(如包含、等于、大于等), eg:.filter(cake::Column::Name.contains("chocolate"))。.order_by_asc / .order_by_desc: 设置排序规则, eg:.order_by_asc(cake::Column::Name)。.all(db): 获取所有匹配的结果,返回Vec<Model>, eg:let cakes: Vec<cake::Model> = ...。
let chocolate_cakes: Vec<cake::Model> = Cake::find()
.filter(cake::Column::Name.contains("chocolate")) // 名字包含 chocolate
.order_by_asc(cake::Column::Name) // 按名字升序
.all(db)
.await?;3. 关联查询(Loading Related Models)
SeaORM 提供了三种方式处理表与表之间的关联查询:
A. 延迟加载 (Lazy Loading)
先查主表,需要时再查关联表。优点:逻辑清晰;缺点:会有多次数据库往返(N+1 问题)。
let cake = Cake::find_by_id(1).one(db).await?.unwrap();
// 仅在需要时去查关联的 fruit
let fruits: Vec<fruit::Model> = cake.find_related(Fruit).all(db).await?;B. 预加载 (Eager Loading - Join)
使用 SQL 的 JOIN 一次性查出所有数据。
find_also_related: 用于 1-1 关系,返回元组(Model, Option<RelatedModel>)。find_with_related: 用于 1-N 或 M-N 关系,返回Vec<(Model, Vec<RelatedModel>)>。
// 一次性查出蛋糕及其对应的水果(1-N)
let cake_with_fruits: Vec<(cake::Model, Vec<fruit::Model>)> = Cake::find()
.find_with_related(Fruit)
.all(db)
.await?;C. 模型加载器 (Model Loader)
如果你已经有一堆主表数据,想批量补全它们的关联项,Loader 比 JOIN 更节省带宽。
let cakes: Vec<cake::Model> = Cake::find().all(db).await?;
// 批量加载所有蛋糕的配料 (M-N),SeaORM 会自动处理中间表
let fillings: Vec<Vec<filling::Model>> = cakes.load_many(Filling, db).await?;4. 分页查询 (Pagination)
处理大量数据时,必须分页。
.paginate(db, page_size): 将查询转为分页器, eg:.paginate(db, 50)。.fetch_and_next(): 获取当前页数据并指向下一页。- 游标分页 (Cursor Pagination): 基于列值(如 ID)的翻页,性能远高于传统的
OFFSET分页,适合大数据量或无限滚动界面。
// 游标分页:获取 ID > 1 的前 10 条数据
let mut cursor = Cake::find().cursor_by(cake::Column::Id);
cursor.after(1);
let first_pages = cursor.first(10).all(db).await?;5. 部分模型查询 (Partial Model)
如果你只需要表中的几个字段(例如用户列表只需姓名,不需要加密密码),使用 PartialModel。
#[derive(DerivePartialModel)]: 定义一个只包含部分字段的结构体。.into_partial_model(): 告诉 SeaORM 只生成查询这些字段的 SQL,减少网络传输。
#[derive(DerivePartialModel)]
#[sea_orm(entity = "cake::Entity")]
struct CakeName {
name: String,
}
let names: Vec<CakeName> = Cake::find()
.into_partial_model()
.all(db)
.await?;
// 生成的 SQL: SELECT "cake"."name" FROM "cake"在 SeaORM 中,如果你想对数据库进行“写”操作(插入、更新、删除),你必须理解 ActiveModel 和它的核心组件 ActiveValue。
这是 SeaORM 最精妙的设计:它不只是存储数据,还存储了数据的状态(这个字段改没改?要不要存入数据库?)。
ActiveModel
1. ActiveValue:字段的三种状态
每个字段在 ActiveModel 中都被包装成一个 ActiveValue 枚举。它决定了生成 SQL 时如何处理该字段。
-
ActiveValue::Set(V):手动设置。该字段会被包含在INSERT或UPDATE语句中。- eg:
name: Set("Apple".to_owned())SQL 中会出现"name" = 'Apple'。
- eg:
-
ActiveValue::Unchanged(V):未改变。通常是刚从数据库查出来的原始值。它不会出现在UPDATE的SET子句中,但会作为主键用于WHERE条件。- eg: 从数据库查出 ID 为 1 的数据,
id状态就是Unchanged(1)。
- eg: 从数据库查出 ID 为 1 的数据,
-
ActiveValue::NotSet:未定义/忽略。该字段完全不参与 SQL 语句。- eg: 插入时
id: NotSet让 PostgreSQL 的SERIAL自动生成 ID。 - eg: 更新时
name: NotSet数据库里的原名字保持不变。
- eg: 插入时
2. ActiveModel:可操作的“表单”
Model 是只读的快照,而 ActiveModel 是一个可以修改的“表单”。
model.into(): 将查询到的 Model 转换为 ActiveModel,此时所有字段状态默认为Unchanged, eg:let active_model: cake::ActiveModel = model.into();。is_changed(): 检查ActiveModel中是否有任何字段被Set过, eg:if fruit.is_changed() { ... }。set_if_not_equal(): 仅当新值与旧值不同时才执行Set,否则保持Unchanged。这能极大减少不必要的数据库更新操作。
3. 代码演示与用法说明
场景 A:插入数据(利用 NotSet)
在 PostgreSQL 中,我们通常希望 ID 由数据库自增生成。
let orange = fruit::ActiveModel {
id: ActiveValue::NotSet, // 不设 ID,让 Postgres 自动生成
name: ActiveValue::Set("Orange".to_owned()),
cake_id: ActiveValue::Set(None), // 显式设置为 NULL
};
// 生成 SQL: INSERT INTO "fruit" ("name", "cake_id") VALUES ('Orange', NULL)
场景 B:部分更新(更新某几个字段)
假设你只想改名字,不想动其他 20 个字段。
let update_fruit = fruit::ActiveModel {
id: ActiveValue::Unchanged(1), // WHERE 条件
name: ActiveValue::Set("New Apple".to_owned()), // SET 字段
cake_id: ActiveValue::NotSet, // 忽略此字段,SQL 里不会出现
};
// 生成 SQL: UPDATE "fruit" SET "name" = 'New Apple' WHERE "id" = 1
4. 转换回 Model (try_into_model)
当你完成修改并想拿到最终的实体数据时,可以将 ActiveModel 转回 Model。
active_model.try_into_model(): 尝试转换。如果字段中有NotSet,转换会失败(报错AttrNotSet), eg:let model = active_model.try_into_model()?;。ActiveModel::default_values(): 如果你想快速生成一个用于测试的模型,可以使用此方法给所有NotSet字段填充默认值(如空字符串或 0)。
Insert
在掌握了 ActiveModel 的状态(Set, Unchanged, NotSet)之后,来到了**“写入数据”**的实战阶段。在 PostgreSQL 中,SeaORM 的插入操作非常高效,特别是它对 RETURNING 语句的原生支持。
以下是关于 Insert(插入) 操作的详细说明与代码演示:
1. 插入单条数据 (Insert One)
有两种方式处理单条插入,区别在于你想要获取什么结果:
| 方法 | 返回值 | 场景说明 |
|---|---|---|
active_model.insert(db) | Model | 最常用。返回一个完整的、带有数据库生成的 ID 和默认值的模型。 |
Entity::insert(am).exec(db) | InsertResult | 仅返回最后插入的 ID(last_insert_id),性能稍高但数据不完整。 |
代码演示:
// 方式 A:拿到完整的 Model(Postgres 内部会自动使用 RETURNING)
let pear = fruit::ActiveModel {
name: Set("Pear".to_owned()),
..Default::default()
};
let model: fruit::Model = pear.insert(db).await?;
println!("新水果的 ID 是: {}", model.id);
// 方式 B:只拿 ID
let res = Fruit::insert(pear).exec(db).await?;
println!("最后插入的 ID 是: {}", res.last_insert_id);2. 批量插入 (Insert Many)
- 用法: 传入一个迭代器(如
Vec或数组)。 - 安全提示: 如果传入空列表,默认会报错。你可以使用
.on_empty_do_nothing()来优雅地处理空数据。
代码演示:
let fruits = vec![
fruit::ActiveModel { name: Set("Apple".into()), ..Default::default() },
fruit::ActiveModel { name: Set("Orange".into()), ..Default::default() },
];
// 执行批量插入
let res = Fruit::insert_many(fruits).exec(db).await?;3. 冲突处理 (On Conflict / Upsert)
这是 PostgreSQL 的强项。当插入的数据违反唯一约束(比如 ID 重复)时,你可以选择“无视”或“更新”。
do_nothing(): 冲突时什么都不做。update_column(): 冲突时更新指定列(即 Upsert 操作)。
代码演示:
let orange = cake::ActiveModel {
id: Set(2),
name: Set("Orange".to_owned()),
};
// 如果名字冲突,就更新名字
cake::Entity::insert(orange)
.on_conflict(
sea_query::OnConflict::column(cake::Column::Name)
.update_column(cake::Column::Name)
.to_owned()
)
.exec(db)
.await?;注意:如果
ON CONFLICT导致没有新行被插入或更新,SeaORM 默认会抛出DbErr::RecordNotInserted错误。如果你希望在这种情况下也返回Ok,记得调用.do_nothing()方法。
4. PostgreSQL 特色:返回插入的模型 (Returning)
在 PostgreSQL 中,你可以在插入的同时要求数据库把所有字段(包括数据库自动生成的字段)直接返回,避免再次查询。
exec_with_returning: 返回插入后的Model(单条)或Vec<Model>(多条)。exec_with_returning_keys: 仅返回所有插入行的主键。
代码演示:
// 批量插入并直接拿到所有生成好的 Model
let inserted_models: Vec<cake::Model> = cake::Entity::insert_many(vec![am1, am2])
.exec_with_returning(db)
.await?;
Save
在掌握了 Insert 和 ActiveValue 的状态后,save 方法是 SeaORM 提供的一个非常实用的**“智能助手”**。它能根据主键的状态,自动帮你判断是该执行 INSERT 还是 UPDATE。
以下是关于 Save 操作的详细说明与代码演示:
1. 核心逻辑:它是如何判断的?
save 方法的逻辑非常直观,它完全依赖于 主键(Primary Key) 的状态:
| 主键状态 (ActiveValue) | 对应操作 | 背后原因 |
|---|---|---|
NotSet | INSERT | 数据库中还没有这个 ID,说明是新数据。 |
Set 或 Unchanged | UPDATE | 已经有了明确的主键值,说明数据已存在,执行更新。 |
2. 代码演示:从“新增”到“修改”
这个方法最强大的地方在于,你可以对同一个 ActiveModel 连续调用 save,它会处理好一切。
use sea_orm::ActiveValue::{NotSet, Set};
// --- 第一阶段:插入 ---
let mut banana = fruit::ActiveModel {
id: NotSet, // 主键是 NotSet,准备插入
name: Set("Banana".to_owned()),
..Default::default()
};
// 执行 save,此时内部运行的是 INSERT
// 注意:PostgreSQL 会利用 RETURNING 自动把生成的 ID 填回 banana 里
let mut banana: fruit::ActiveModel = banana.save(db).await?;
println!("插入成功,生成的 ID 为: {:?}", banana.id);
// --- 第二阶段:更新 ---
// 修改模型中的值
banana.name = Set("Banana Mongo".to_owned());
// 再次执行 save
// 此时主键 id 是从数据库查回来的(状态为 Unchanged),所以内部运行的是 UPDATE
let banana: fruit::ActiveModel = banana.save(db).await?;
println!("更新成功!");3. 深度解析与注意事项
A. 自动刷新数据
当你调用 save 后,它会返回一个新的 ActiveModel。
- 在 PostgreSQL 中,SeaORM 会在 SQL 末尾加上
RETURNING *。 - 这意味着插入/更新后,数据库中任何自动生成的字段(比如
created_at时间戳、自增 ID、触发器修改的值)都会实时同步回你返回的那个ActiveModel中。
B. 与 insert 方法的区别
insert(): 只能执行插入。如果主键已存在,会直接报错。返回的是Model(只读)。save(): 具有判断能力。返回的是ActiveModel(可继续编辑)。
Update
更新操作(Update)在 SeaORM 中非常灵活。它依赖于我们之前提到的 ActiveModel 状态机:只有被标记为 Set(已改变)的字段,才会出现在生成的 UPDATE SQL 语句中。
以下是关于 Update 操作的详细拆解与代码演示:
1. 更新单条记录 (Update One)
通常的流程是:先查询出数据(Model),修改后存回数据库。
model.into(): 将查询到的Model转换为ActiveModel。此时所有字段状态均为Unchanged。.update(db): 仅更新那些状态为Set的字段, eg:active_model.update(db).await?。.reset_all(): 如果你想强制数据库覆盖所有字段(即使值没变),可以使用reset_all将所有字段强制转为Set状态。
// 1. 获取模型
let pear: Option<fruit::Model> = Fruit::find_by_id(28).one(db).await?;
let mut pear: fruit::ActiveModel = pear.unwrap().into();
// 2. 修改属性(状态变为 Set)
pear.name = Set("Sweet pear".to_owned());
// 3. 执行更新
// SQL: UPDATE "fruit" SET "name" = 'Sweet pear' WHERE "id" = 28
let pear: fruit::Model = pear.update(db).await?;2. 批量更新 (Update Many)
当你需要根据特定条件(如“给所有苹果分类”)进行更新时,不需要先查询出每一个对象。
.set(active_model): 使用一个ActiveModel模板来定义要更新的字段和值。.col_expr(col, expr): 使用表达式进行更新,比如将某列设为固定值, eg:.col_expr(Column::Price, Expr::value(10.0))。.filter(): 限制更新的范围,否则会更新全表。
// 将所有名字包含 "Apple" 的水果的 cake_id 改为 1
let update_res: UpdateResult = Fruit::update_many()
.col_expr(fruit::Column::CakeId, Expr::value(1))
.filter(fruit::Column::Name.contains("Apple"))
.exec(db)
.await?;
println!("更新了 {} 行数据", update_res.rows_affected);3. PostgreSQL 专有功能:返回更新后的数据
这是 PostgreSQL 的一大杀器。在执行批量更新的同时,你可以直接拿回受影响行的最新数据。
exec_with_returning: 更新并返回Vec<Model>,让你省去一次额外的查询, eg:Fruit::update_many()...exec_with_returning(db).await?。eq_any(Postgres Only): 2.0 版本新增的快捷操作,对应 SQL 中的= ANY,性能优于多次OR。
// 批量更新并直接获取更新后的完整模型列表
let updated_fruits: Vec<fruit::Model> = Fruit::update_many()
.col_expr(fruit::Column::CakeId, Expr::value(1))
.filter(fruit::Column::Name.contains("Apple"))
.exec_with_returning(db)
.await?;
assert_eq!(updated_fruits[0].cake_id, Some(1));4. 字段状态的强制重置
有时候你可能希望确保某些字段被写入数据库,即便在 Rust 逻辑中它们看起来没变:
pear.reset(fruit::Column::Name): 将name列标记为“脏(dirty)”,强制包含在 UPDATE 语句中。pear.not_set(fruit::Column::Name): 将name列从 UPDATE 语句中彻底剔除,无论它之前是什么状态。
核心总结:
- 单条更新:
model.into() -> set -> update()。 - 条件批量更新:
update_many().set().filter().exec()。 - Postgres 特权:
exec_with_returning()。
恭喜你!到这里,你已经完整学习了 CRUD 的每一个环节(增、删、改、查、同步、JSON、原生 SQL)。你已经准备好构建完整的 Rust 后端了。你想了解如何处理复杂的“关联关系 (Relations)”或者“连接池配置”吗?
Delete
在掌握了“增、改、查”之后,我们最后来看**删除(Delete)**操作。在 SeaORM 中,删除同样可以针对单条记录或多条记录执行,而且针对 PostgreSQL,它还支持极其方便的 RETURNING 功能。
以下是关于 Delete 操作的详细说明与代码演示:
1. 删除单条记录 (Delete One)
删除单条记录有两种主要方式,取决于你是否已经将数据查询到了内存中。
- 通过 Model 实例删除: 如果你已经有一个查询出来的
Model,可以直接调用.delete()。这在需要先检查数据权限、再决定是否删除的业务场景中非常有用, eg:model.delete(db).await?。 - 根据主键直接删除: 无需先查询数据,直接发送
DELETE指令。这是最直接、性能最高的方式, eg:Fruit::delete_by_id(1).exec(db).await?。
use sea_orm::entity::ModelTrait;
// 场景 A:先查后删(适合需要前置逻辑检查的情况)
let orange: Option<fruit::Model> = Fruit::find_by_id(30).one(db).await?;
if let Some(model) = orange {
let res: DeleteResult = model.delete(db).await?;
assert_eq!(res.rows_affected, 1);
}
// 场景 B:直接删(已知 ID,追求效率)
let res: DeleteResult = Fruit::delete_by_id(38).exec(db).await?;2. 批量删除 (Delete Many)
你可以像构建查询一样,通过 filter 来定义要删除的数据范围。
delete_many(): 开启批量删除构造器,配合filter限制范围。如果不加filter,它会尝试删除表中的所有行, eg:fruit::Entity::delete_many().filter(...).exec(db).await?。
// 批量删除名字包含 "Orange" 的水果
let res: DeleteResult = fruit::Entity::delete_many()
.filter(fruit::Column::Name.contains("Orange"))
.exec(db)
.await?;
println!("删除了 {} 行记录", res.rows_affected);3. PostgreSQL 特色:返回被删除的数据 (Returning)
作为 PostgreSQL 用户,这是一个非常强大的功能。在执行删除的同时,数据库可以将被删除的那一行数据完整地返回给 Rust。这在处理“回收站”功能或需要清理关联缓存时非常有用。
exec_with_returning: 删除并返回被删掉的模型(单条或多条), eg:Entity::delete_many().filter(...).exec_with_returning(db).await?。
// 删除 ID 为 3 的记录,并直接拿到被删除的数据内容
let deleted_item: Option<fruit::Model> = fruit::Entity::delete(fruit::ActiveModel {
id: Set(3),
..Default::default()
})
.exec_with_returning(db)
.await?;
// 批量删除并拿到所有被删掉的模型列表
let deleted_list: Vec<order::Model> = order::Entity::delete_many()
.filter(order::Column::CustomerId.eq(22))
.exec_with_returning(db)
.await?;
4. 常用 API 与结果说明
-
DeleteResult: 执行exec()后返回的结果对象。 -
.rows_affected: 告诉你数据库里实际上有多少行被删除了。 -
exec_with_returning(): 针对 Postgres/SQLite 的高级 API,返回Option<Model>或Vec<Model>。
JSON
在现代 Web 开发中,数据库与前端之间的数据传递几乎全是 JSON。SeaORM 提供了非常丝滑的 JSON 支持,让你能够跳过复杂的结构体映射,直接在“数据库”与“JSON”之间快速转换。
这对 PostgreSQL 用户尤其有用,因为 Postgres 对 JSONB 的支持非常强大。
以下是关于 JSON 操作的详细说明与代码演示:
1. 将查询结果直接转为 JSON (Select JSON)
当你只想把数据从数据库查出来直接丢给前端,而不需要在 Rust 里处理业务逻辑时,使用 .into_json() 可以显著简化代码。
.into_json(): 将查询构造器切换到 JSON 模式。返回的结果不再是Model,而是serde_json::Value, eg:Cake::find().into_json().all(db).await?。- 兼容性: 支持
one()、all()以及分页paginate()。
代码演示:
// 查询单个蛋糕并直接以 JSON 格式返回
let cake: Option<serde_json::Value> = Cake::find_by_id(1)
.into_json()
.one(db)
.await?;
// 带有过滤和排序的 JSON 列表查询
let cakes: Vec<serde_json::Value> = Cake::find()
.filter(cake::Column::Name.contains("chocolate"))
.into_json()
.all(db)
.await?;2. 从原生 SQL 获取 JSON
当你编写复杂的聚合 SQL(例如 GROUP BY 或多表联查)时,结果集往往不符合任何现有的 Model。这时可以用 JsonValue 来承接结果。
JsonValue::find_by_statement: 执行原始 SQL 语句并将结果集直接映射为 JSON 数组, eg:JsonValue::find_by_statement(sql).all(db).await?。
let sql = Statement::from_sql_and_values(
DbBackend::Postgres,
r#"SELECT "name", COUNT(*) FROM "cake" GROUP BY "name""#,
[],
);
let result: Vec<serde_json::Value> = JsonValue::find_by_statement(sql)
.all(db)
.await?;3. 将输入 JSON 转换为 ActiveModel
这是处理前端提交表单(POST/PUT 请求)的神器。你可以直接把前端传来的 JSON 映射到数据库模型中执行保存。
A. 从 JSON 创建新模型 (from_json)
如果你要处理一个“新增”请求,可以使用 from_json。
- 逻辑:JSON 中存在的字段会被设为
Set,不存在的字段会被设为NotSet(方便触发数据库默认值), eg:ActiveModel::from_json(json_data)?。
B. 用 JSON 更新现有模型 (set_from_json)
如果你要处理一个“修改”请求,可以使用 set_from_json。
- 安全保护:这个方法会自动忽略 JSON 里的主键 ID,防止前端通过恶意构造 JSON 来修改你的主键, eg:
active_model.set_from_json(json_data)?。
// 场景:处理新增
let new_fruit = fruit::ActiveModel::from_json(json!({
"name": "Apple",
}))?;
// id 此时是 NotSet,Postgres 会自动生成
// 场景:处理部分更新
let mut fruit = fruit::ActiveModel {
id: Set(1), // 锁定要修改的 ID
..Default::default()
};
// 即使 JSON 里写了 "id": 888,set_from_json 也会忽略它,只更新 name
fruit.set_from_json(json!({
"id": 888,
"name": "Super Apple",
"cake_id": 1,
}))?;实战避坑指南
- 字段名映射:SeaORM 在转换 JSON 时遵循你在
Model里定义的rename_all规则。如果你的 Rust 字段是first_name但设置了camelCase映射,那么 JSON 里的 Key 必须是firstName才能匹配成功。 Option<T>与 Null:- JSON 里的
null会映射为ActiveValue::Set(None)。 - JSON 里完全缺失该字段会映射为
ActiveValue::NotSet。
- JSON 里的
- JSONB 性能:对于 PostgreSQL 而言,虽然你可以把整个结果转为 JSON 给前端,但如果你需要对 JSON 内部的某个字段进行过滤,建议在 SQL 层面处理(利用 Postgres 的
->>操作符),而不是把所有数据拉到内存里再处理。
原生 SQL
虽然 SeaORM 推荐使用强类型的查询构造器,但有时你必须编写原生 SQL (Raw SQL) 来处理复杂的查询或利用 PostgreSQL 的特殊功能(如扩展、窗口函数等)。
SeaORM 2.0 引入了极其方便的 raw_sql! 宏,极大地简化了 SQL 字符串的处理。
1. 使用 raw_sql! 宏查询模型 (Find Model)
如果你想写 SQL 但依然希望结果被解析为 Model 结构体,可以使用 from_raw_sql 方法。
raw_sql!: 该宏能自动处理参数绑定。最酷的功能是({..ids}),它能自动把数组展开为(?, ?, ?)。- 参数绑定: 使用
{variable}语法,SeaORM 会安全地将其处理为占位符,防止 SQL 注入。
代码演示:
let id = 1;
let ids = vec![1, 2, 3];
// 查询单条并映射回 Model
let cake: Option<cake::Model> = cake::Entity::find()
.from_raw_sql(raw_sql!(
Postgres,
r#"SELECT "cake"."id", "cake"."name" FROM "cake" WHERE "id" = {id}"#
))
.one(&db)
.await?;
// 使用数组展开功能进行批量查询
let cakes: Vec<cake::Model> = cake::Entity::find()
.from_raw_sql(raw_sql!(
Postgres,
r#"SELECT * FROM "cake" WHERE "id" IN ({..ids})"#
))
.all(&db)
.await?;2. 查询到自定义结构体
当你的 SQL 涉及多表联查或计算列时,可以定义一个 FromQueryResult 的结构体来承接数据。
#[sea_orm(nested)]: 允许你在结构体中嵌套另一个结构体。#[sea_orm(alias = "...")]: 映射 SQL 中的别名到结构体字段。
#[derive(FromQueryResult)]
struct CakeWithBakery {
name: String,
#[sea_orm(nested)]
bakery: Option<BakeryInfo>,
}
#[derive(FromQueryResult)]
struct BakeryInfo {
#[sea_orm(alias = "bakery_name")] // 对应 SQL 里的 AS bakery_name
name: String,
}
let result = CakeWithBakery::find_by_statement(raw_sql!(
Postgres,
r#"SELECT "cake"."name", "bakery"."name" AS "bakery_name"
FROM "cake"
LEFT JOIN "bakery" ON "cake"."bakery_id" = "bakery"."id""#
))
.all(db)
.await?;3. 直接执行接口 (Query & Execute)
如果你不想映射到任何结构体,只想拿到原始结果或者执行一条不返回数据的指令(如 DROP),可以直接操作 db 连接。
- **
query_one_raw/query_all_raw**: 返回QueryResult对象,通过.try_get获取特定列的值。 execute_raw: 用于执行INSERT,UPDATE,DELETE或 DDL,返回影响的行数。execute_unprepared: (PostgreSQL 常用) 执行不需要参数绑定的 SQL,例如创建插件。
// 执行原始 SQL 并手动取值
let res = db.query_one_raw(Statement::from_string(DbBackend::Postgres, "SELECT name FROM cake WHERE id = 1")).await?;
let name: String = res.unwrap().try_get("", "name")?;
// 执行 DDL
db.execute_raw(Statement::from_string(DbBackend::Postgres, "DROP TABLE IF EXISTS old_table")).await?;
// PostgreSQL 开启扩展专用
db.execute_unprepared("CREATE EXTENSION IF NOT EXISTS citext").await?;4. 调试利器:查看 SeaORM 生成的 SQL
当你的 filter 结果不如预期时,可以随时查看 SeaORM 到底给数据库发了什么。
.build(backend).to_string(): 将任何查询转换成对应数据库语法的 SQL 字符串。
use sea_orm::{DbBackend, QueryTrait};
let query_sql = cake::Entity::find()
.filter(cake::Column::Id.eq(1))
.build(DbBackend::Postgres)
.to_string();
println!("生成的 SQL 为: {}", query_sql);
// 输出: SELECT "cake"."id", "cake"."name" FROM "cake" WHERE "cake"."id" = 1PostgreSQL实战避坑指南
- 引号问题: PostgreSQL 对表名和列名是大小写敏感的,建议在原生 SQL 中始终使用双引号
"包裹,例如"user"."id"。 - 占位符一致性: 虽然
raw_sql!宏会自动处理,但如果你手动写Statement,记得 PostgreSQL 的占位符是$1,$2(SeaORM 会自动帮你处理后端差异,但手动写 SQL 时需留意)。 - 数组限制:
({..ids})非常方便,但在 PostgreSQL 中如果数组过大(超过几万个),SQL 语句长度可能会超限,此时建议使用临时表。
核心总结:
- 模型映射:用
find().from_raw_sql()。 - 动态参数:用
raw_sql!(Postgres, "...", {val})。 - 快速执行:用
execute_unprepared()。 - 调试:用
.build(backend).to_string()。
anyhow
介绍
在这一章节中,我们将深入探讨 anyhow 的核心理念:为什么要用它,以及它是如何简化代码的。
核心理念:应用程序的“万能胶水”
在 Rust 中,错误处理通常是“强类型”的。如果你在一个函数中既读文件(io::Error)又解析 JSON(serde_json::Error),标准做法是定义一个庞大的 enum 来包裹它们。
这在开发**库(Library)时是好习惯,但在开发应用程序(Application,如 CLI、后端服务)**时,这种做法会产生大量的模板代码。
anyhow::Error 就像是一个通用的容器。它可以装下任何实现了 std::error::Error trait 的错误类型。
关键特性
- 类型擦除:它把具体的错误类型抹掉,统一变成
anyhow::Error。 - 自动转换:只要错误类型实现了标准库的
Errortrait,就可以自动转换。
使用的简要概述
- 安装依赖(Cargo.toml)
在你的项目 Cargo.toml 里加:
```toml
[dependencies]
anyhow = "1.0"
```
- 最推荐的导入方式:
anyhow::Result
你会经常这样写:
use anyhow::Result;
这个 Result<T> 其实是一个别名:
Result<T> == std::result::Result<T, anyhow::Error>
也就是说:你不用写一堆复杂的错误类型,直接用 anyhow::Error 统一兜底。
anyhow::Result:告别冗长的签名
通常我们需要写 Result<T, MyError>。使用 anyhow 后,你只需要导入它的别名。
```rust,ignore
use anyhow::Result; // 这等同于 Result<T, anyhow::Error>
fn logic() -> Result<()> {
// ...
Ok(())
}
```
注意: 它默认覆盖了标准库的 Result,所以你不需要再写两个泛型参数,只需要写成功时的返回类型即可。
问号操作符 (?) 的魔法
这是 anyhow 最爽的地方。由于 anyhow::Error 实现了 From<E> where E: std::error::Error,所有的底层错误都可以通过 ? 直接向上抛出,并自动完成转换。
对比示例
不使用 anyhow (标准写法):
```rust,ignore
fn run() -> Result<(), Box<dyn std::error::Error>> {
let content = std::fs::read_to_string("config.json")?; // OK
let config: Config = serde_json::from_str(&content)?; // OK
Ok(())
}
// 缺点:Box<dyn Error> 很难添加额外的上下文,且打印出来的效果比较简陋。
```
使用 anyhow:
``rust,ignore
use anyhow::Result;
fn run() -> Result<()> {
// 这里所有的 ? 都会自动把错误包进 anyhow::Error
let content = std::fs::read_to_string("config.json")?;
let config: serde_json::Value = serde_json::from_str(&content)?;
println!("配置加载成功: {:?}", config);
Ok(())
}
``
上下文管理
进入最体现 anyhow 灵魂的部分:上下文(Context)管理。
在 Rust 开发中,最让人头疼的莫过于看到一个孤零零的 Os { code: 2, kind: NotFound, message: "No such file or directory" }。你根本不知道是哪个模块、哪个文件找不到了。anyhow 的 Context 就是为了解决这个问题。
1、什么是上下文(Context)
简单来说,上下文就是给底层错误套上一层“人话”解释。它不会改变原始错误,而是像套娃一样,在原始错误外面包一层说明,告诉调试者:这个操作是在哪一步崩掉的。
要使用这个功能,你需要引入 use anyhow::Context;(注意这是一个 trait,引入后才能在 Result 上调用相关方法)。
2、.context():简单直接的静态说明
如果你只需要添加一段固定的字符串,直接用 .context()。
use anyhow::{Context, Result};
use std::fs;
fn read_config() -> Result<String> {
// 如果文件不存在,原本只报 "No such file..."
// 现在会报 "无法读取系统配置文件" 并带上底层原因
fs::read_to_string("config.toml")
.context("无法读取系统配置文件")
}3、.with_context():支持动态信息的“懒加载”
有时候我们需要在错误信息里加入变量(比如报错的文件名)。这时候要用 .with_context(),它接收一个闭包。
为什么要用闭包? 因为只有在确实发生错误时,闭包里的代码(如字符串拼接)才会执行,这样在程序正常运行阶段不会有性能损耗。
fn load_user_data(user_id: u32) -> Result<String> {
let path = format!("users/{}.json", user_id);
fs::read_to_string(&path)
.with_context(|| format!("加载用户 {} 的数据失败,路径: {}", user_id, path))?
Ok("data".to_string())
}
4、多层上下文与错误链
anyhow 允许你在调用栈里一层层往上加 context。当最终打印错误时,你会看到一个清晰的“因果链条”。
fn main() -> Result<()> {
// 第三层:顶层业务逻辑说明
do_heavy_work().context("任务执行失败,程序即将退出")?;
Ok(())
}
fn do_heavy_work() -> Result<()> {
// 第二层:具体模块逻辑说明
connect_database().context("初始化数据库连接时出错")?;
Ok(())
}
fn connect_database() -> Result<()> {
// 第一层:最底层 IO 错误
std::fs::read_to_string("db_config.toml")?;
Ok(())
}
运行后的报错效果(使用 {:?} 打印):
Error: 任务执行失败,程序即将退出
Caused by:
0: 初始化数据库连接时出错
1: No such file or directory (os error 2)
5、小结:.context() 还是 .with_context()?
| 方法 | 参数类型 | 使用场景 |
|---|---|---|
.context("...") | 字符串/固定信息 | 简单的、不包含动态变量的说明。 |
| **`.with_context( | …)`** |
避坑指南: > 很多新手会写成
.context(format!("...")),这虽然能跑通,但由于format!在成功或失败时都会被执行,会白白浪费 CPU 性能。记住:有变量,用with_context。
核心宏
这一节我们来看看 anyhow 提供的三个核心宏:anyhow!、bail! 和 ensure!。
它们的作用是让你在代码中产生错误时,写起来像 println! 一样爽快。
1、anyhow!:快速创建错误对象
有时候你需要手动创建一个错误,而不是从别的函数传过来。anyhow! 支持字符串格式化,生成的类型是 anyhow::Error。
use anyhow::{anyhow, Result};
fn get_username(id: u32) -> Result<String> {
if id == 404 {
// 创建一个一次性的、没有特定类型的错误
return Err(anyhow!("找不到 ID 为 {} 的用户", id));
}
Ok("Alice".to_string())
}2、bail!:错误处理的“提前离场”
bail! 是 return Err(anyhow!(...)) 的缩写。它是代码中最常用的宏,用于在检测到异常时立即退出当前函数。
对比效果:
- 普通写法:
return Err(anyhow!("权限不足")); - 使用
bail!:bail!("权限不足");
use anyhow::{bail, Result};
fn login(password: &str) -> Result<()> {
if password != "123456" {
bail!("密码错误,登录失败!"); // 简洁明了
}
println!("登录成功");
Ok(())
}3、ensure!:带条件的错误拦截
ensure! 就像是 assert!(断言)的温和版本。
assert!:如果条件不成立,程序直接 Panic(崩溃)。ensure!:如果条件不成立,函数 返回 Err(优雅退出)。
它非常适合用来做输入校验。
use anyhow::{ensure, Result};
fn set_age(age: u8) -> Result<()> {
// 如果 age <= 150 不成立,则返回 Err
ensure!(age <= 150, "年龄 {} 显然不合逻辑", age);
println!("年龄设置为: {}", age);
Ok(())
}4、这三个宏该选哪个?
为了帮你快速决策,可以参考下面这个简单的逻辑流:
- 只是想造个错误传给别人? → 用
anyhow!。 - 遇到错误想直接返回中止函数? → 用
bail!。 - 检查一个条件,如果不满足就返回错误? → 用
ensure!。
5、小结
| 宏 | 类似的标准宏 | 返回值 | 语义 |
|---|---|---|---|
anyhow! | format! | anyhow::Error | 创建一个错误。 |
bail! | panic! | Result<_, Error> | 立即报错退出。 |
ensure! | assert! | Result<_, Error> | 满足条件继续,否则报错。 |
提示: > 所有的宏都支持类似
println!的参数格式化,比如bail!("错误码: {}", code),非常方便。
错误处理库
了解整个生态,能帮你明白为什么 anyhow 会成为现在的“国民级”选择。
在 Rust 的世界里,错误处理库主要分为 “应用派” 和 “库派”,它们共同构建了一个互补的生态系统。
1、生态基石:std::error::Error
所有的错误处理库,本质上都是在围绕标准库的 std::error::Error trait 做文章。
- 过去:你需要手动为每个错误实现
Display、Debug和Error三个 trait。代码极其冗长。 - 现在:生态库通过 过程宏 (Macros) 帮你自动生成这些样板代码,让你只需关注错误本身。
2、四大主流错误处理库
① anyhow(应用级首选)
- 定位:应用程序的“垃圾桶”和“粘合剂”。
- 特点:简单、好上手。它把所有错误都看作一个动态的 trait 对象(
Box<dyn Error>的加强版)。 - 适用场景:你不在乎具体的错误类型,只想要好用的上下文(Context)和快速的错误传播(
?)。
② thiserror(库级标准)
- 定位:结构化错误的“模具”。
- 特点:通过宏自动实现标准 trait,保持了错误的强类型。
- 适用场景:你正在写一个给别人用的库。你需要定义
enum MyError { ... },让你的用户可以用match匹配不同的错误情况。
③ eyre(anyhow 的华丽升级版)
- 定位:极度注重“颜值”和“可定制化”的应用错误处理。
- 特点:它是
anyhow的分支。配合color-eyre,它可以打印出极其漂亮的、带颜色的、带代码片段提示的错误报告。 - 适用场景:你正在写一个对最终用户(User-facing)非常友好的 CLI 工具或复杂应用。
④ miette(极致的报错诊断)
- 定位:像 Rust 编译器报错一样的极致体验。
- 特点:它可以高亮代码行、指出具体的字符位置、甚至给出“修复建议”。
- 适用场景:开发解析器(Parser)、编译器或对错误诊断要求极高的工具。
3、生态库对比一览表
| 库名称 | 解决的核心问题 | 性能开销 | 主要优势 |
|---|---|---|---|
anyhow | 统一管理、快速报错 | 略高(涉及堆分配) | 开发效率极高,API 极简。 |
thiserror | 自动实现繁琐的 Trait | 极低(零开销) | 保持强类型,对下游用户友好。 |
eyre | 更美观的错误报告 | 略高 | 报告更详细(类似编译器的输出)。 |
miette | 完美的报错诊断 | 较高 | 能够精准指出代码中的错误位置。 |
4、协作法则:库用 thiserror,应用用 anyhow/eyre
在 Rust 生态中,最健康的结构如下:
- 基础库 (Base Libs):底层不依赖任何库,或只用
thiserror定义精准的enum。 - 中间件 (Middleware):转发底层错误,使用
thiserror的[from]宏自动转换。 - 最终应用 (Application):通过
anyhow或eyre将所有库的错误汇聚在一起,加上.context(),形成一棵完整的错误树。